In a previous post I blogged about how to break down the Form script that was exported from CI-J (Real Time). As some customers asked me about making this into a script that was the same and was dynamic based on query string parameters (parameters in the URL), I worked a bit on that and thought I’d share it here;
A few things that can be mentioned. This script expects that there will be two query string parameters: id – the id of the form. Click on the form and copy it from the URL after the “id=” orgid = the orgid which you can find in the PPAC or in the export of the script as I described in the previous article. If it is placed on the url: https://contoso.com/form.html then an example of the url would be:
Finally some organizations also have problems with loading a script from external sources. I will look at that too. Mainly there are two option. Copy-paste the entire script inline into this script or copy the script file to an “internal” or recognized store with a public URL and change the src-attribute. If you move this away from referencing Microsoft, I would recommend checking their website on a regular basis to make sure it hasn’t changed.
When creating a form in Customer Insight Journeys (real time) one option is to embedd it in an existing page. A customer asked me if it was possible to get this script from the API some how. Turns out that you don’t have to. It has a logical build-up and you can generate it yourself with a script.
First of all, let’s have a look at the generated script;
I have highlighted two different guids (I have changed them so they are not the actual guids).
The first one; 2e2b50a9-0000-0000-9079-0022489ca998 this is the Form id. It is the exact Id of the form that you have created. Easy to confirm by checking the id-parameter in the querystring for the form. This can easily be queried from the WebAPI from the table msdynmkt_marketingform.
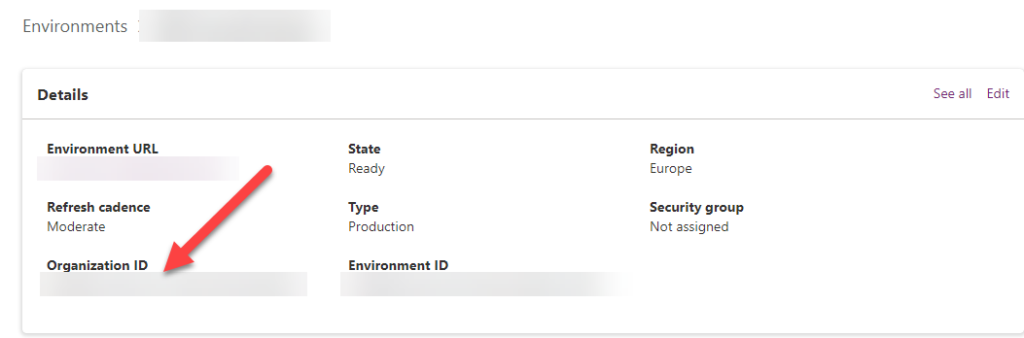
Second guid; 4e5c8ea2-0000-0000-ac66-a30471bdf4fa is the instance id of the dataverse instance. This can be found in the Power Platform Admin Center under “Organization Id”. This is hence the same for all forms that are from the same instance.
The rest of the script is the same. Hence you can generate this quite simply with a script if you have these two values. I don’t know if the library referenced might risk being changed during updates or similar. Hence I would recommend using it with the same reference as seen above, but it might also be possible to download it and host it yourself. This is not something I have tried.
A colleague of mine, Thomas Passad, also mentioned that some CMS:s, like Optimizly, cannot handle the script being reference directly and that it had to be placed in some general footer or similar.
With this knowledge I think it is possible for you to handle this script in a more dynamic fashion but make sure to check that it hasn’t changed every month or so, as it might cause issues if there is a change and you havn’t taken that into consideration.
Working on a new environment recently I had to remove a few tables. However, after removing all normal dependencies, it complained finally about a dependency to the table: entityanalyticsconfig. Never heard about it. After some googling on Microsoft Learn I found that it is about the sync to datalake, which was funny as we hadn’t set up any sync. I think it might be the new Microsoft Fabric sync from Dataverse that might be causing this. It might be switched on by default in the case that you have change tracking switched on.
Also I couldn’t find it in advanced find (the old or new one) but with https://fetchxmlbuilder.com/ in XrmToolBox I was able to find it and also the rows that were associated with it. So, I created FetchXml for these specific rows, used the tool Bulk Delete Tool (no not Bulk Delete Manager, which I made) by Andy Popkin and simply ran the delete for these specific rows. This allowed me to remove the dependency and then remove the tables.
I have recently been working with a customer with a large (500+ GB dataverse db) production instance and we are attempting to cut this down quite a lot. The natural way of doing this is bulk delete but it seems that if the underlying SQL isn’t up to speed, your jobs might end without actually being done.
