Why should a company choose customer insights data? This is a question I often get, especially when talking to people in the analytics department or with that type of background. “We already have customer analytical cubes in our warehouse/lakehouse, why build it again?”. With this article I will try to shed some light on this subject. I short, it is about making the business more versatile, faster to react and enabling use of large amounts of data in a way that is hard otherwise. It also enables advanced AI features that otherwise would take a lot of time to develop and the UI enables people in the business to experiment and try out things to see what works.
Customer Insights Data (CI-D) is Microsofts Customer Data Platform (CDP). CDP:s are a family of software that aggregate and measure customer data. It is in essence a datalake with some spark engines and a UI to control everything. The important thing to understand is that it is meant, not for DBA:s but for people working with customer data in the business. Some people with deeper skills in how to get data into CI-D are needed but once the data is there, measures, segments etc are meant to be created by “business” people.
Why not just use a data warehouse to solve this? Well, technically, the difference isn’t that large if you look at it from a strictly semantic datamodel perspective. However, the difference lies in who is supposed to be using it. Let’s take the scenario when you are in a B2C business trying to sell computers to customers. If the business wants to have a new measure called “Rate of gaming” where the products on the orderline are categorized as “gaming” or “business”. By calculating the number of order lines that are flagged as gaming compared to the total number of orderlines, for each customer, we will get a “rate of gaming”, a % that tells how many orders are gaming related. This can then be used in email marketing to send newsletters with more gaming oriented content.
With a classical data warehouse setup, the marketing department would order the measure to be calculated by registering at ticket in Jira/Azure Devops or similar. It would go into the backlog and then a few sprints (several months) later, it would be delivered. However, if the marketing department now realized that they forgot to limit this to just the orders placed in the last 24 months, then they will have to register a new ticket and wait several more sprints.
Using CI-D they could create the measures themselves (you have to create 3 to solve this), and then, after the next system synchronization, the measures would be there and working, typically around 24h or less, depending on how fast and often system refreshes are done. If they needed to change anything, like changing the filter, it can easily be done and after the next refresh, it would be live.
This is important for many reasons, the most important being that the marketing departments have to change with the world, and sometimes the world changes very fast. In those cases it can be very important to be able to act fast, to retain customers or to be able to exploit a marketing window that has appeared. Enabling this capability is key in the world of today
Why not use just dataverse? Why not just mirror all the data into dataverse and create a few rollups in dataverse? This is technically possible, not really a good idea for the following reasons;
Dataverse capacity is rather expensive. It is an operational database and is supposed to store data that is top be used operationally, not for analytical purposes like a CDP uses data. (with operationally I mean that you work with the data, like working a case in customer service to close it or working with an opportunity to close that)
Dataverse isn’t built to handle really large amounts of data while CI-D is as it is based on Delta lake data storage with Spark engines to do the heavy lifting.
Dataverse doesn’t really have a good way of doing measures. Yes, you can use rollup fields but these are very limited in functionality and you are limited to a few.
Experimentation is also a key way of working for a well functioning marketing department. As someone who like the scientific method being a MSc EE, I like this data driven approach of making hypothesis and trying them out to see what actually works and not. This does, however, require systems that enable the marketing department to experiment and measure outcomes. With experimentation times being weeks with traditional data warehousing and 24 h with CI-D, having CI-D is a true enabler to make a well functioning marketing department that can experiment as they see fit.
Machine learning and using AI in general is also something that is key today. For example CI-D has built in functionality to find similar customers to specific segments. If you start with a segment of all customers who bough gaming products in a computer sales, then, finding other customers that are similar from a data perspectiv who might also be interested in gaming products, can be a very valuable segment to approach with personalized offers.
Exporting selected segments to external systems for activation in these, is also a key functionality in CI-D. This unlocks some of the most low-hanging fruits like not marketing to some groups of people as they would never buy a particular product. With ad banners costing both actual money but also trust from customers when they are irrelevant, this is easy money to save. For instance, not marketing a gaming PC to a customer that just bought a gaming PC despite Google seeing that they visited that gaming PC:s product page.
