Working on a new environment recently I had to remove a few tables. However, after removing all normal dependencies, it complained finally about a dependency to the table: entityanalyticsconfig. Never heard about it. After some googling on Microsoft Learn I found that it is about the sync to datalake, which was funny as we hadn’t set up any sync. I think it might be the new Microsoft Fabric sync from Dataverse that might be causing this. It might be switched on by default in the case that you have change tracking switched on.
Also I couldn’t find it in advanced find (the old or new one) but with https://fetchxmlbuilder.com/ in XrmToolBox I was able to find it and also the rows that were associated with it. So, I created FetchXml for these specific rows, used the tool Bulk Delete Tool (no not Bulk Delete Manager, which I made) by Andy Popkin and simply ran the delete for these specific rows. This allowed me to remove the dependency and then remove the tables.
I have recently been working with a customer with a large (500+ GB dataverse db) production instance and we are attempting to cut this down quite a lot. The natural way of doing this is bulk delete but it seems that if the underlying SQL isn’t up to speed, your jobs might end without actually being done.
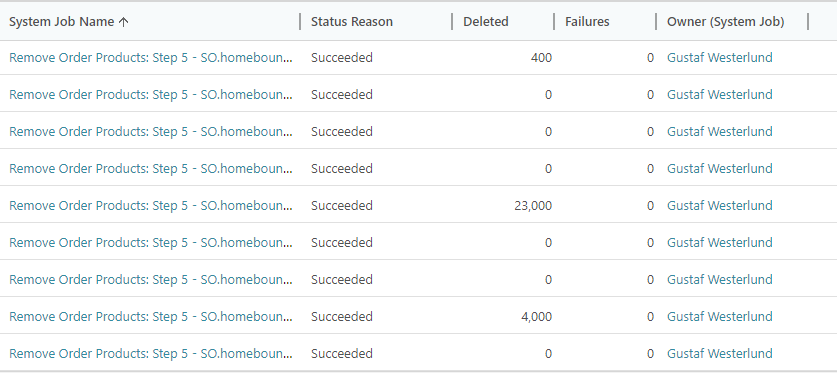
My customer has a production instance of over 500GB which is costing them some substantial money and hence we started looking at removing some of the less necessary data. In this case it was the order products (salesorderdetail) which we have perceived that we do not need more than one year after delivery. Hence we set up an advanced find, agreed on the exact filters, saved the view and then tried to remove the records (well over 5M) using bulk delete. I restarted it several times. You can see the chronological results in the screenshot below:
As you can see, sometimes it actually deleted a few records, but most times, it didn’t. My professional analysis of this (=guess) is that this is caused by bulk delete not handling exceptions like SQL Timeout properly or that it has a limit on the number of times it will retry.
I also, in parallell tried to remove the same records with the same FetchXML using SSIS/Kingswaysoft and here I have several times gotten this error. I have had to turn down the knobs to a very low setting to get it to work, but the error message I did get was:
(Status Reason: ServiceUnavailable): The remote server returned an error: (503) Server Unavailable.”.
As you can see, there is a lot of noise but it clearly, in the highlighted part, say that there is a SQL Timeout.
Hence my takeaway from this is that you need to be a bit wary of bulk delete in large instances or in general as it might indicate that it has completed successfully but in fact it stopped due to SQL Timeout (or some other platform related issue).
On a personal note, I really hope the bulk delete functionality gets a modernized revamp soon. It is really old and is becoming more and more relevant.
I was recently helping my colleague Ebba Linnea Nilsson with a support ticket with data not being propagated correctly from dataverse to a datalake via Azure Synapse Link. It turned out that this was all by design. A design that might not be what normal users would expect.
Calculated columns and now recently the formula columns are both very useful way of being able to calculate data in a field that is based on other fields. Common scenarios are calculations like “Weighted revenue” which is the probability multiplied by the estimated revenue for an opportunity. However, there are scenarios where you need to be aware of how these fields actually work or you might get an unwanted or unexpected behaviour.
