
by gustaf | Apr 20, 2021
“Do you really need to delete records like a Ferrari?” – that question was posed to me when I, a few years ago complained about the bad performance of the Bulk Deletion functionality in Power Platform (at that time Dynamics 365 Online) to a friend at Microsoft who I will not name. And my simple answer is yes, we do need to delete records like a Ferrari, for many reasons. I will discuss why in this article and I have for that reason also created an Idea on the Power Apps Community site on this subject and I hope that you agree with me and vote for it! You will find it on the link below.
Click here to go to the idea article and vote for faster bulk deletion
So, why is a fast bulk deletion important. I would say there are several reasons and I will walk through the ones that I have thought of, if you have any other, please drop a comment.
- Keep your data in check – remove unnecessary data
- GDPR and other compliancy and legal issue
- Power Platform growing into Citizen developer platform
- Entitlements effectivly blocks using external tools
Keeping data in check
For larger organizations, especially with many integrated modules and systems, many running Flows, workflows, Customer Voice surveys etc. the system will generate a lot of data, especially if it is a B2C scenario. A few of these have built in features that automatically remove old logs etc but most don’t and we as admins and system caretakers (isn’t it a fancy title!) need to tend to this, typically by setting up jobs that clean old data. I would recommend looking at the PPAC statistics of which tables are the largest and having a practice of doing so at regular intervals and downloading it. That way you can see the trends over time. A suggestion for an addon to the CoE Starter kit would be a trend analysis of all tables with growth numbers per week for each tables with warnings for quickly growing tables and prognosis.
However, as instances start growing over 50-100 GB in size (of structured data) it soon becomes too large to handle the data with bulk deletion. Some tables might still be managable this way, but in general the performance is has is, when I have tried to measure it (albeit a few years ago) was around 1-3 records per second. A customer I have, working with B2C for whom I wanted to remove their Voice of the Customer, which had been used a lot, had over 50 Million Survey Invites. It is not possible to remove the solution without first removing the data, and if we were to use Bulk Delete and put it on crack and it got to 10 records per second, it would still take around 2 months. I now did it with SSIS/Kingswaysoft and it took a few days. If Bulk Delete could reach around 200 records/second, it would take a little less than 3 days.
I have also noted that when trying to Bulk Delete very large datasets, Bulk Delete simply fails, as I think the FetchXML query might do a SQL Timeout or something like that. Not exactly sure what happens. As it works with Kingswaysoft I don’t know what might be the difference.
GDPR and other compliancy and legal issues
As GDPR and other similar compliancy regulations have come into play in many countries around the world, it has become ever more important to stricly follow these detailed instructions. These might be simple when you look at them on a Power Point C-level perspective but when you dig down on the detailed level, where they actually need to be implemented, things seldom are as simple as in a Power Point.
Power Platform growing into Citizen developer platform
As the Power Platform grows from being just a platform on which Dynamics 365 is delivered to being a huge platform for digitalization entire organizations with almost 100% user saturation will be coming starting to use Dataverse. The amount of data being stored in dataverse will hence grow to massive amounts and hence an effective tool to manage this data is most important. It is probably even important to such a level that Bulk Delete cannot even scratch the top of the iceberg of what we need to be able to do on a data management perspective as data will be growing and expanding in heaps and bounds and admins will not only need to manage Flows and Apps but also data in size and content.
Entitlements effectivly blocks using external tools
The soon to enacted entitlements, as mentioned in my previous post, Entitlements are not throttling | Powerplatform.se, also effectivly stop the use of external tools like SSIS/Kingswaysoft for deleting unwanted data. One of the customers I am working with generate between 10-20 M API requests PER DAY, and the bulk of these are from deletion jobs or other maintainance jobs trying to keep track of the instances. With the new entitlements charge, there is no way this can be continued, but the customer is cought between a rock and a hard place as either the data grows by leaps and bounds or the API calls becomes a huge cost and there is no easy way to handle it. What advise am I to give the customer? I would think that the most reasonable thing would be if the platform made the tools available to maintain the data to avoid the costs. If this is using bulk delete or some other more elaborate feature, that is up to the product team but I do think they should hold off on activating the entitlements until there is a good alternative for managing an instance data within the platform before this (not generating API requests).
What else is missing?