Using measures and insights from CI-D outside of marketing can also be very powerful. This can be in scenarios like customer service when a customer calls and the customer service rep immediatly sees the total purchasing amount for business IT, consumer IT and gaming IT as well as the time between PC purchases, age of current PC and more. This can help the customer service rep not only be a better help to the customer but also be more relevant in recommendations.
There are many scenarios where CI-D give true value, but it is a bit more of a strategic product than CI-J which is a bit more tactical in giving faster wins. However, the long term wins of using a competent CDP like Dynamics 365 CI-D can be very large and I hope I have made the case for that clear.
Organizations operating under strict privacy, consent, and compliance frameworks—especially in regulated industries like finance, insurance, and healthcare—often need to treat different tracking mechanisms differently.
That’s where a growing limitation in Customer Insights – Journeys becomes clear: today, tracking is largely governed by a single global toggle that controls multiple behaviors at once.
The challenge with “all-or-nothing” tracking
In many real-world compliance setups, the various tracking mechanisms don’t carry the same legal risk or consent requirements. Yet, they’re currently bundled together:
Email open tracking (pixel-based)
Link click tracking
Web tracking
Form prefill
UTM parameter appending
This creates a common compliance trap:
If an organization decides that one mechanism—most often email open tracking via pixels—doesn’t meet its legal interpretation, consent posture, or internal policy, then the only option is to disable tracking broadly. The result? You lose everything, even the parts that are perfectly acceptable and already aligned with policy.
That’s not just inconvenient—it can become operationally blocking.
What should change: independent feature switches per tracking mechanism
A better approach is straightforward: introduce separate switches so administrators can enable/disable each mechanism individually:
Email open tracking (hidden pixel)
Link click tracking
Web tracking
Form prefill
UTM parameter appending
To avoid UI clutter, less frequently used or advanced settings could be managed through OrgDBOrgSettings—keeping the admin experience clean while still enabling expert-level configuration where needed.
Why this matters
1) Compliance flexibility Legal interpretations vary across jurisdictions, industries, and even internal governance policies. Granular controls let organizations implement their consent model—without hacks or unnecessary trade-offs.
2) Risk reduction Disable only what’s considered non-compliant (e.g., pixel-based open tracking) rather than wiping out all measurable engagement signals.
3) Customer trust Consent boundaries become enforceable in a precise way. That reduces the risk of “accidental overreach” and helps maintain credibility with customers and regulators.
4) Operational feasibility Marketing and customer communication teams can continue using permitted tracking mechanisms—without being forced into the dark because one method is not allowed.
The impact on Customer Insights – Journeys
Granular tracking controls would materially strengthen Customer Insights – Journeys as a platform for privacy-sensitive, highly regulated environments. It’s the kind of capability that makes the product more adaptable, more transparent, and more aligned with modern consent expectations.
In short: it lets organizations comply with their specific interpretations of consent while still benefiting from the features that support marketing effectiveness and customer understanding.
The pixel tracking for open emails is also not very usable due to how email clients like Outlook (only downloads images on user approval) and iCloud (always downloads all images) are skewing the statistics. Hence the negative operation impact of disabling this tracking can often be very limited.
Help make it happen: vote for the idea
If you work in an environment where privacy and compliance matter (and that’s increasingly everyone), this is worth supporting.
There are scenarios in CI-D when it is integrated with Dataverse where you may run into a bug with the platform. This is when one of the COLA (Contact, Opportunity, Lead or Account) table records has the lookup Customer Profile pointing at a customer profile that isn’t there any more. In other words an orphan link, something that typically should not exists. I will start by describing a scenario where this can occur, what problems it can cause and how to fix it, both short term by you and long term by Microsoft.
When does it occur?
This problem typically occurs if you have chosen to have more contacts in dataverse than you have in CI-D. The most common reason for this is that each 100k of unified profiles in CI-D incur an non-trivial licensing cost per month. Hence skipping the least valuable customers could be a way to reduce this cost. The problem, on a more technical note, is of course that you will have to filter the customers before they are ingested into CI-D. The new filtering functionality in CI-D that is about to be released will probably help with this.