The first thing that needs to be understood is that these column types are calculated “on-the-fly” everytime dataverse attemts to access these columns. It might seem like the data is “in the columns” but it really isn’t, it is calculated. This is a big difference from for instance rollup-columns is that those columns are calculated on a regular interval by the system, and the result is stored in the record.
What does this mean for Azure Synapse Link? Well, let’s say we have a simple calculation, that sets the value “A” into all records for this calculated column. We then enable the Azure Synapse Link which will make an initial sync and set the column in the datalake to “A”. Now we change the calculation of the rule to output “B” instead. As no records are actually changed, this will not cause any records in the datalake to be updated, hence they will all still have the value “A”. From a user perspective comparing Dynamics 365 to the datalake without any underlying understanding of how this functions, it will look like an error. Same column has different values comparing what is in dataverse with what is in the datalake.
As soon as a record is actually changed, all columns for that record will then be sent to the datalake, and hence the calculated column will be set to “B” at that time. It is hence possible, to manually or semimanually force a resync, but it would require some bulk like for instance SSIS with Kingswaysoft especially for implementations with large amounts of records.
An important question to ask, is why would you want to calculate the data in dataverse and then use it in in the datalake. If you have a propper datalake architecture it should be easier to make calculated columns/fields in the datalake/datalakehouse. If the data is calculated only for use in the datalake, I would suggest moving the calculation to the datalake.
There are, of course, scenarios when it is preferrable to have calculations in one place and reuse the output in many places. However, this understanding of what can reasonably be expected is then essential.
As for product improvements, I have added an idea on the subject, if you agree with me, please vote! Microsoft Idea (dynamics.com)
A final note is that this type of unexpected behaviour is not limited to just Azure Synapse Link but really to any integrations based on either “modified on” or change tracking without doing periodic synchronizations. Hence I would also like to give a general warning about this.
Recently I needed to get the marketing insight replicated data from the data lake where it is replicated to, to Customer Insight. However, that turned out to not be very easy as the data had some formatting issues. However, I found that the Marketing reports that Microsoft have release for Power BI can be used as inspiration for how to query the data.
I am currently working on a rather long Proof of concept of Customer Insight for a customers. One of the things they wanted to see if it worked to get into Customer Insight was EmailClicked which is part of the Marketing Insight data that Marketing stores in an internal database. This can rather easily be replicated to an external datalake, with some configuration in the admin tab in Marketing. However, when I tried to connect to that data, using the Azure Datalake gen2 adapter in Customer Insight, it consistently said that there was no data. After some digging I found that the main reason for this was that the files in the datalake did not have the propper file-ending for the datalake connector to understand them. In short, they are csv-files, but do not have the filename xyz.csv. Simple enought problem, I thought but as I am not super comfortable working with datalake data, I tried to figure out some way of easier solving this issue. First I tried using the dataflow connector to ADLS gen 2 but that got the same problem. Just so you know.