Bulk deletion is not only not being performant enough, it also lacks the effective filtering logic that is required for more complex queries. For some customers a I have had to construct rather elaborate SSIS scripts which start with a complex FetchXML and the filter the data through several Cache Transforms, for instance with GDPR consents and similar to be able to get the final list. I must admit that I havn’t tried using the new T-SQL connector for this, that it could handle the full T-SQL complexity and that it is implemented in Buld Delete or Kingswaysoft as a means to make querying more powerful.
by gustaf | May 24, 2018
On the eve of GDPR what could be more fitting than a post on GDPR. I think everyone is probably deadly tired of all the consent emails and I think that they will probably even have reached our friends in the US and Asia by now.
This article relates to legal matters on GDPR and are based on my personal interpretations and are not to be viewed as legal advice.
One interesting thing that has to be considered in relation to GDPR is how to handle personal information in non-production environments/instances. Microsoft have made it painfully easy with the instance manager to be able to copy the production instance but do you really have the right to use your customers personal information in a development, UAT or staging environment? Do you have legal support for that? I think that would be a very hard argument to make? Have you gotten your customers explicit consent for using their personal data for that purpose? Probably not. Hence, if you are planning on keeping the instance/environment for more than 30 days, you will need to remove all personal information from to stay within the boundaries of GDPR. I have found that using SSIS with Kingswaysoft and the Anonymization component in the productivity toolkit is very useful. I will in this rather lenghty article describe how I have used it to set up an anoymization script.
First of all you need to download SSDT and Kingswaysoft Dynamics 365 and Productivity Packs
Then start a new Business Intelligence -> Integrations Services project.
Then start by right clicking in the empty field at the bottom where it says “Connection managers” and choose “New connection…”
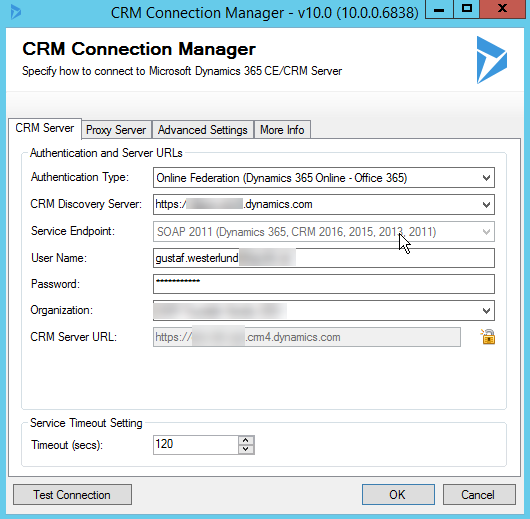
In the dialog that shows up choose “DynamicsCRM”
You should now see a dialog showing the connection settings to Dynamics.
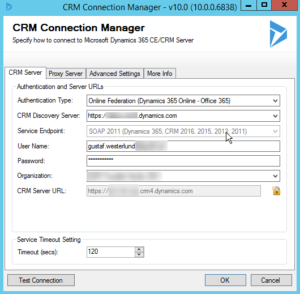 |
| Connection settings for your instance |
Choose the right settings for your instance. Test your connection at the bottom when you are done to make sure it works. Make extra sure you are not connecting to your production environment, wouldn’t want to anonymize that!
When this is done, it is time to make your first Data Flow Task. Work in SSIS is divided into two parts, Control Flow and Data Flow. The control flow is the orchestration, which tells SSIS in which order everything is to be run. If you want thing to run in parallel, just have to boxes next to each other, if you want one Data Flow to run before the other, drag the arrow from the first to the second. It is also possible to have entire “Sequence containers” which can hold several components and make sure they execute before moving to the next stage.
Let’s start by dragging one new Data Flow from the Toolbox on the left hand side to the Control Flow work pane. Then double click it. This will open it up.
You will now see that the tab at the top has changed to “Data Flow” from the previous “Control Flow”. In the “Data Flow” view you will also have a different set of toolbox components available.
In the “Data Flow” you will control a single data flow. For instance the anonymization of Contact.
