There are scenarios in CI-D when it is integrated with Dataverse where you may run into a bug with the platform. This is when one of the COLA (Contact, Opportunity, Lead or Account) table records has the lookup Customer Profile pointing at a customer profile that isn’t there any more. In other words an orphan link, something that typically should not exists. I will start by describing a scenario where this can occur, what problems it can cause and how to fix it, both short term by you and long term by Microsoft.
When does it occur?
This problem typically occurs if you have chosen to have more contacts in dataverse than you have in CI-D. The most common reason for this is that each 100k of unified profiles in CI-D incur an non-trivial licensing cost per month. Hence skipping the least valuable customers could be a way to reduce this cost. The problem, on a more technical note, is of course that you will have to filter the customers before they are ingested into CI-D. The new filtering functionality in CI-D that is about to be released will probably help with this.
So, let’s say for the sake of an example that we are only keeping customers in CI-D that placed an order with us during the last 24 months. This means that if you have a customer that yesterday was included, it could pass the threshold and be excluded today. Hence it was synchronized to dataverse yesterday with the rehydration functionality and the corresponding contact record was linked to the customerprofileid with the COLA Backstamping functionality. However, today, when the synchronization happened, this contact is no longer part of the unified profiles and hence is not synchronized to dataverse. However, the COLA backstamping functionality does not clean up after itself properly and hence the customerprofileid lookup on the contact record that was set yesterday, is still set BUT as there is no customer profile that corresponds to this anymore, there is an orphan link.
What problems can it cause?
Let’s say you have an integration that might not as specific in its data processing as is best, and hence it reads all fields from dataverse, changes some and then writes all fields back, instead of just the ones that were changed. If this happens to a record with an orphan lookup link then when you try to save the contact to dataverse, the platform will throw an exception saying that the customerprofileid is incorrect/not pointing at a real record.
How to fix it yourself
The easiest fix you can do is probably to write a Power Automate flow that loops through all contact records and verifies that the customerprofileid is set to something that actually exists.
Another fix is to rebuild the integration so that it only changes fields it actually has a change for. This, does require some extra coding, but that code could be rather generic so that you can use it more. This change will also make your code execute faster. It does, however, not actually fix the problem, just removes the symptom.
For field and table reference, below is a FetchXml that will return the contacts that have the lookup field set and one for all customer profiles. I have tried combining these in an outer left join to get the ones that are incorrectly linked, but there is a limitation in FetchXml that is stopping this.
My suggestions to Microsoft on how they should fix it
There are two different ways to solve this from a Microsoft side, one is on the CI-D integration side and the other on the dataverse elastic table side.
First of all, I think this is an incorrect implementation by the CI-D team. Elastic tables currently do not respect cascade rules like “remove link” and this should be a known fact. Hence they should implement a function that after the backstamping is done for all existing records, it should clean up any customerprofileid:s that do not have a corresponding record.
The second alternative solution is for the dataverse team to implement functionality to respect some of the cascade rules, in essence making sure the dataverse platform cleans up any links to records that do not exist. The positive side of this would be that this fix would help any lookup pointing to an elastic table, as this is most certainly not limited to just the CI-D integration, but the negative side is that this would affect the performance of elastic tables, especially during deletes.
When working in CI-D and replacing a datasource with another, for example replacing Power Query Datasource with Delta, then finding any dependencies for this is important. This is a tip that I got from Microsoft Fast Track Architect Ashwini Puranik, so credit should go to her. You can use the API testing functionality that is part of CI-D to query the ListAllMeasuresMetadata. Keep on reading to get some more details.
As the general recommendation for CI-D is to move to Delta-based data sources from Power Query due to performance. However, doing this shift will require you to reroute all dependencies to the new table before you can remove the data source.
Below is a way to find the dependencies based on Measures and Segments defined in CI-D.