Then it struck me, data flows use PowerQuery/M which is the same thing that is used in Power BI, AND Microsoft have release some marketing reports for Power BI that utilize the data in the datalake combined with dataverse. I hence opened one of these and tried to copy the entire data query part. It turned out to be more than 20 different components. Datasources, configuration, functions and more. When pasted into the Data Flow, it simply didn’t work and as usual, I didn’t get a very good errormessage. But my hunch was that maybe the logic is too complicated with too many internal connections for the data flow. If you know the limitations here, please leave a comment. This didn’t stop me, my next step was to remove all unnecessary stuff from it, like the dataverse queries, config and such, but still, it didn’t work. So I attempted to move it all into one single M-script with a hardcoded referece to EmailClicked. When I did that, it worked! This is the final result:
let
Source = AzureStorage.Blobs("<datalakename>"),
#"ContainerContent" = Source{[Name="<containername>"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(ContainerContent,{"Content", "Name", "Date modified", "Attributes"}),
#"Filtered Rows" = Table.SelectRows(#"Removed Other Columns", each [Name] <> "model.json"),
#"Sorted Rows" = Table.Sort(#"Filtered Rows",{{"Date modified", Order.Descending}}),
#"Expanded Attributes" = Table.ExpandRecordColumn(#"Sorted Rows", "Attributes", {"Size"}, {"Size"}),
#"File Name column" = Table.DuplicateColumn(#"Expanded Attributes", "Name", "File Name"),
#"Remove csv" = Table.ReplaceValue(#"File Name column","csv/","",Replacer.ReplaceText,{"File Name"}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Remove csv", "File Name", Splitter.SplitTextByEachDelimiter({"/"}, QuoteStyle.Csv, true), {"Interaction Name", "File Name"}),
#"Transform" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"Interaction Name", type text}, {"File Name", type text}, {"Size", Int64.Type}}),
#"Add Datestamp" = Table.DuplicateColumn(#"Transform", "Date modified", "Datestamp"),
#"DateStampFormat" = Table.TransformColumnTypes(#"Add Datestamp",{{"Datestamp", type date}}),
TodayFunction = DateTime.FixedLocalNow,
#"Add Today" = Table.AddColumn(#"DateStampFormat", "Today", each TodayFunction()),
#"Changed TodayType" = Table.TransformColumnTypes(#"Add Today",{{"Today", type date}}),
#"Add DaysFromToday" = Table.AddColumn(#"Changed TodayType", "DaysFromToday", each [Datestamp]-[Today]),
#"Changed DaysFromToday" = Table.TransformColumnTypes(#"Add DaysFromToday",{{"DaysFromToday", Int64.Type}}),
Result = Table.RemoveColumns(#"Changed DaysFromToday", "Today"),
result2 = Table.SelectRows(Result, each [DaysFromToday] >= -180),
FilteredByInteraction = Table.SelectRows(result2, each [Interaction Name] = "EmailClicked"),
#"AddFileContents" = Table.AddColumn(#"FilteredByInteraction", "FileContent", each
Table.PromoteHeaders(Csv.Document([Content],[Delimiter=",", Encoding=1252, QuoteStyle=QuoteStyle.Csv]), [PromoteAllScalars=true])),
#"ContentTable" = Table.SelectColumns(AddFileContents,{"FileContent"}),
#"NoDataFiles" = Table.IsEmpty(#"ContentTable"),
InteractionTable = Table.ExpandTableColumn(#"ContentTable", "FileContent", Table.ColumnNames(ContentTable{0}[FileContent])),
#"Transformed" = Table.TransformColumnTypes(InteractionTable,{{"Timestamp", type datetimezone}}, "en-US"),
#"Duplicated Column" = Table.DuplicateColumn(#"Transformed", "Timestamp", "Datestamp"),
#"Datestamp" = Table.TransformColumns(#"Duplicated Column",{{"Datestamp", DateTime.Date, type date}}),
#"RenameId" = Table.RenameColumns(#"Datestamp",{{"InternalMarketingInteractionId", "Id"}}),
#"keyedtable" = Table.AddKey(#"RenameId", {"Id"}, true)
in
#"keyedtable"
I have highlighted the datalake name, container and the table. I hope this helps if you are having a similar issue!
Storing data in dataverse is very expensive. Especially the data that is stored in the actual database (db data). Hence, for many customer with larger datasets, typically with some B2C type of business, it is a good practice to overviewing the data you have in the system and figure out different ways of keeping it from costing too much money.
Below are 10 tips you should consider to keep the data in check.