Start by dragging the Dynamics CRM Source from the toolbox (on the left) to the workspace (the big pane in the middle. Then double click it. – Before looking at the details of the source component, I like using FetchXML when building queries and of course the best way to build queries with FetchXML is using FetchXMLBuilder in XrmToolBox (thanks Jonas Rapp and Tanguy Touzard for all your work!) but if that is too much heavy lifting (it really isn’t), the easiest way to get a FetchXML query is to make an advance find query and export it with the “Download FetchXML” button in the top right hand side of the ribbon of the Advanced Find query builder. So let’s say we have decided the following fields in Contact are personal information and need to be anonymized:
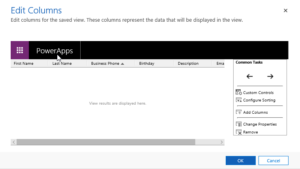 |
| The column editor in advaced find – don’t use composite fields like “fullname” or Address1 |
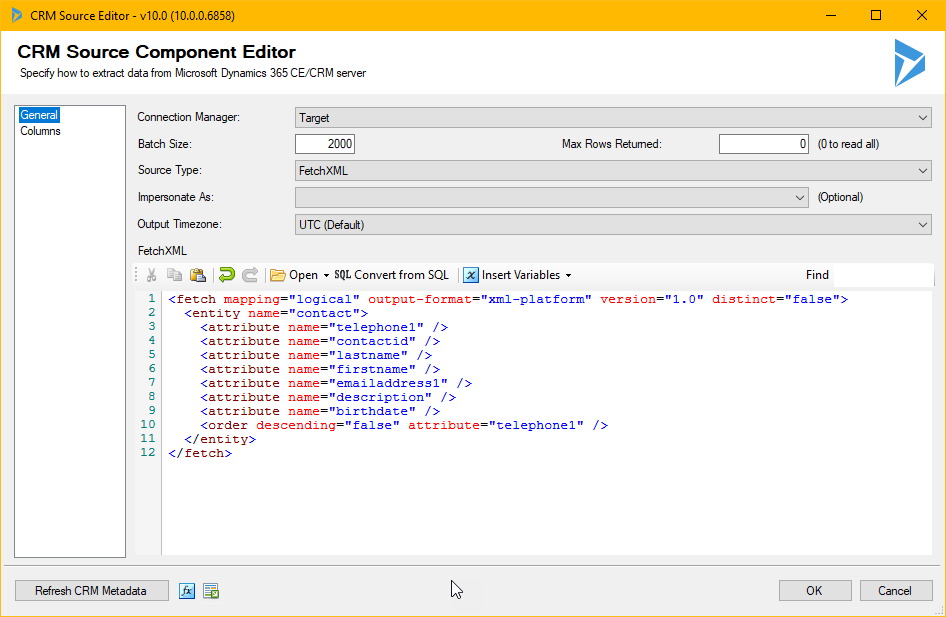
Downloading the FetchXml, and setting the Source component in SSDT (Visual Studio) will make it look like this:
I have set the “Connection Manager” to “Target” as we are using the same source and target (reading and writing to the same system.
I am leaving batch size as 2000. Seems to work well. Don’t reduce it too much, remember the API limit of 60 000 calls per 5 min period.
If you would like to try it a bit, you can set the “Max rows returned” to for instance “10” and then try it out a bit to see that it isn’t going crazy.
Source type I like as FetchXML – remember that you can have FetchXMLs with data from several entities which can make queries a lot easier than trying to match the data with lookups in SSIS.
I always try to read all data in UTC and write it in UTC which in most cases makes it correct. But make sure you understand how timezones work if you need to fiddle with this.
Also, don’t include more columns than you need. It will just make your script slow. After adding the FetchXML or changing it, it will try to parse it and read the meta data from Dyn365/CRM. Hence there might be a slight delay. You can check what data you will output from this component by clicking on “Columns” on the left hand side.
When done, press “OK” to go back to the “Data Flow” pane.
Now add a “Data anonymization” component and drag the arrow from the Source component to the Anonymizer. Then double click the anoymizer.
You should see something like this, where I have set anonymization settings for the different columns. By default it will say “Ignore” on all columns.
Try out the different anonymization types. Some are more generic than others. When done, click Ok and go back the data flow pane. Add a Dynamics CRM Destination and drag the blue arrow from the anonymizer (blue arrows are the normal data output, red arrows are error output) to the Dynamics CRM Destination component. Then double click it. The view in the data flow should look something like the picture below.