So, let’s say for the sake of an example that we are only keeping customers in CI-D that placed an order with us during the last 24 months. This means that if you have a customer that yesterday was included, it could pass the threshold and be excluded today. Hence it was synchronized to dataverse yesterday with the rehydration functionality and the corresponding contact record was linked to the customerprofileid with the COLA Backstamping functionality. However, today, when the synchronization happened, this contact is no longer part of the unified profiles and hence is not synchronized to dataverse. However, the COLA backstamping functionality does not clean up after itself properly and hence the customerprofileid lookup on the contact record that was set yesterday, is still set BUT as there is no customer profile that corresponds to this anymore, there is an orphan link.
What problems can it cause?
Let’s say you have an integration that might not as specific in its data processing as is best, and hence it reads all fields from dataverse, changes some and then writes all fields back, instead of just the ones that were changed. If this happens to a record with an orphan lookup link then when you try to save the contact to dataverse, the platform will throw an exception saying that the customerprofileid is incorrect/not pointing at a real record.
How to fix it yourself
The easiest fix you can do is probably to write a Power Automate flow that loops through all contact records and verifies that the customerprofileid is set to something that actually exists.
Another fix is to rebuild the integration so that it only changes fields it actually has a change for. This, does require some extra coding, but that code could be rather generic so that you can use it more. This change will also make your code execute faster. It does, however, not actually fix the problem, just removes the symptom.
For field and table reference, below is a FetchXml that will return the contacts that have the lookup field set and one for all customer profiles. I have tried combining these in an outer left join to get the ones that are incorrectly linked, but there is a limitation in FetchXml that is stopping this.
My suggestions to Microsoft on how they should fix it
There are two different ways to solve this from a Microsoft side, one is on the CI-D integration side and the other on the dataverse elastic table side.
First of all, I think this is an incorrect implementation by the CI-D team. Elastic tables currently do not respect cascade rules like “remove link” and this should be a known fact. Hence they should implement a function that after the backstamping is done for all existing records, it should clean up any customerprofileid:s that do not have a corresponding record.
The second alternative solution is for the dataverse team to implement functionality to respect some of the cascade rules, in essence making sure the dataverse platform cleans up any links to records that do not exist. The positive side of this would be that this fix would help any lookup pointing to an elastic table, as this is most certainly not limited to just the CI-D integration, but the negative side is that this would affect the performance of elastic tables, especially during deletes.
When working in CI-D and replacing a datasource with another, for example replacing Power Query Datasource with Delta, then finding any dependencies for this is important. This is a tip that I got from Microsoft Fast Track Architect Ashwini Puranik, so credit should go to her. You can use the API testing functionality that is part of CI-D to query the ListAllMeasuresMetadata. Keep on reading to get some more details.
As the general recommendation for CI-D is to move to Delta-based data sources from Power Query due to performance. However, doing this shift will require you to reroute all dependencies to the new table before you can remove the data source.
Below is a way to find the dependencies based on Measures and Segments defined in CI-D.
