
Incorrect API Optimization recommendations by Microsoft
On the page in Microsoft docs where they discuss API Service Protections there is towards the end of the page a part which gives some recommendations. Some are great, like the recommendation to use many threads and remove the affinity cookie, however when I read it I really bounced at the recommendation that batching shouldn’t be used. That just didn’t rime with my experiences of doing heavy dataloads to dataverse. So I thought I might just test to see if it was true or not by creating a simple script in SSIS with Kingswaysoft. My results, using batching compared to not using it gives more than a 10x performance increase. Continue reading to understand more about how I tested this and some deeper analysis.
Parameters and excel
The first thing I did was to create an excel sheet for storing all the results. I really did have to think about the different parameters that could affect the result, so I chose the following columns:
Dataload – how many records. This needed to be a bit larger to make sure that the throttling time of 5 min was passed.
Operation – Different dataverse operation take different amounts of time. For instance, creates are typically rather fast, but deletes, depending on table, can be a lot slower as the platform might execute cascading deletes based on one single delete. For instance, if you remove a contact with 100 tasks connected to it with the regarding relation set to “parental” or “cascade delete” it will actually remove all the 100 tasks. If set to “remove link”, the platform has to make an update to each of the tasks, removing the link. There are also special operations like merge which are rather complex.
Table – There is a large difference between the different tables. Some of the OOB tables have a lot of built in logic and really small non-activity custom tables can be a lot quicker to create, update or delete.
Threads – How many threads were used.
Batch – The size of the batches being used.
Duration / Duration (ms) – Duration is where I input the duration as a normal time. I created a calculation to calculate the corresponding amount of milliseconds.
Time per record (ms) – This is the division of the duration in ms with the total number of records. During this first test, I always used 100 000 records as the dataload, but it could be interesting in the future to see the differences between different dataloads, with all else being the same. This is also the main output from this test.
Strategy – It is possible to have different strategies. In this first version I just ran everything at once, hence I called the strategy “All at once”. Different strategies might be “5 on, 5 off”, meaning that you design the script to run superfast for 5 minutes, the throttling limit, and then stop and do nothing for 5 minutes and then loop this. Not always possible to use that kind of strategy, but for massive deletes of for instance market list members (cannot be removed with bulk delete) that might be an option.
API – There are currently two APIs that can be used. The new WebAPI which uses JSON payloads and the older SOAP API which used XML payloads. It stands to reason that the smaller JSON payload should cause the WebAPI to be faster than the corresponding SOAP API. However SSL encryption also causes the data to be compressed, which might make these differences smaller than expected. There is also a server side aspect to this, as the APIs will run through different parts of the code on the server side which could affect the performance.
No of columns – How many columns are being sent to the API. Of course there would be a difference if you send a create message with 3 columns compared to 30. Hence this is a relevant point. It is still a bit rough, as there is a huge difference in creating a boolean record, a 2000 character nvarchar or a lookup. This could also be something that was adapted.
Existing records – How many records existed in the system prior to running this? Not sure if this makes any difference, in other words, everything else equal, would it take more time to write 100k records to a system with 0 records or one with 10M records? As I don’t know, and cannot rule it out, I added it.
Latency (ms) – Daniel Cai, Founder of Kingswaysoft, always recommend that the SSIS script with Kingswaysoft be run “as close as possible to the dataverse”. That does in other words imply that the latency to the server affect the performance. Do calculate this, I used diag.aspx from the computer running the script.
Location – Which geo is the instance located in. This is more for general information, the latency is really the important factor here. The throughput might also have some affect if you are using a really bad line to the dataverse. I was using a wired 1 GBit line. In this test, I was using an instance I got hold of as MVP, which is located in the US and my own stationary computer at home (a AMD Ryzen 9 3900X 12-Core Processor 3.79 GHz with 32 GB of memory). Hence the latency was rather high and not in line with Daniel Cai’s recommendations. It is hence also something to investigate further.
No of users – As I, and some others in the community have described, throttling is based on a per-user and per-front end server basis. Hence utilizing several service principals/application users can effectivly multiply the throughput. In this test I used just one.
Instance type – It is well known that sandbox instances do not have the same performance as a production instance. If you find Microsoft support on a happy day and you are working with a larger (no of licenses) instance, you might also get them to relax the throttles a bit, especially if you mention that you are doing a migration. As these factors strongly affect the performance of large dataloads, I did have to add this. During this test I was using a non-enhanced production instance, in other words, a production instance on which no throttles had been relaxed.
