
by gustaf | Apr 20, 2021
“Do you really need to delete records like a Ferrari?” – that question was posed to me when I, a few years ago complained about the bad performance of the Bulk Deletion functionality in Power Platform (at that time Dynamics 365 Online) to a friend at Microsoft who I will not name. And my simple answer is yes, we do need to delete records like a Ferrari, for many reasons. I will discuss why in this article and I have for that reason also created an Idea on the Power Apps Community site on this subject and I hope that you agree with me and vote for it! You will find it on the link below.
Click here to go to the idea article and vote for faster bulk deletion
So, why is a fast bulk deletion important. I would say there are several reasons and I will walk through the ones that I have thought of, if you have any other, please drop a comment.
- Keep your data in check – remove unnecessary data
- GDPR and other compliancy and legal issue
- Power Platform growing into Citizen developer platform
- Entitlements effectivly blocks using external tools
Keeping data in check
For larger organizations, especially with many integrated modules and systems, many running Flows, workflows, Customer Voice surveys etc. the system will generate a lot of data, especially if it is a B2C scenario. A few of these have built in features that automatically remove old logs etc but most don’t and we as admins and system caretakers (isn’t it a fancy title!) need to tend to this, typically by setting up jobs that clean old data. I would recommend looking at the PPAC statistics of which tables are the largest and having a practice of doing so at regular intervals and downloading it. That way you can see the trends over time. A suggestion for an addon to the CoE Starter kit would be a trend analysis of all tables with growth numbers per week for each tables with warnings for quickly growing tables and prognosis.
However, as instances start growing over 50-100 GB in size (of structured data) it soon becomes too large to handle the data with bulk deletion. Some tables might still be managable this way, but in general the performance is has is, when I have tried to measure it (albeit a few years ago) was around 1-3 records per second. A customer I have, working with B2C for whom I wanted to remove their Voice of the Customer, which had been used a lot, had over 50 Million Survey Invites. It is not possible to remove the solution without first removing the data, and if we were to use Bulk Delete and put it on crack and it got to 10 records per second, it would still take around 2 months. I now did it with SSIS/Kingswaysoft and it took a few days. If Bulk Delete could reach around 200 records/second, it would take a little less than 3 days.
I have also noted that when trying to Bulk Delete very large datasets, Bulk Delete simply fails, as I think the FetchXML query might do a SQL Timeout or something like that. Not exactly sure what happens. As it works with Kingswaysoft I don’t know what might be the difference.
GDPR and other compliancy and legal issues
As GDPR and other similar compliancy regulations have come into play in many countries around the world, it has become ever more important to stricly follow these detailed instructions. These might be simple when you look at them on a Power Point C-level perspective but when you dig down on the detailed level, where they actually need to be implemented, things seldom are as simple as in a Power Point.
Power Platform growing into Citizen developer platform
As the Power Platform grows from being just a platform on which Dynamics 365 is delivered to being a huge platform for digitalization entire organizations with almost 100% user saturation will be coming starting to use Dataverse. The amount of data being stored in dataverse will hence grow to massive amounts and hence an effective tool to manage this data is most important. It is probably even important to such a level that Bulk Delete cannot even scratch the top of the iceberg of what we need to be able to do on a data management perspective as data will be growing and expanding in heaps and bounds and admins will not only need to manage Flows and Apps but also data in size and content.
Entitlements effectivly blocks using external tools
The soon to enacted entitlements, as mentioned in my previous post, Entitlements are not throttling | Powerplatform.se, also effectivly stop the use of external tools like SSIS/Kingswaysoft for deleting unwanted data. One of the customers I am working with generate between 10-20 M API requests PER DAY, and the bulk of these are from deletion jobs or other maintainance jobs trying to keep track of the instances. With the new entitlements charge, there is no way this can be continued, but the customer is cought between a rock and a hard place as either the data grows by leaps and bounds or the API calls becomes a huge cost and there is no easy way to handle it. What advise am I to give the customer? I would think that the most reasonable thing would be if the platform made the tools available to maintain the data to avoid the costs. If this is using bulk delete or some other more elaborate feature, that is up to the product team but I do think they should hold off on activating the entitlements until there is a good alternative for managing an instance data within the platform before this (not generating API requests).
What else is missing?