Make a deletion list – and set up deletion jobs
Flatten verbose fields
Use virtual tables
Use datalake with analytics
Use datalake for archiving
Compress complex structures
Clean up non-production environments
Revise datamodel
Revise integrations
Set lifecycle for instances
1 – Make a deletion list and set up deletion jobs
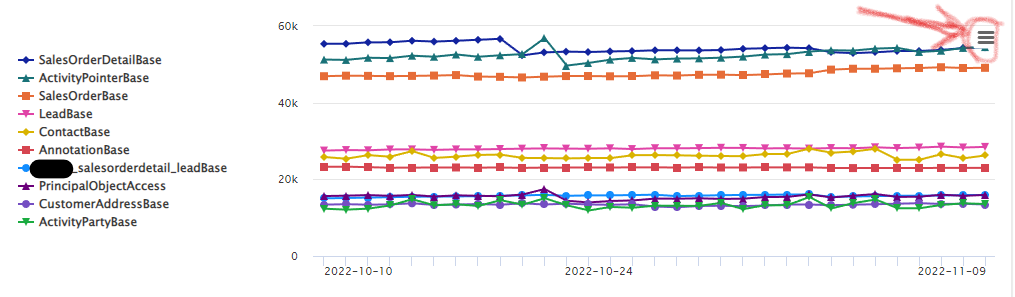
The first thing you need to start doing is to go through the biggest storage contributors. You can find which these are by looking in the Power Platform Admin Center under “Resources -> Capacity”. Open the view of each of the dataverse instances by clicking on the small chart symbol next to the instance.
You can export the full list by clicking on the hamburger symbol in the right hand corner of the graph. See picture below:
You can then start by trying to break down each table from the top. Based on the picture above, ask yourself questions like;
Do we need to store and save all orders? By removing some orders, maybe cancelled orders, we can cut down on two of the three largest tables as the order rows are removed at the same time
What activities are really causing activitypointer (the common table for all activities) to become so large? It is quite common that the email table is a culprit here, as the body of the emails, is usually a quite a few bytes and with thousands or tens of thousands of emails, they do add up. Marketing integrations can also bloat the activitiy pointer. I suggest investigating this further by exporting the data to an Azure Datalake and analyzing it with PowerBI. It is also quite common that not all emails need to be saved, for instance if you have email enabled queues like support@contoso.com it is quite common that you get some spam into this. Maybe searching for “unsubscribe” in email body to see if there might be some newsletter looking spam which enable you to remove them.
Are there any patterns of contacts and/or leads that can be removed? Working with B2C you might find that there are quite a lot of contacts and leads with incorrect data or similar. Ask yourself what value a lead with no phone number and no email has… removing contact data will also remove customeraddress as there will be at least two customer address records for each contact automatically created. The same goes for leads but in that case it is the leadaddress where extra data is being created.
The point with the list is trying to identify possible patterns of data that can be deleted. I typically have one row per rule like so:
Table
Method
Rule
Contact
Bulk Delete
status code = inactive AND modifiedon older than 6m
Email
Bulk Delete
body contains “unsubscribe” AND modifiedon older than 1m
Email
Flatten w Power Automate
Outgoing AND subject = “Covid information”
2 – Flatten verbose fields
Sometime it can be a good idea to just clean out or some “body” data. For example if you have sent emails to a lot of customers with the same Covid related information, the actual content of that email is the same for all and is known by everyone. Hence the body can be removed which can typically be done with a Power Automate Flow or SSIS/Kingswaysoft depending on the size of the data.
3 – Use virtual tables
Not all data needs to be stored in the expensive dataverse database. The recommendation from Microsoft is typically that data which you interact with should be in dataverse and the rest can be somewhere else. As it is now possible to use SQL as a source for virtual tables, as well as Cosmos DB and many other sources, moving data out of dataverse and accessing it through virtual tables can be a viable option.
Virtual tables is also something that should be considered when designing integrations. It is not always critical that all data actually reside in dataverse. Sometime just being able to access the data through dataverse is good enough. Especially if the data source is fast, it isn’t that much data, the data only needs to be accessed seldomly, It is also easier to use virtual tables if the data is read-only and used for reference.
4 – Use datalake for analytics
Dataverse isn’t really a good source for analytics. All endpoints (even the T-SQL) go through the application layer to the database. This makes large data crunching less than optimal in dataverse. This is also why Microsoft have developed methods for replicating the dataverse data to external stores. The just discontinued Data Export Service (DES) which synchronized data to an Azure SQL and the new Azure Synapse Link which synchronizes data to a datalake, are clear examples of this.