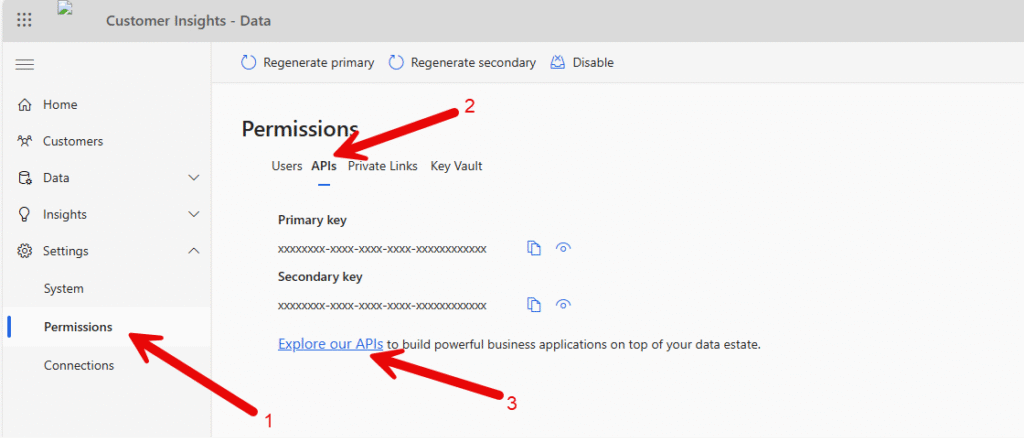
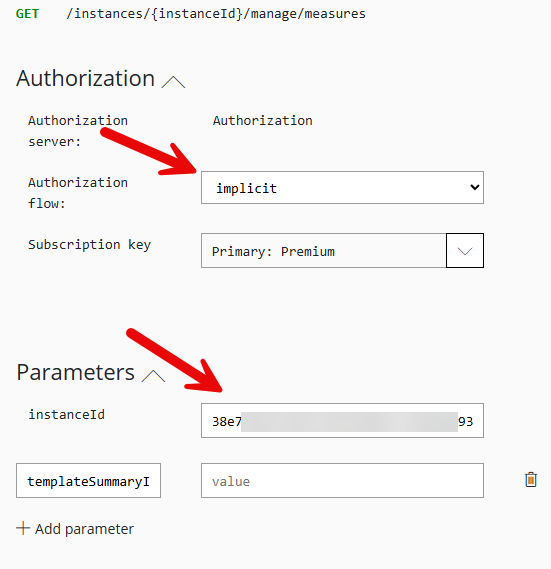
Start by going into the API testing tool that is available for CI-D using the Permissions-area and the tab “API”.
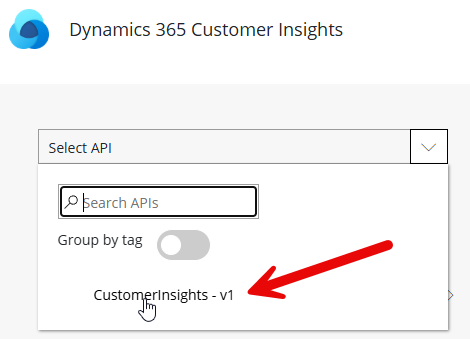
Choose the only available API, Customer insights – v1.
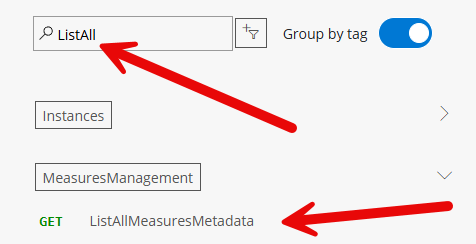
Now search for ListAll and select “ListAllMeasuresMetadata”.
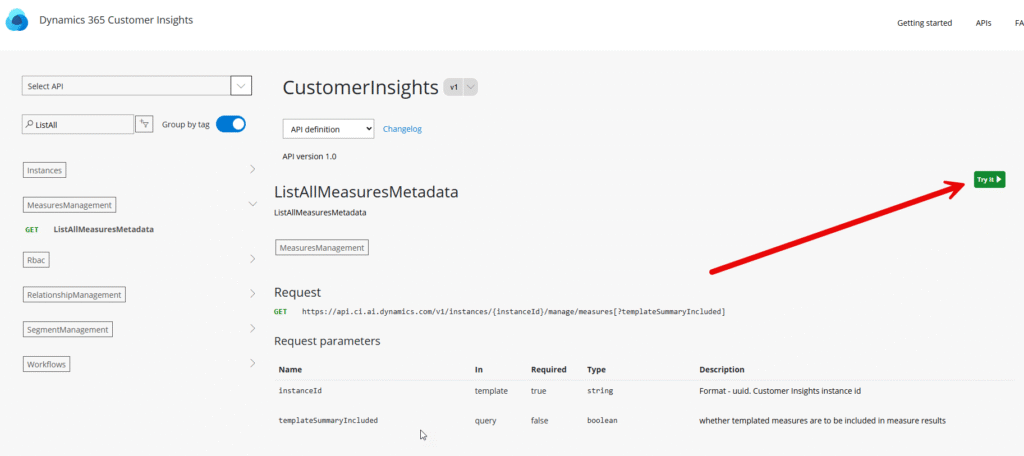
This will show a more detailed description of the endpoint. Now click “Try it!” in the green button on the right hand side.