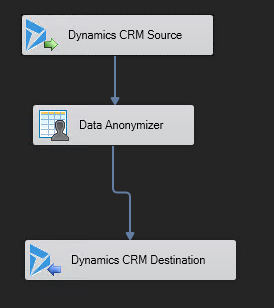 |
| Dyn365 Soruce -> anoymizer -> writing to Dyn365 |
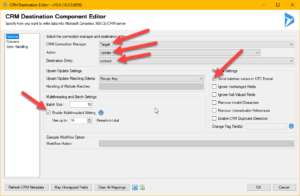 |
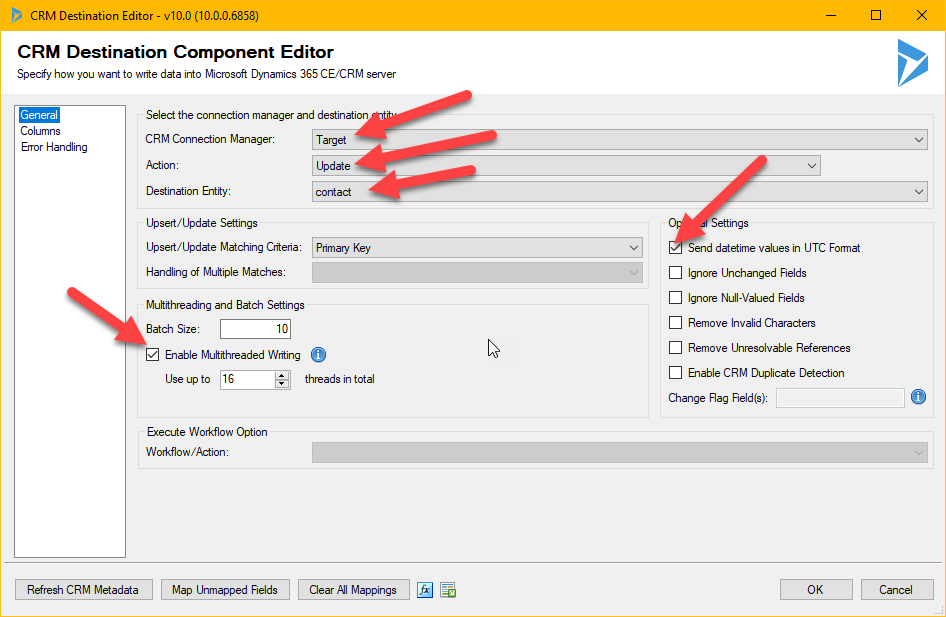
| Dyn365 destination component – set values where the arrows are |
When setting up the destination component, there are a few things to consider:
- In this case we are always doing updates – hence set the action to update. It is faster than upsert.
- You have to set the Destination Entity.
- If you write data to Dyn365 with high latency, no batching and no threads you will be able to update at about 2-3 records per second. With low latency, correct batch setting and multi threading, I have been able to get up to 300 records per second. Very dependant on entity. Hold the mouse of the blue “i” just after the “Enable Multithread Writing” for some deep end tips from the scholars at Kingswaysoft.
- Error handling is recommended to be directed at a file or some other output where you can monitor it. If you do nothing about it, and you get an error, it will break the flow and stop. You can control error handling of the destination component by clicking on the “Error handling” tab on the left hand side. Remember that all types of exceptions thrown by Dyn365 you will get here as well, like missing rights, disabled records etc.
A normal problem that needs to be handled is that records are deactivated and deactivated records cannot be changed, they have to be opened first, then changed, then re-closed.