Hence, a good architecture for analytics of dataverse data is doing the analytics outside dataverse and the current best place for this is in a datalake with Azure Synapse Analytics.
This also has a direct implication on the data stored in Dataverse, the data you have in dataverse that is only needed for analytics, might not actually be needed in dataverse anymore. This can be anything from old orders, and of course all old communication like emails and phone calls. Datalakes are also way more efficient for doing large scale AI/ML analytics, which many organizations are looking for.
5 – Use datalake for archiving
If you havn’t already thought about it, a datalake can hence be used as an archive for data that you might need but isn’t actually something that you will use every day. Often a lot of data is stored for compliance reasons. When setting up archiving, it is important to make sure that what ever method you use, you probably want to keep the data in the archive after it has been deleted in dataverse, hence you might need to move the data from the initial storage container to the actual archive making sure to not actually move any deletes.
Microsoft have announced that they will be putting their own hot/cold-storage solution for dataverse into public preview this spring. This sounds a lot like some archiving functionality and I am certainly looking forward to seeing what it will be, how it will work and the licensing for it.
6 – Compress complex structures
For some businesses it is often needed to have quite a complex datastructure to handle the operations of what is done. It can be complex order structures with allocations of order rows to specific users or product configurations with billing, logistics and provisioning settings. Once an order has bee fullfilled in all aspects, it might not be required to store and keep all that complexity. It might just be required to keep the order header and the most critical information about what the order rows were about. Perhaps even flattened into a JSON or text field for future reference. If it is possible to move from a order header + 10 records in related tables to just a order header with a summarized text, for thousands of orders, than can save quite a lot of space.
7 – Clean up non-production environments
Data isn’t only stored in the production instances of dataverse. Many times production instances are copied and turned into test or staging instances. Integrations may be running towards development and test instances generating substantial amounts of data. Have a look at your non-production instances and check which data you actually need in them.
8 – Revise datamodel
Sometimes datamodels can become unnecessarily complex. This is most common when someone with little experience of dataverse and model driven applications design solutions. Other typical problems I have seen are repurposing of tables like leads, accounts, sales order to other simpler purposes. The problem from a dataverse storage perspective becomes that the additional storage overhead in these cases, especially in cases with businesses that have a lot of customers, can be rather drastic. Redesigning the datamodel to be more sleek can make it both more user friendly and use less storage.
9 – Revise integrations
Integrating data to dataverse can be a large culprit for data. For instance, many marketing applications generate quite a lot of data regarding the behaviors of customers. This data can then be integrated to dataverse to be used there. As behavioural data can be very granular, to the level of “Customer x has be send email y”, “customer x has read email y”, “customer x has clicked link z in email y” this data can take up substantial amounts of storage if integrated to dataverse. What options exist for this are different for different marketing applications. For ex Adobe Marketing can shut off this integration and can instead synchronize behavioral data to an Azure datalake where it can be unified with other dataverse data.
ERP integrations are also a common area of problem. ERP systems often have a very deep granualar level of data which might not be needed in dataverse/Dynamics 365 CE. Sometime just enabling deeplinking directly to the ERP system can be a better method, combined with virtual tables. However, this is not always the case and sometimes the best solution is just synchornization of the data.
However, do recognize that there should be a reason for having the data in dataverse. It should genrally be actively used.
10 – Set lifecycle for instances
Having dataverse instances with a bit unclear usage and not knowing what they are for and if they can be removed is, of course, a source of quite a lot of data consumption. By clearly assigning owners, reasons etc for all instances it makes answering the question “Do we really need ‘Internal test applications sprint 7′” or is it just an old remnant from a two year old development. This is part of the Center of Excellence starter kit and the processes that are important to set up in relation to this.
I hope any of these 10 tips have been useful. If you think so, the best way to thank me is to tweet or share your thoughts on this in social media. Also feel free to leave a comment below.
Perhaps you have some other thing that you think should be done or that I missed something. If so, please share in the comments below.





Recent Comments