This will show a panel on the right hand side where you have to input some required data. For an easy test, just select “implicit” in the Authroization drop down and put the instanceid into the field for it. In case you don’t know where to find the instanceid, you can grab it from the URL when you are using CI-D using the normal UI as it is the only guid in the URL.
That is all that is required, so scroll down to the bottom and press “Send”
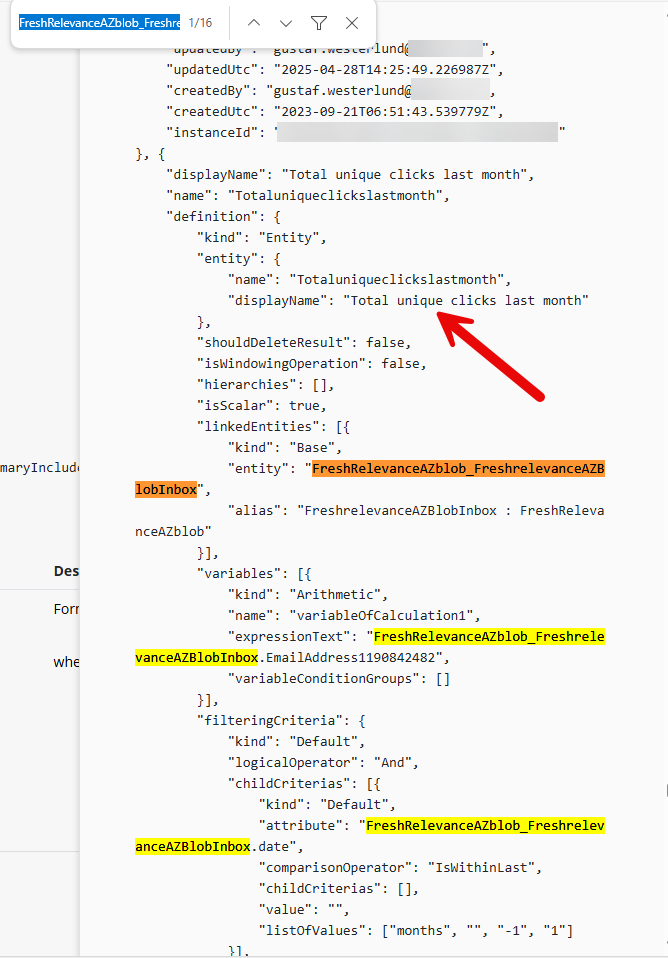
You will now see a long text (json) which is the response from the api call. You can use the built in search in the browser to find all occurances of a datasource. You can use either the Display name or the schema name as both are in the JSON. As you can see below, the Measure “Total unique clicks last month” is one of the measures that has a dependency on the Datasource named “FreshRelevanceAZblob_FreshrelevanceAZBlobInbox”.
Now there are a few options, either remove the measure. This is a good option if you want to fix this quickly or the measure isn’t being used, if it is used there can on the other hand be many dependencies on the measure making it a lot more complex to remove. The other option is hence to just change all dependencies in it to another (Delta) datasource. You will then have to refresh the data source to remove the dependency fully. You can rerun the query by resending it using the button at the very end.