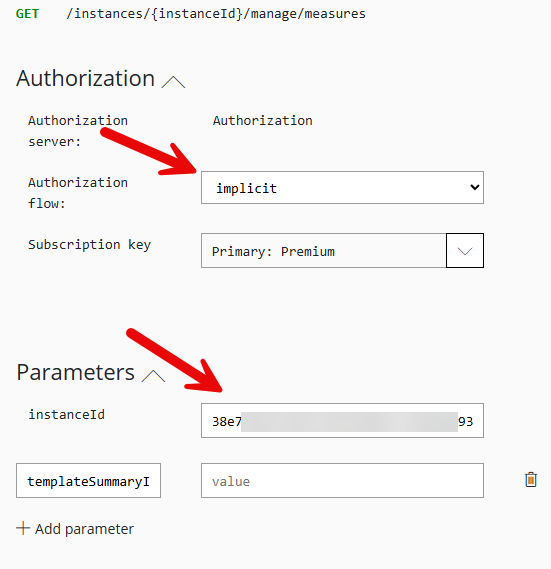
Start by going into the API testing tool that is available for CI-D using the Permissions-area and the tab “API”.
Choose the only available API, Customer insights – v1.
Now search for ListAll and select “ListAllMeasuresMetadata”.
This will show a more detailed description of the endpoint. Now click “Try it!” in the green button on the right hand side.
This will show a panel on the right hand side where you have to input some required data. For an easy test, just select “implicit” in the Authroization drop down and put the instanceid into the field for it. In case you don’t know where to find the instanceid, you can grab it from the URL when you are using CI-D using the normal UI as it is the only guid in the URL.
That is all that is required, so scroll down to the bottom and press “Send”
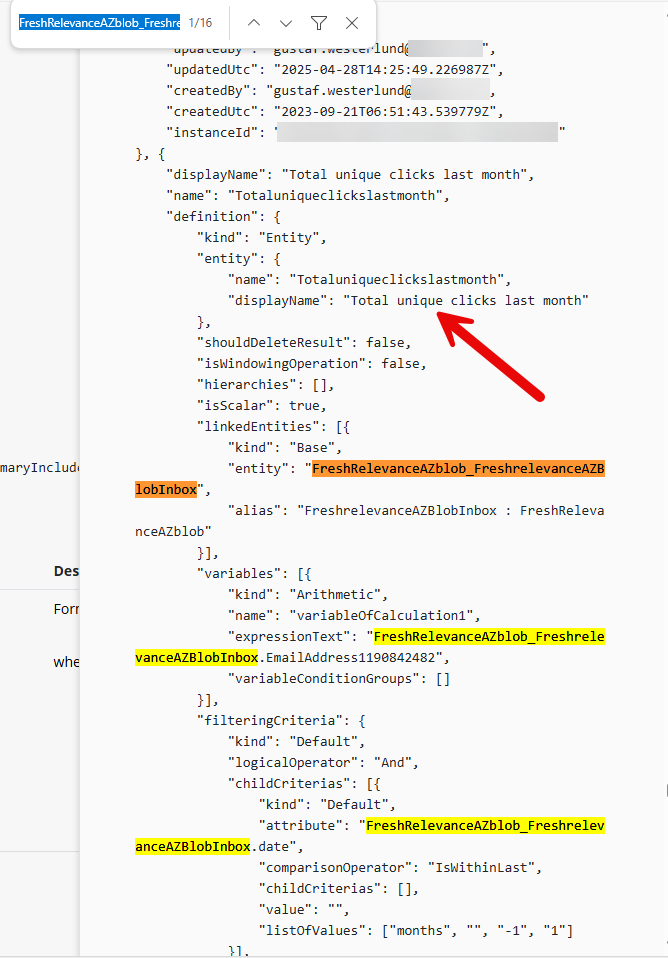
You will now see a long text (json) which is the response from the api call. You can use the built in search in the browser to find all occurances of a datasource. You can use either the Display name or the schema name as both are in the JSON. As you can see below, the Measure “Total unique clicks last month” is one of the measures that has a dependency on the Datasource named “FreshRelevanceAZblob_FreshrelevanceAZBlobInbox”.
Now there are a few options, either remove the measure. This is a good option if you want to fix this quickly or the measure isn’t being used, if it is used there can on the other hand be many dependencies on the measure making it a lot more complex to remove. The other option is hence to just change all dependencies in it to another (Delta) datasource. You will then have to refresh the data source to remove the dependency fully. You can rerun the query by resending it using the button at the very end.
