
Thoughts on throttling updates
Microsoft recently (in February) published some updates to their documentation regarding Service protection API limits or as they are sometimes referred to, throttling. Some of these, like the new recommendations on how to handle batching are rather interesting and I thought I’d give my 2 cents about this. They are also eluding a bit regarding how the network infrastructure is set up for the deployment and how to optimize when handling larger workloads using the affinity cookie setting. I did find this rather interesting too.
So, first of all, a quick recap for those who arn’t into the throttling and API service limits. There are three different limits set up for Power Platform. You can read the details here: https://docs.microsoft.com/en-us/powerapps/developer/data-platform/api-limits#how-service-protection-api-limits-are-enforced
In short, within a 5 minute sliding window, you cannot exceed the following for one specific user.
- Not more than 6 000 requests.
- Not more than 1 200 (20 minutes) execution time – equal to 4 parallell processes if running at full capacity
- Not more than 52 request at the same time (concurrently).
Generally, if you do not use batching, you would typically run into the first (1) or the third if running unlimited threading. If using a connection pooling with 52 connections, then you probably run into the 1:st, and if you use complex request that cause cascading behaviours or batching, then you typically run into the second (2). There are exceptions that match these. Do refer to the official docs above for details about that.
Now to the interesting part.
There is a new section that is attempting to tells us how to maximize throughput. First of all, I think this is great. We really need this and we need Microsoft to tell us how to not only use the platform, but how to efficiently use their platform.
“Let the server tell you how much it can handle”
This section is interesting as it recommends a rather complex approach to how to work with performance. As they further down recommend using threading, they essentially recommend building logic that dynamically increases and decreases the number of threads as the platform informs you that it has capacity. This brings me back to university math, and trying to figure out the derivative of an unknown function by sampling and finding the local max. I do however, think this is a rather tall order to recommend to your average developer. But it would be a great community tool, so feel free to build it. Consider the challenge set. Best would be if Microsoft included this in the SDK of course.
“Use multiple threads“
In this part they recommend using multiple threads. This is also my experience that this is a good idea as the processing time and latency per package causes certain delay on a per-message basis. By utilizing multi-threading with multiple connections, this overhead can be reduced. As there is a limit of 52 concurrent connections, I would recommend using a maximum of that amount of connections/threads per user.
Avoid batching
Now this is really interesting. The previous recommendation was to use batching to be “nicer” to the API and get increased performance. The recommendation now is the direct opposite. This is based on the fact that the overhead in a WebAPI JSON-message is significantly smaller than that in a SOAP message and that this will reduce the difference between using batching and non-batching. They do, however, recommend using smaller batch sizes still. This is also my experience when working with Kingswaysoft. I typically (it depends on the instance and which table I am using) start with 16 threads with batches of 10 or 20. This has typically given me the best performance, with performance of +300 records/s.
There is also a comment about the fact that the using batching does not bypass the entitlement limits, ie. 20 000 API calls/24 hours for an enterprise user/100 000 API calls for all non-licensed users and so on. See more on the Entitlement limits based on which license you have here. Hence this calculation is done by after exploding the batch on the servers. This is also news to me as I previously was told that batching was exactly the way to go to limit the amount of calls.