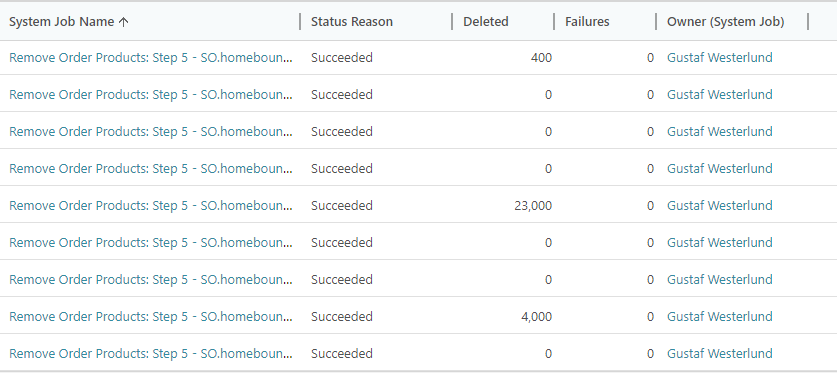
My customer has a production instance of over 500GB which is costing them some substantial money and hence we started looking at removing some of the less necessary data. In this case it was the order products (salesorderdetail) which we have perceived that we do not need more than one year after delivery. Hence we set up an advanced find, agreed on the exact filters, saved the view and then tried to remove the records (well over 5M) using bulk delete. I restarted it several times. You can see the chronological results in the screenshot below:
As you can see, sometimes it actually deleted a few records, but most times, it didn’t. My professional analysis of this (=guess) is that this is caused by bulk delete not handling exceptions like SQL Timeout properly or that it has a limit on the number of times it will retry.
I also, in parallell tried to remove the same records with the same FetchXML using SSIS/Kingswaysoft and here I have several times gotten this error. I have had to turn down the knobs to a very low setting to get it to work, but the error message I did get was:
(Status Reason: ServiceUnavailable): The remote server returned an error: (503) Server Unavailable.”.
As you can see, there is a lot of noise but it clearly, in the highlighted part, say that there is a SQL Timeout.
Hence my takeaway from this is that you need to be a bit wary of bulk delete in large instances or in general as it might indicate that it has completed successfully but in fact it stopped due to SQL Timeout (or some other platform related issue).
On a personal note, I really hope the bulk delete functionality gets a modernized revamp soon. It is really old and is becoming more and more relevant.
I was recently helping my colleague Ebba Linnea Nilsson with a support ticket with data not being propagated correctly from dataverse to a datalake via Azure Synapse Link. It turned out that this was all by design. A design that might not be what normal users would expect.
Calculated columns and now recently the formula columns are both very useful way of being able to calculate data in a field that is based on other fields. Common scenarios are calculations like “Weighted revenue” which is the probability multiplied by the estimated revenue for an opportunity. However, there are scenarios where you need to be aware of how these fields actually work or you might get an unwanted or unexpected behaviour.
The first thing that needs to be understood is that these column types are calculated “on-the-fly” everytime dataverse attemts to access these columns. It might seem like the data is “in the columns” but it really isn’t, it is calculated. This is a big difference from for instance rollup-columns is that those columns are calculated on a regular interval by the system, and the result is stored in the record.
What does this mean for Azure Synapse Link? Well, let’s say we have a simple calculation, that sets the value “A” into all records for this calculated column. We then enable the Azure Synapse Link which will make an initial sync and set the column in the datalake to “A”. Now we change the calculation of the rule to output “B” instead. As no records are actually changed, this will not cause any records in the datalake to be updated, hence they will all still have the value “A”. From a user perspective comparing Dynamics 365 to the datalake without any underlying understanding of how this functions, it will look like an error. Same column has different values comparing what is in dataverse with what is in the datalake.
As soon as a record is actually changed, all columns for that record will then be sent to the datalake, and hence the calculated column will be set to “B” at that time. It is hence possible, to manually or semimanually force a resync, but it would require some bulk like for instance SSIS with Kingswaysoft especially for implementations with large amounts of records.
An important question to ask, is why would you want to calculate the data in dataverse and then use it in in the datalake. If you have a propper datalake architecture it should be easier to make calculated columns/fields in the datalake/datalakehouse. If the data is calculated only for use in the datalake, I would suggest moving the calculation to the datalake.
There are, of course, scenarios when it is preferrable to have calculations in one place and reuse the output in many places. However, this understanding of what can reasonably be expected is then essential.
As for product improvements, I have added an idea on the subject, if you agree with me, please vote! Microsoft Idea (dynamics.com)
A final note is that this type of unexpected behaviour is not limited to just Azure Synapse Link but really to any integrations based on either “modified on” or change tracking without doing periodic synchronizations. Hence I would also like to give a general warning about this.
Recently I needed to get the marketing insight replicated data from the data lake where it is replicated to, to Customer Insight. However, that turned out to not be very easy as the data had some formatting issues. However, I found that the Marketing reports that Microsoft have release for Power BI can be used as inspiration for how to query the data.