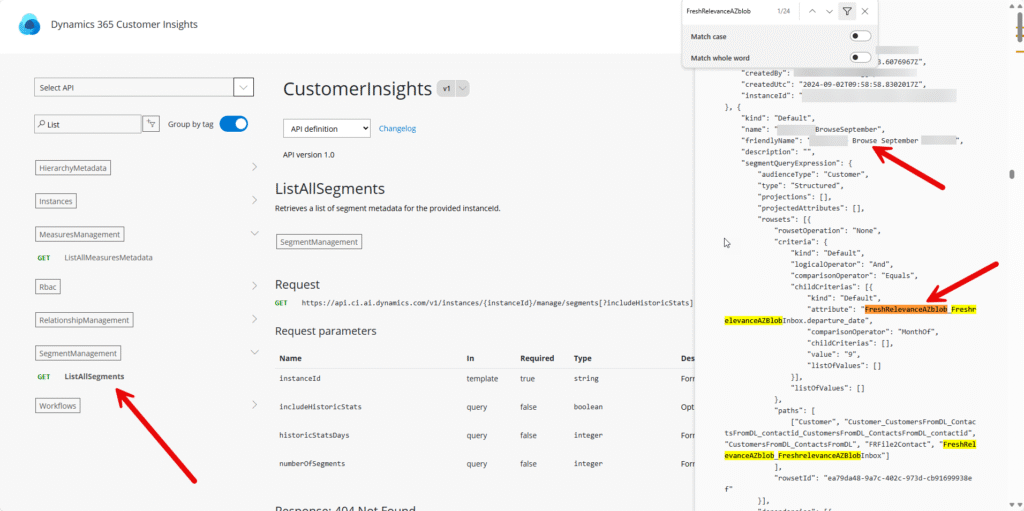
Once you have removed all dependencies on the data source from measures, there might still be dependencies from segments. You can use a similar method as above, but the endpoint you want to use in this case is “ListAllSegments”.
You can still have dependencies left on the datasource, for instance from things externally using the table from the CI-D API. This doesn’t actually block you from removing the data source but whatever you are doing externally will stop working once you have removed the data source. Naturally.
I hope this has helped and thanks a lot to Microsoft Fast Track Architect Ashwini Puranik for pointing me in this direction.
Recently two new features were introduced to dataverse that allows us to better manage customer addresses. A few years ago (2012) I wrote an article on the subject (https://community.dynamics.com/blogs/post/?postid=b889a366-d3fb-4b39-bdb9-7f3716283d4c) which goes into some detail about how the customeraddress table works. This post will revisit some of that and also discuss how the two new features regarding the customeraddress can help us better manage our data.
To make this a bit shorter, the addresses of accounts and contacts are not stored in these tables but actually in a special table called customeraddress. This is hidden to most user operations but it does show up in some cases, for instance in storage calculations in PPAC. The same goes for the lead table which has a special leadaddress table that supports that.
With the default settings, for every account, you will get 2 customer addresses, and for every contact you will get 3 customer addresses. Lead has two addresses and hece will have two records of lead addresses.
This can start becoming an issue if you have lots of these base records, contact, account or leads, which are more or less empty. So even if there is no address data on these records, they will still have these supporting records and all records in dataverse will take up some storage, based on the fact that there are some fields that always are created like modifiedon, createdon, modifiedby etc. Typical scenario where this can start becoming an issue is if you are using dataverse for marketing and you have several million leads to whom you send newsletters but don’t really know that much more about them. With 1 million leads, you will get 2 million empty lead addresses.
So, what is new? The new functionality Microsoft have released are two features. The first feature is that the customeraddress or leadaddress records are not created until there is actually information that needs to be stored in these records. This is generally a good setting to be set to true, as storing more or less empty records isn’t really very useful.
If you have an existing system with 2 million contacts and 4 million leads, this will however not remove the existing customeraddresses (6 million) and leadaddresses (8 million) that are empty. For this, there is the second new feature which allows you to remove customeraddresses without removing the contact/account/lead. There is, of course a workaroud for this, and that is to create a new contact/account/lead with the first feature switched on, hence not creating any address records, and then merging this record with the old one and finally removing the old deactivated records. It is, however, much easier to solve it with just removing the address records.