Bulk deletion is not only not being performant enough, it also lacks the effective filtering logic that is required for more complex queries. For some customers a I have had to construct rather elaborate SSIS scripts which start with a complex FetchXML and the filter the data through several Cache Transforms, for instance with GDPR consents and similar to be able to get the final list. I must admit that I havn’t tried using the new T-SQL connector for this, that it could handle the full T-SQL complexity and that it is implemented in Buld Delete or Kingswaysoft as a means to make querying more powerful.

by gustaf | Aug 29, 2019
In May 2019 Dynamics 365 CE/CDS enacted some new throttling mechanisms that have caused some headaches for anyone wanting to manage a lot of data in CDS (I will refer to Dynamics 365/CDS as just CDS below). There are several different throttles but the one that has cause me most trouble is the concurrency throttle. Kingswaysoft will release support for handling this in the next release and you can also request a special version from them if you ask nicely. In the meanwhile this post can give you some help on how to work as fast as possible using application user mulitplexing and a loop with a 5 min wait to make sure that the throttles are reset.
The new throttling on the main CDS API, as described here: https://docs.microsoft.com/en-us/dynamics365/customer-engagement/developer/api-limits needs to be carefully considered when doing heavy data manipulations in the CDS. One of my customers has a large system with numerous integrations of which the most data heavy are the Marketing Automation systems and the booking systems. And yes, this is Business to consumer.
With the new per GB pricing, keeping the database as small as possible has become an essential task and using the bulk delete just doesn’t work for large data loads, at the time of writing this article. I do hope that Microsoft increase the speed of it so that it does become more useful but currently its speed is somewhere around 1-2 records per second.
The bulk delete also has limitations on that it can only base it selections on a query, i.e. a FetchXML. Often this is not enough, for instance when you want to remove “All emails except those that have any connection to either a case or a contact which has a case”.
For these reasons I almost always opt for using SSIS with Kingswaysoft connectors to CDS when working with complex data management. This article will be on how to get some performance now that there is tougher throttling to take into consideration.
User multiplexing
As the throttling is measured on a “per user”, one trick is of course to use multiple users and spread the load over all these users. You can, of course use normal users, but that will cost you licenses so the smart person will of course use application users instead. If you don’t know how to create application users in Dynamics 365, check it out here: https://docs.microsoft.com/en-us/dynamics365/customer-engagement/admin/create-users-assign-online-security-roles#create-an-application-user . In the example below, I will be using four different application users, one as the source account and three as destinations. The reason for this is that it is typically easier to read several thousand rows per request, but seldom efficient to do batch creates/writes/deletes of more than 10-20.
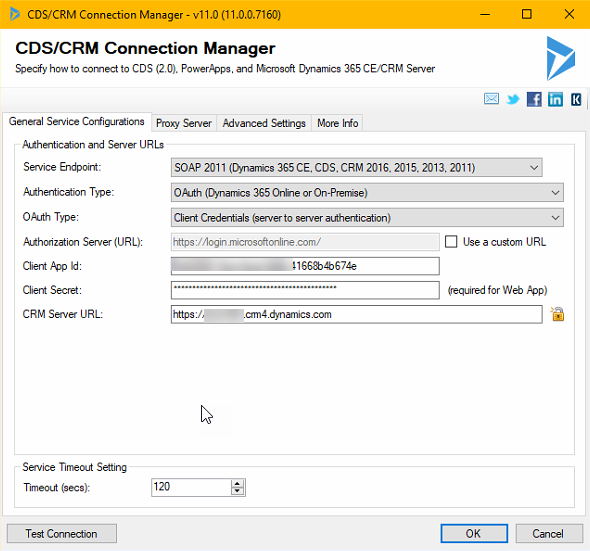
To do this with SSIS/Kingswaysoft you should start by setting up the connections. In this case, the four CDS/CRM connections and use the OAuth auth-type like below.