DB Version – The final parameter that I thought might affect this is the actual version of the dataverse instance. As improvements and god forbidd sub optimal “improvements”, can cause enhancements or degradations of the performance, this is necessary to document.
SSIS/Kingswaysoft setup
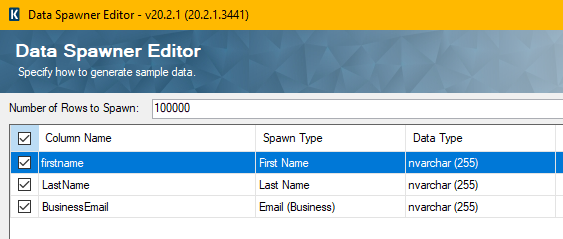
For setup of create tests in SSIS with the Kingswaysoft addons I used a dataspawner (productivity pack) to generate the data. I then just sent this directly to the CDS Destination.
And the CDS Destination config
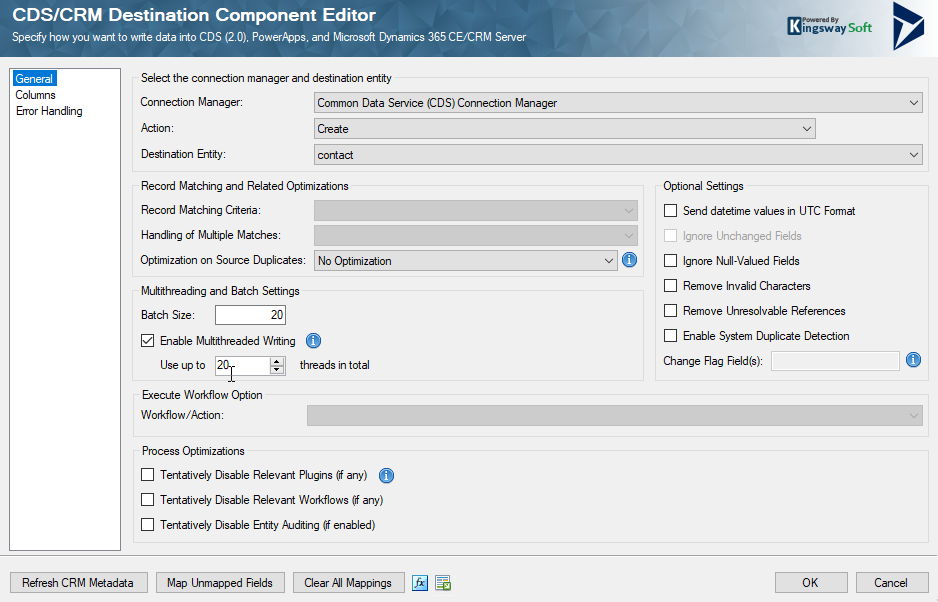
After each run, I checked the log from SSIS to see how long the entire process took. Due to the fact that I have a computer with many threads and for this case, enough memory, it is my perception that most of the threads allocated were also used.
Results
What are the results? This is a picture of the excel:

As you can see I did try both Create and Delete operations, but the results are rather obvious.
- 20 threads/20 per batch of both create and delete, took around 45 minutes
- Reducing to 16/10 made only a minor difference – 48 minutes
- Microsofts recommendation of not using batching, ie 20 threads/1 batch – took over 10 h, both for delete and create.
- Using only 1 thread with 1 batch was more or less the same as using 20/1
- 1 thread with 20 in every batch (1/20) took almost 5 h, which is around half the 1/1 or 20/1
I think the results clearly show, that Microsoft docs are currently incorrect in their recommendation to not use batching. Perhaps they will update this soon. From an entitlement perspective, one needs to understand the additional cost of the “batch unpacking” request that is made. With 20 in every batch, this is an overhead of 1/21 but if you would lower the batches to 4, it would be 1/5. Hence using as large batch as you can, without loosing performance, is generally what I would recommend.
As I have implied in this article, there are a lot of other parameters to investigate in the API. I have a hunch that a create with 10 lookups compared to 10 textfields, will also make a significant difference, but I will need to test it.
Also do consider the request timeout. When working with complex and large batches, one request may taker quite some time. You will know, however, as it will return a timeout exception if you exceed it. Note that some records in that batch may have been written anyway. Just that your client wasn’t waiting around for the answer.
I do also encourage others to try out other parameters in the API. What is really optimal from many different aspects. From a mathematical perspective this can really be seen as a multidimentional surface where we are attempting to find the highest points. I have now started this journey, and I hope it was an interesting read. Please leave a comment, if you have any experience to share or just want to comment.
Recent Comments