Before running anything like this, make sure you make a forced backup of your instance. I have seen onprem systems where there are lacking address records and that is just very very weird.
Hope this helps explaing a bit about how this functionality works.
Many organizations, especially banks, insurance companies and other organizations that value trust highly are very careful about how links are formatted in emails that are being sent out. The key is that links need to be “safe” which in essence means they need to have the correct domain. For example company Contoso, this means that the domain needs to end with “contoso.com” and could for instance be “forms.contoso.com” or something similar. However, there is currently no way to create “branded” links in CI-J and this feature was deprioritized and removed from Release wave 2 2024. I (and a some customers of mine) are hoping it will be coming soon. In the meantime, I have been considering what options there are. Here is one, with a simple webpage that just redirects to some other webpage based on some parameters.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Redirecting...</title>
<!--
This webpage will redirect the browser to the url indicated in the query string paramater "url", forward all other query string parameters
and also track the webusage in Dynamics 365 CIJ
Ex. url (file located in c:\temp): file:///C:/temp/redirect.html?url=https%3A//skandia.se¶m1=value1¶m2=value2
-->
<script>
// Function to get query string parameters
function getQueryParam(name) {
const urlParams = new URLSearchParams(window.location.search);
return urlParams.get(name);
}
// Function to get all query string parameters except 'url'
function getOtherQueryParams() {
const urlParams = new URLSearchParams(window.location.search);
let params = [];
urlParams.forEach((value, key) => {
if (key !== 'url') {
params.push(`${key}=${encodeURIComponent(value)}`);
}
});
return params.join('&');
}
// Redirect to the URL specified in the 'url' query parameter
window.onload = function () {
const targetUrl = getQueryParam('url');
if (targetUrl) {
// Basic validation to ensure it's a valid URL
try {
const validatedUrl = new URL(targetUrl);
// Get other query parameters and append them to the target URL
const otherParams = getOtherQueryParams();
if (otherParams) {
validatedUrl.search = validatedUrl.search ? validatedUrl.search + '&' + otherParams : '?' + otherParams;
}
// Perform the redirect
window.location.href = validatedUrl.href;
} catch (e) {
console.error('Invalid URL:', targetUrl);
document.body.innerHTML = '<h1>Invalid URL</h1><p>Please provide a valid URL as a query parameter.</p>';
}
} else {
document.body.innerHTML = '<h1>No URL Provided</h1><p>Add a "url" query parameter to redirect.</p>';
}
}
</script>
</head>
<body>
<p>Redirecting...</p>
</body>
</html>
The code simply parses the parameter url and redirects to this url including all other query string parameters. This is important as that will maintain any UTM tags that were added.
The point is hence to place this webpage on any page internally at the company, for ex. https://contoso.com/redirect.html and then call it with the parameters indicated like https://contoso.com/redirect.html?url=https%3A//crmkonsulterna.se¶m1=value1¶m2=value2
In CI-J this means that you either manually have to assemble these url:s or create some function, preferably connected to the ribbon to easier be able to add this redirect url to the email.
Tracking
As we need to make sure that the URL is not using the built in tracking in CI-J, using the normal button functionality of “Tracking” needs to be switched off, as the tracking functionality uses Microsoft redirect pages and hence break the typical “no link outside our domains”-policy.
We do need to track anyway and there are two ways that I can see that off the top of my head will achieve this:
Using webtracking
Using custom triggers
Webtracking is, at the time of writing this article, a preview functionality, and we might hence be a bit hesitant in trying it out. If you want to, there is a setting switch for it under settings in CI-J. Then reload the page and click on “Web tracking” to get the correct script.
Custom triggers has been around a while and is probably easier to use. Create a custom trigger and get the code snippet for it and add it to the redirect-page. Every time someone hits the redirect page the custom trigger will be called. When using triggers, I would recommend using parameters to forward all relevant data to the journey where you want it.
I hope this helps you or gives you inspiration on how to do something similar!




Recent Comments