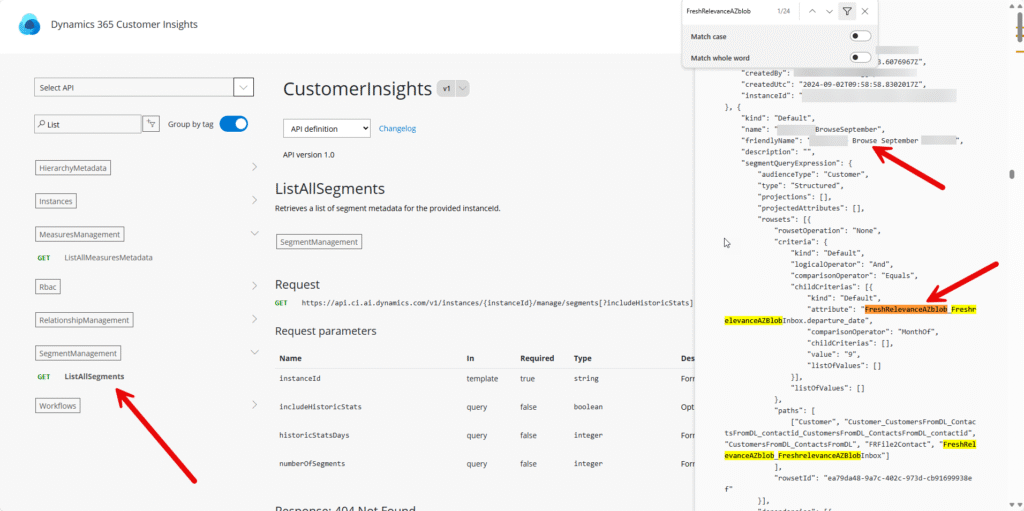
Once you have removed all dependencies on the data source from measures, there might still be dependencies from segments. You can use a similar method as above, but the endpoint you want to use in this case is “ListAllSegments”.
You can still have dependencies left on the datasource, for instance from things externally using the table from the CI-D API. This doesn’t actually block you from removing the data source but whatever you are doing externally will stop working once you have removed the data source. Naturally.
I hope this has helped and thanks a lot to Microsoft Fast Track Architect Ashwini Puranik for pointing me in this direction.
Recently two new features were introduced to dataverse that allows us to better manage customer addresses. A few years ago (2012) I wrote an article on the subject (https://community.dynamics.com/blogs/post/?postid=b889a366-d3fb-4b39-bdb9-7f3716283d4c) which goes into some detail about how the customeraddress table works. This post will revisit some of that and also discuss how the two new features regarding the customeraddress can help us better manage our data.
To make this a bit shorter, the addresses of accounts and contacts are not stored in these tables but actually in a special table called customeraddress. This is hidden to most user operations but it does show up in some cases, for instance in storage calculations in PPAC. The same goes for the lead table which has a special leadaddress table that supports that.
With the default settings, for every account, you will get 2 customer addresses, and for every contact you will get 3 customer addresses. Lead has two addresses and hece will have two records of lead addresses.
This can start becoming an issue if you have lots of these base records, contact, account or leads, which are more or less empty. So even if there is no address data on these records, they will still have these supporting records and all records in dataverse will take up some storage, based on the fact that there are some fields that always are created like modifiedon, createdon, modifiedby etc. Typical scenario where this can start becoming an issue is if you are using dataverse for marketing and you have several million leads to whom you send newsletters but don’t really know that much more about them. With 1 million leads, you will get 2 million empty lead addresses.
So, what is new? The new functionality Microsoft have released are two features. The first feature is that the customeraddress or leadaddress records are not created until there is actually information that needs to be stored in these records. This is generally a good setting to be set to true, as storing more or less empty records isn’t really very useful.
If you have an existing system with 2 million contacts and 4 million leads, this will however not remove the existing customeraddresses (6 million) and leadaddresses (8 million) that are empty. For this, there is the second new feature which allows you to remove customeraddresses without removing the contact/account/lead. There is, of course a workaroud for this, and that is to create a new contact/account/lead with the first feature switched on, hence not creating any address records, and then merging this record with the old one and finally removing the old deactivated records. It is, however, much easier to solve it with just removing the address records.
Before running anything like this, make sure you make a forced backup of your instance. I have seen onprem systems where there are lacking address records and that is just very very weird.