I am currently working on a rather long Proof of concept of Customer Insight for a customers. One of the things they wanted to see if it worked to get into Customer Insight was EmailClicked which is part of the Marketing Insight data that Marketing stores in an internal database. This can rather easily be replicated to an external datalake, with some configuration in the admin tab in Marketing. However, when I tried to connect to that data, using the Azure Datalake gen2 adapter in Customer Insight, it consistently said that there was no data. After some digging I found that the main reason for this was that the files in the datalake did not have the propper file-ending for the datalake connector to understand them. In short, they are csv-files, but do not have the filename xyz.csv. Simple enought problem, I thought but as I am not super comfortable working with datalake data, I tried to figure out some way of easier solving this issue. First I tried using the dataflow connector to ADLS gen 2 but that got the same problem. Just so you know.
Then it struck me, data flows use PowerQuery/M which is the same thing that is used in Power BI, AND Microsoft have release some marketing reports for Power BI that utilize the data in the datalake combined with dataverse. I hence opened one of these and tried to copy the entire data query part. It turned out to be more than 20 different components. Datasources, configuration, functions and more. When pasted into the Data Flow, it simply didn’t work and as usual, I didn’t get a very good errormessage. But my hunch was that maybe the logic is too complicated with too many internal connections for the data flow. If you know the limitations here, please leave a comment. This didn’t stop me, my next step was to remove all unnecessary stuff from it, like the dataverse queries, config and such, but still, it didn’t work. So I attempted to move it all into one single M-script with a hardcoded referece to EmailClicked. When I did that, it worked! This is the final result:
let
Source = AzureStorage.Blobs("<datalakename>"),
#"ContainerContent" = Source{[Name="<containername>"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(ContainerContent,{"Content", "Name", "Date modified", "Attributes"}),
#"Filtered Rows" = Table.SelectRows(#"Removed Other Columns", each [Name] <> "model.json"),
#"Sorted Rows" = Table.Sort(#"Filtered Rows",{{"Date modified", Order.Descending}}),
#"Expanded Attributes" = Table.ExpandRecordColumn(#"Sorted Rows", "Attributes", {"Size"}, {"Size"}),
#"File Name column" = Table.DuplicateColumn(#"Expanded Attributes", "Name", "File Name"),
#"Remove csv" = Table.ReplaceValue(#"File Name column","csv/","",Replacer.ReplaceText,{"File Name"}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Remove csv", "File Name", Splitter.SplitTextByEachDelimiter({"/"}, QuoteStyle.Csv, true), {"Interaction Name", "File Name"}),
#"Transform" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"Interaction Name", type text}, {"File Name", type text}, {"Size", Int64.Type}}),
#"Add Datestamp" = Table.DuplicateColumn(#"Transform", "Date modified", "Datestamp"),
#"DateStampFormat" = Table.TransformColumnTypes(#"Add Datestamp",{{"Datestamp", type date}}),
TodayFunction = DateTime.FixedLocalNow,
#"Add Today" = Table.AddColumn(#"DateStampFormat", "Today", each TodayFunction()),
#"Changed TodayType" = Table.TransformColumnTypes(#"Add Today",{{"Today", type date}}),
#"Add DaysFromToday" = Table.AddColumn(#"Changed TodayType", "DaysFromToday", each [Datestamp]-[Today]),
#"Changed DaysFromToday" = Table.TransformColumnTypes(#"Add DaysFromToday",{{"DaysFromToday", Int64.Type}}),
Result = Table.RemoveColumns(#"Changed DaysFromToday", "Today"),
result2 = Table.SelectRows(Result, each [DaysFromToday] >= -180),
FilteredByInteraction = Table.SelectRows(result2, each [Interaction Name] = "EmailClicked"),
#"AddFileContents" = Table.AddColumn(#"FilteredByInteraction", "FileContent", each
Table.PromoteHeaders(Csv.Document([Content],[Delimiter=",", Encoding=1252, QuoteStyle=QuoteStyle.Csv]), [PromoteAllScalars=true])),
#"ContentTable" = Table.SelectColumns(AddFileContents,{"FileContent"}),
#"NoDataFiles" = Table.IsEmpty(#"ContentTable"),
InteractionTable = Table.ExpandTableColumn(#"ContentTable", "FileContent", Table.ColumnNames(ContentTable{0}[FileContent])),
#"Transformed" = Table.TransformColumnTypes(InteractionTable,{{"Timestamp", type datetimezone}}, "en-US"),
#"Duplicated Column" = Table.DuplicateColumn(#"Transformed", "Timestamp", "Datestamp"),
#"Datestamp" = Table.TransformColumns(#"Duplicated Column",{{"Datestamp", DateTime.Date, type date}}),
#"RenameId" = Table.RenameColumns(#"Datestamp",{{"InternalMarketingInteractionId", "Id"}}),
#"keyedtable" = Table.AddKey(#"RenameId", {"Id"}, true)
in
#"keyedtable"
I have highlighted the datalake name, container and the table. I hope this helps if you are having a similar issue!





Recent Comments