Removing the affinity cookie – server multiplexing
The details being eluded to in this section are very interesting. If I understand it correctly, the logic is as follows:
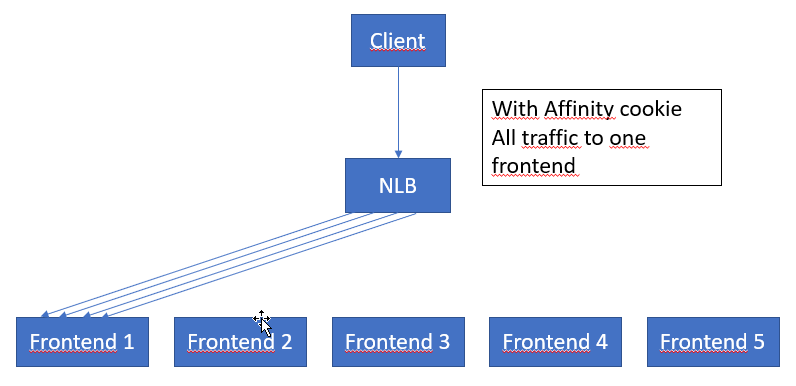
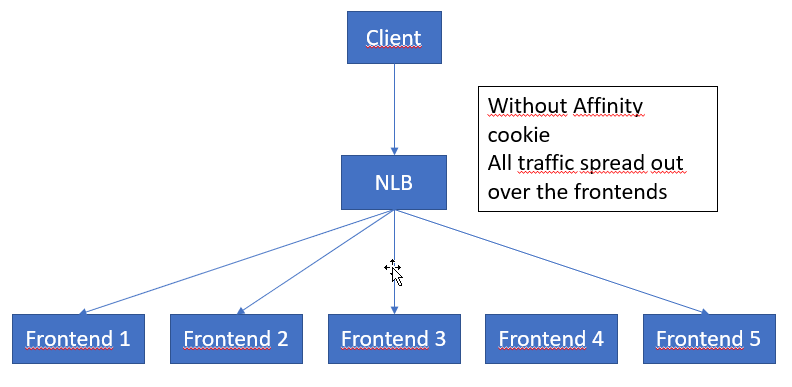
The point being that, shutting off the affinity cookie int the HttpClient will allow for more wider use of all the servers in the node (the entire setup of all the Frontends, backends, NLB etc.)
What I do wonder, is if it would be possible to store the Affinity Cookie, and hence pool it on the client side. As each time you need to hit a new front end you will loose some time while it warms up your instance, and it would hence be advantageous to be able to more tightly control this. Maybe even this could be another community tool for someone interested?
I also think, I havn’t tested this, that you will get better results when working with removed affinity cookie if you do use batching, at least until all the frontends have been warmed up to your instance.
Do also note a very important sentence; “This increases throughput because limits are applied per server“. We do not know how many servers are used in a node frontend, but probably more than 10. Removing the affinity cookie could hence increase performance by at least one order of magnitute.
User multiplexing
As all API limits are calculated on a per-user basis, another way to increase performance is to use what I like to call user multiplexing. This means that operations are done using several different application users at the same time. There is of course some admin work that needs to be done to set these up, and there is no OOB way of doing this but with SSIS and Kingswaysoft it is rather straight forward; just create several connections, one per user, configure them per user and then use the “Balanced Data Distributor” which can be found in the productivity pack to spread the data to different destinations that are using the different connections.
My tips
My tips for getting good performance, for large scale datasets, are hence the following based on these new facts:
- Continue to use batching, but don’t use huge batches. Probably around 5-20 will be ok.
- Use multithreading. I typically use around 16, but that was before I knew about the removal of the affinity cookie. Hence I would recommend 16 per server. But I cannot tell you how many servers there are.
- Use the remove affinity cookie setting, and if possible, figure out some way of pooling the affinity cookies instead.
- Make sure your application can handle the exceptions regarding the API-limit and have some reasonable strategy for working with them. I have found that blasting the API for 5 minutes at max speed, then backing off for 5 minutes, then going full throttle again for 5 minutes, has given me better throughput overall than “being nice” and just finding the “right” speed to use to not be throttled. Not sure this strategy will work in the long run though.
- Use application user multiplexing.
Suggestions to ETL vendors and others
My suggestions to ETL vendors and others who build connections to Dataverse that require high performance are:
- Start by visualizing the affinity cookie setting so that it is possible to set this as wanted.
- Include multithreading, batching and application user multiplexing into the standard dataverse connections.
- Figure out if there are an points to pooling the affinity cookies, and if so, include this into the connection.
- Make the connection auto-optimize with the data it is currently sending. Ie. how many threads, size of batches, size of affinity cookie pool and number of application users to utilize.
- Have different strategies for utilizing application users instead of just spreading the data evenly, it could be that one is used until it receives an exception an then it is put on hold for 5 minutes and then another is being used. Or a combination of these two if there are five application users, 3 might be used for data transfer, and two on hold in case one gets an exception and needs to be put on hold.
I hope this has given you some insights and that my 2 cents got you this far. Feel free to leave a comment if you have an questions!


Recent Comments