As you might want to have several packages in the same project and have them share the connections, it may be a good idea to use project connections. I also use an Azure SQL db for logging any errors. Previously I used to use CDS but now with the throttling, that is not such a good idea as the error itself might be throttling and hence the error can cause an error. Writing to some target that you know will not fail is hence a good idea for logging errors. When you are done with the connections, it should look something like this:
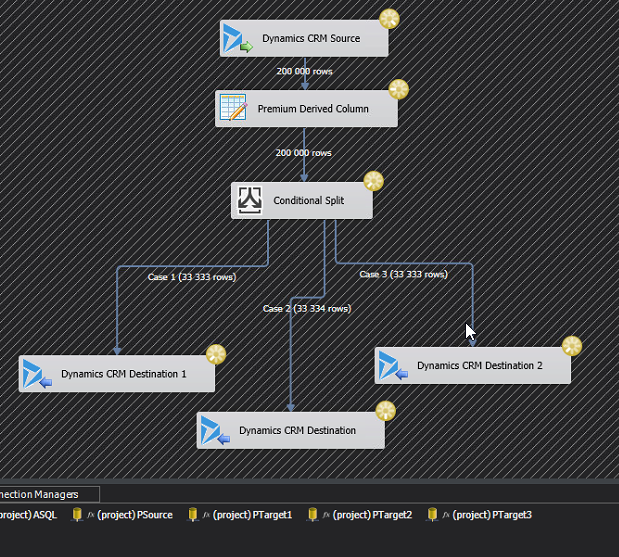
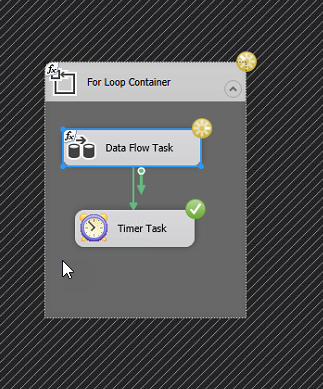
Now it is time to build the actual flow. If you’d normally have a Source and a Target, it will now look something like the image below, which I will explain.
First of all, the Premium Derived Column creates a new column which simply contains the row number. It will look something like this:
I like to use the components that are available in the Productivity pack from Kingswaysoft, and this Premium Derived Column is one of these. In this case I think it is actually equal if you use IncrementalValue() or RowIndex(). I think you can create this logic with a normal Derived Column too, it just has less features.
Next we need to create a Conditional split that divides the rows evenly between the three destination components. This is done using the mathematical operator modulus which is written using the “%”-sign. For those that didn’t study this in school, it simple means “the rest” in a division. For instance 5%3=2, if you divide 5 by 3 you will get 1 and a rest of 2. What we will do, is assign RowNr%3 == 0 to Case 1, RowNr%3 == 1 to Case 2 and the rest to Case 3. That should divide them evenly. It looks like this:
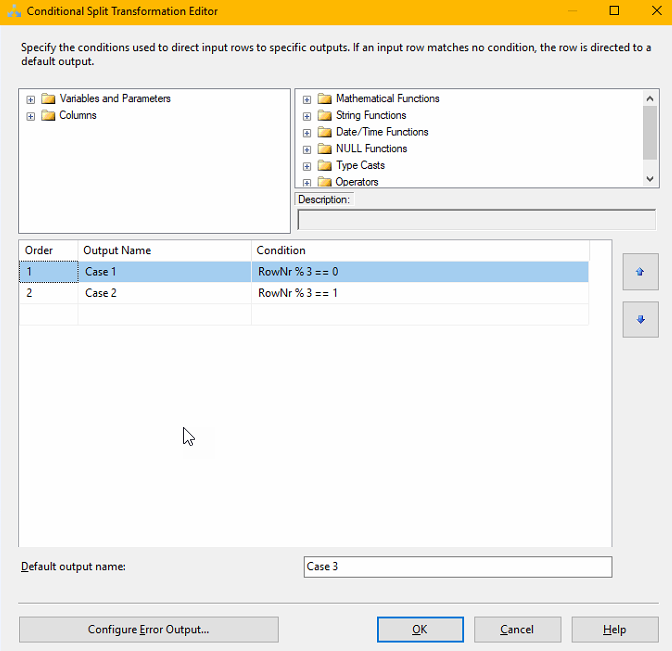
You then create the three destination components. I typically create one first, copy it and change it, as that is faster. Make sure that you set the Connection Manager to the three different Target Connections.
I also recommend that you fiddle a bit with the batch size and the number of threads and test out which gives the best results for you and the entity and action you are working on. There is no one answer here. I would typically start at Batch 10, Threads 16.
Tuning DataFlow property settings
If you back out to the Control Flow view and right click on the Data Flow you have created, there are some other interesting setting you can twirk.
DefaultBufferMaxRows – 10 000
DefaultBufferSize – 10 485 760 (10MB)
EngineThreads – 10
These can also be tuned to allow for the Data Flow to handle more rows, more memory and use more parallell threads which of course will make it faster (if that is the bottle neck, typically not when working with Dynamics)
What I have found is changing the maxrows to 100k, the buffer size to 100 MB and engine threads to 32 will not hurt but you can find several other blog articles specializing in SSIS that discuss this.