Hope this helps explaing a bit about how this functionality works.
When measures are created in CI-D to be used in CI-J there are dependencies created which will stop you from removing the measure. CI-D is not very helpful in telling you how to remove it. I will try to be a bit more helpful.
When trying to remove the Measure this is the error I got:
Error: Detected DataVerse dependencies in Measure: ListMemberships. Please delete these dependencies and merge again.
Request ID: 14056846-b9c1-4ec8-98c2-88778e518b88
Time: 2024-12-05, 11:12:10
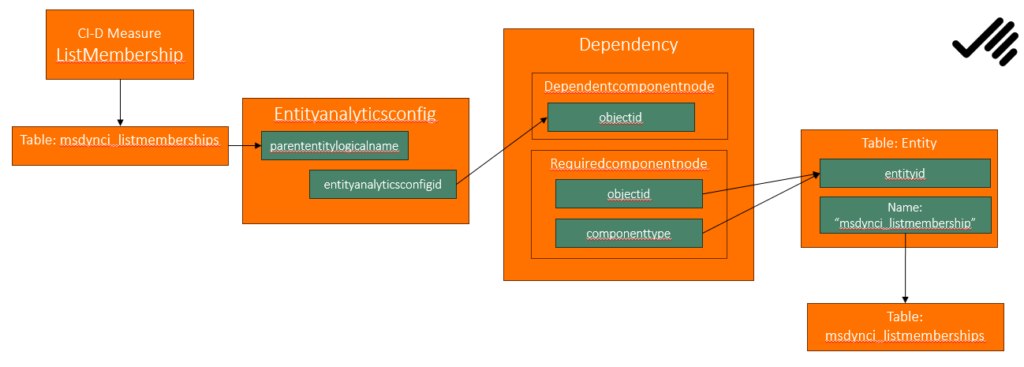
My investigation below with the help of Microsoft Support lead me to the understanding according to the image above. As you can see dependency is actually sort of circular, or at least one part of the dependency (dependent component) is at the entityanalytics on the record which points to msdynci_listmemberships, on the other hand (required component) on the table msdynci_listmemberships.
The fix, is to remove the record in entityanalytics. Easiest way in this case, is to just use a browser console where you are logged into the right Dynamics.
To remove the entityanalytics record that is blocking this:
After this I was able to remove the measure in CI-D.
Below I will detail the steps I did to understand this.
The first step is to look in the table “entityanalyticsconfig” searching for the name of the Measure. Its name is “msdynci_” + name of the measure. Check out the metadata if you are unsure.
Hence, from this I generated the image above. Since it is something of a circular reference, Microsoft Support suggested that I remove the entity analytics record with id: e46e52db-46a7-4585-8a6a-6ba888a5bd1f. However, not entirely sure what this is and hence I tried the one I had gotten in the first steps above, and that worked.
Generally I think it is a good idea to investigate what the dependencies point to, before removing something. In this case the dependency record in itself wasn’t removed, only the dependent part.
Thanks to Microsoft support for helping out with this and I hope it might shed some insights if you are having similar issues. I also think breaking down the dependency table in a tool in for instance XrmToolBox would be a great idea. I have a bit of a bad conscience for BulkDeleteManager that I own and I am not giving enough love, so feel free to build it based on this and I guess some more stuff. I will be happy to help out the the investigations if you are willing to build it.
In a previous post I blogged about how to break down the Form script that was exported from CI-J (Real Time). As some customers asked me about making this into a script that was the same and was dynamic based on query string parameters (parameters in the URL), I worked a bit on that and thought I’d share it here;
A few things that can be mentioned. This script expects that there will be two query string parameters: id – the id of the form. Click on the form and copy it from the URL after the “id=” orgid = the orgid which you can find in the PPAC or in the export of the script as I described in the previous article. If it is placed on the url: https://contoso.com/form.html then an example of the url would be:
Finally some organizations also have problems with loading a script from external sources. I will look at that too. Mainly there are two option. Copy-paste the entire script inline into this script or copy the script file to an “internal” or recognized store with a public URL and change the src-attribute. If you move this away from referencing Microsoft, I would recommend checking their website on a regular basis to make sure it hasn’t changed.





Recent Comments