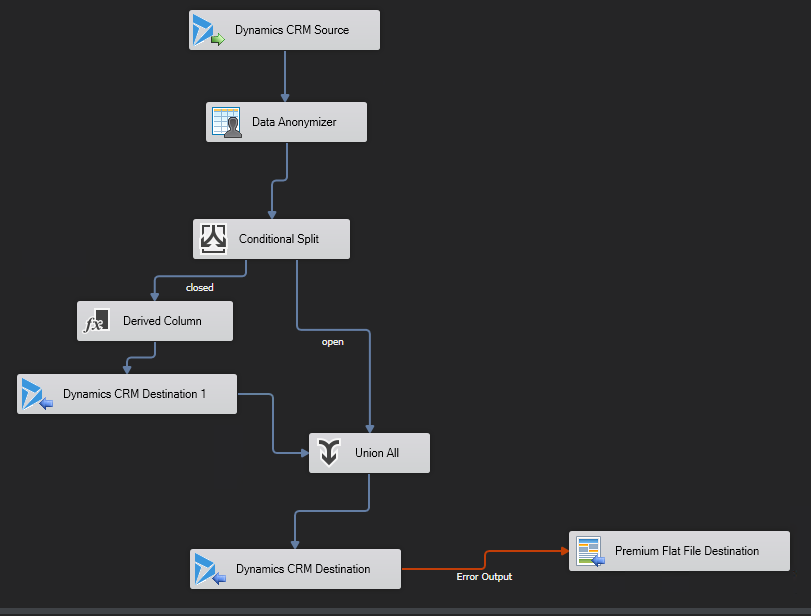
This is an example of a dataflow handling this:
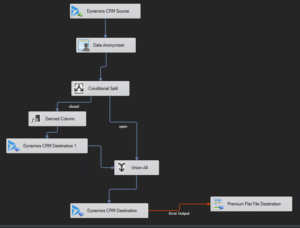 |
| Data flow which splits the deactivated records to the left, adds two special columns to reactivate them, writes an update with only the statecode & statusreason to the record and then merges the two data streams and writes the original values, which recloses the ones that were closed from the beginning |
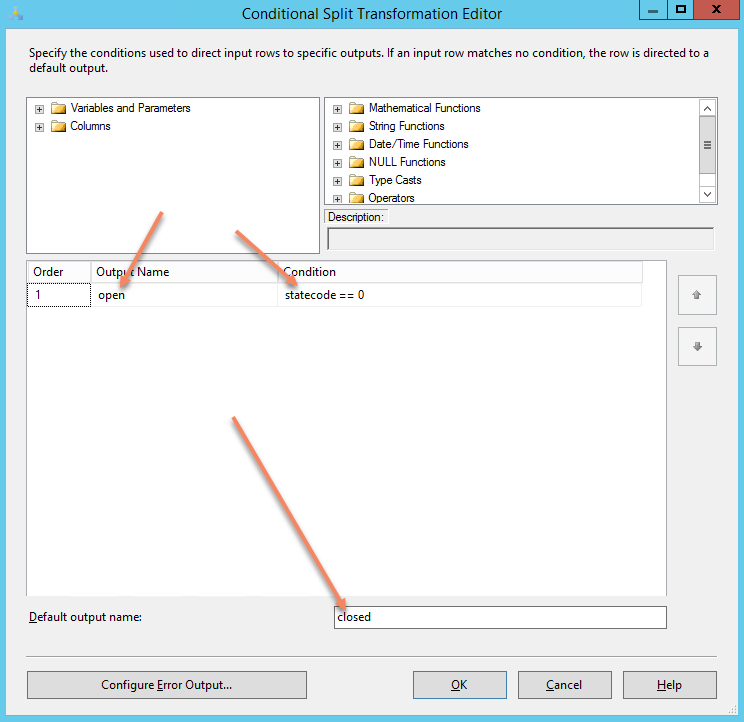
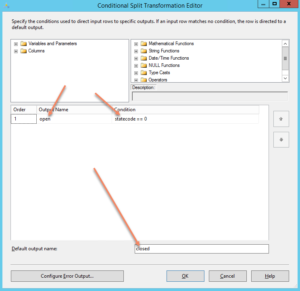 |
| This is how the conditional split is defined – if statecode is 0, send them to the output called “open” otherwise send them to the output called closed |
Then you can test run your data flow, by right clicking the data flow pane, and pressing “Execute Task”
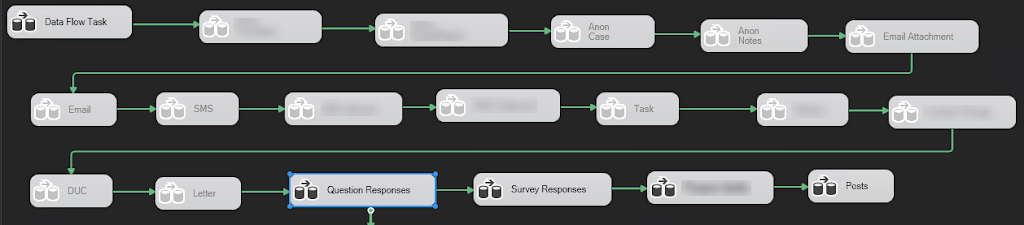
And when you have assemble an larger control flow – like for instance this:
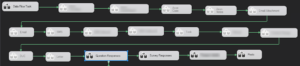 |
| A control flow with several dataflow being disabled – all in sequence. |
you can execute the entire flow by clicking the green plus sign in the ribbon.
Gustaf Westerlund
MVP, Founder and Principal Consultant at CRM-konsulterna AB
www.crmkonsulterna.se






Recent Comments