Crude throttle handler
What I have noticed is that many of my Dataflows simple seem to grind to a halt after 400-600k rows read from Dynamics. Not sure if it the read or write part that is causing this but what I figured is that probably the most pragmatic way of solving this would be to create a loop that runs a data flow that is limited in the number of records, typically 400k, wait 5 minutes then iterate. Smartest version is of course to have a control variable which checks to see when when there are no more rows and then breaks the loop, simpler version is to just loop n number of times to cover the amount of data you are trying to move, ie. number of rows per iteration x number of iterations. It would look something like the picture to the left.
If you would like to refine the loop a bit to make it more automatic, create a variable of type Int, for instance RowCount, set the initial value to be 10 or something different from 0. Then set the EvalExpression to “@RowCount > 0”. After this add a RowCounter control to the Data Flow and connect this to the variable RowCount. When the Data Flow runs and returns 0 rows, it will run to the end, the EvalExpression will evaluate to “False” which will cause it to break.
Using this technique, I am able to remove several million records in just a few hours. With one of these jobs I managed to remove 20 GB of structured data in less than two days (no attachments or similar, just records). By adding more application accounts and of course both to the source and particulary to the destination side, you can increase the speeds you are getting.
I do also advise you to be on the lookout for Kingswaysofts new version which I think will come soon, and do as I, make sure to always download both the Dynamics and Productivity Pack. I have read that there are great things coming to the productivity pack!
by gustaf | Jun 6, 2018
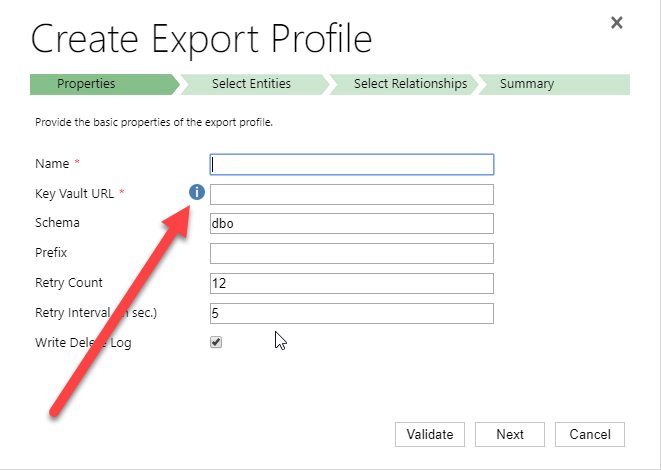
Setting up Dynamics 365 Data Export Service requires a Azure KeyVault to be set up which is typically done using a PowerShell script which can be found in the Data Export Service setup wizard. However, if you run into issues setting this up, it might be easier to do this directly in Azure by minimizing the steps of the scripts. This was a tip that my friend and Business Solution MVP Scott Durow recommended. He mentions this in his very instructive video, but doesn’t actually show how, so I thought I’d just detail how I made it work.
First some background. The reason why I even started investigating how to do this manually was that when I tried running the PowerShell script supplied by Microsoft in the wizard.
 |
| Press the “i” icon to get a window containing the PowerShell Script that Microsoft recommends for setting up the Key Vault. |
When running the PowerShell script both as myself (not a global admin) and asking a global admin to do it, it failed in the latter parts. The key vault was created by some of the access policies seemed to be missing and it just didn’t work. My users rights in Azure was Contributor in the Resource Group, and it was a bit interesting cause the global admin and I got different error messages, but when I finally managed to create the key vault manually, I could do it all with my user, so it didn’t seem I was missing any rights to do it.
First step is to make sure you have all your data straight. The power shell script is good for this. Check out Scott clip if you want to know how to find the different strings. He shows it very clearly.
Just copied from the PS-Script:
$subscriptionId = '<subscription ID>'
$keyvaultName = 'MyVault'
$secretName = 'MySecretName'
$location = 'North Europe'
$connectionString = 'Server=tcp:<db-name>,1433;
Initial Catalog=<catalog>;
Persist Security Info=False;
User ID={your_username};
Password={your_password};
MultipleActiveResultSets=False;
Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;'
$organizationIdList = '<DYN365GUID>'
$tenantId = ‘<AZURE TENANT ID>‘
The highlighted parts have to be replaced by your settings. I will use these variables to have something to reference to further in this article.
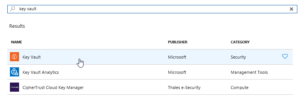 |
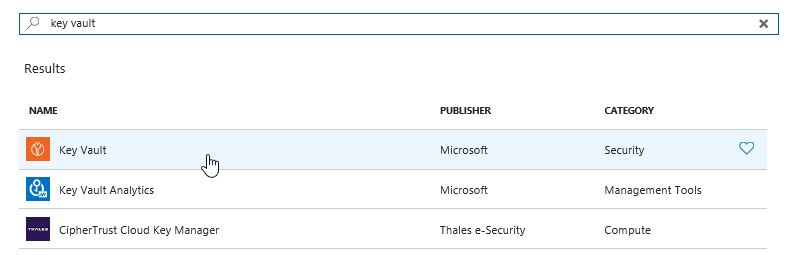
| Search for Key Vault and add the “Key vault”, the top one in this picture |
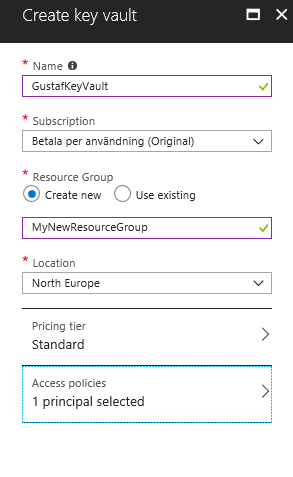
Then we have to set it up. Not so tricky if you have worked with Azure before. Consider if you want to work in an existing Resourcegroup or if you want to create a new one. Typically you need to have Azure SQL services running as well so it might be good to keep them all together to be able to see the costs and control who has access why a resource group might be a good idea. But that should hence already exist. If not, you can create it. I would recommend keeping Azure SQL and Key vault in the same, not sure if it actually works in different resource groups, probably does, but I haven’t tested.
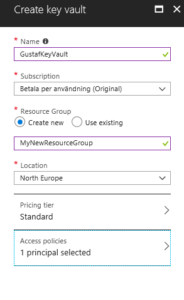 |
| Creating the key vault – in this case I am creating a new resource group, normally it would already exist |
Azure will add you as the default principal with access to the key vault. We will add Data Export Service to this later. For now, just create it.
Now we need to open the Key vault and select the “Secrets” section in the menu on the left hand side and press the button:
“+ Generate/Import”
Then you have to enter you Secret name ($secretName) and the connection string ($connectionString) into the value.
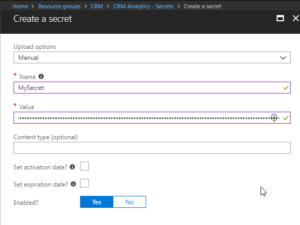 |
| Creating a secret – $secretname in Name and $connectionstring in Value |
Press “Create”.
You should now return to the previous screen and see a row for your secret.
Select it.
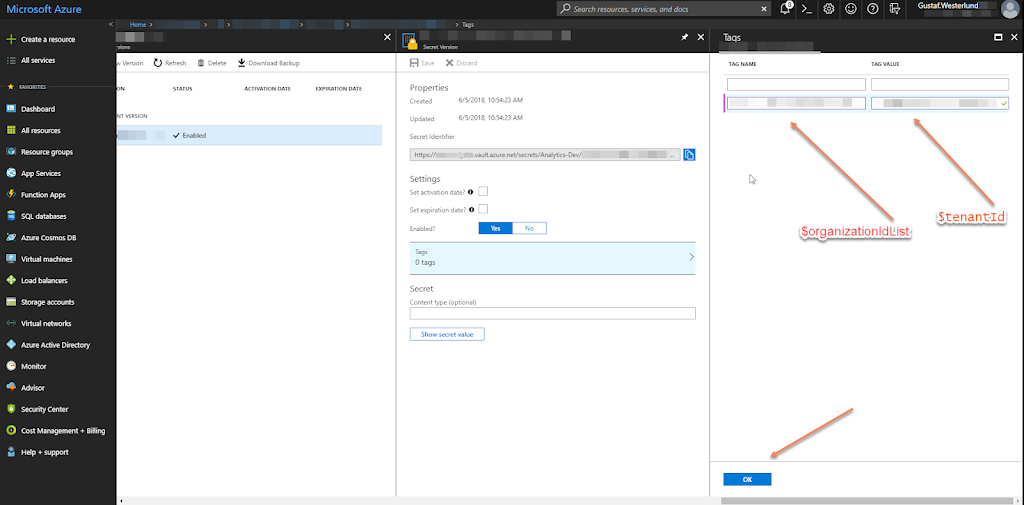
It should open the settings panel for the Secret, press the “Tags” part which is located in the middle and add a tag which has $OrgIdList ($organizationIdList) as the key and Tennant ($tenantId) as value. I have blurred them out below as they are rather private.
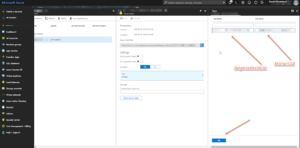 |
| Adding a tag with OrgIdList and tenantId to a Secret |
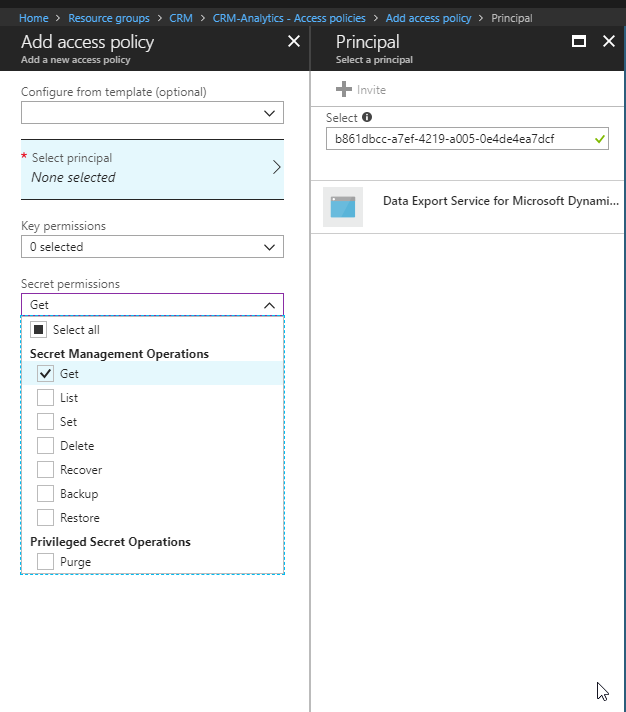
You then need to go back to the Key Vault and click on the “Access Policies” menu item, you should then see yourself as the principal as this was set when we created the key vault. We now need to add Data Export Service as a valid Principal with read access rights.
So click “Add”, click “Select Principal” and search for “b861dbcc-a7ef-4219-a005-0e4de4ea7dcf” which is the ID for Data Export Service. It should show up like this:
It needs to have “Secret Management Operations – GET” permissions and nothing else.
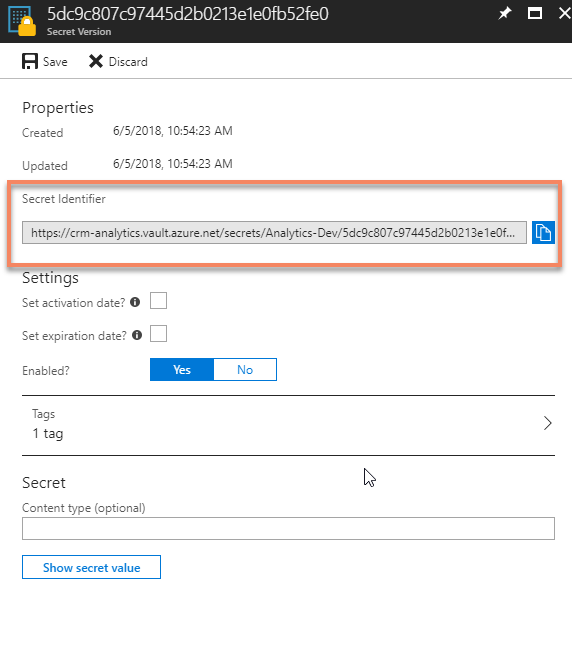
Now, go back to the Secret and copy the URI to the Secret.
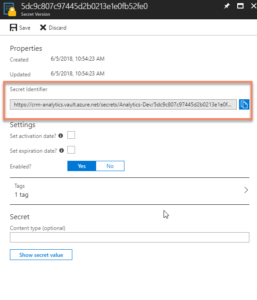 |
| Getting the URI for the Key Vault Secret |
Paste it into the Data Export Service Wizard field for Key Vault.
Fill in the other information and press validate. Hopefully it will work out well!
Some issues
Being too cheap with the Azure SQL level
If you don’t go for a Azure SQL P1 and choose a lower tier, you might get this warning:
We tried an S0 for our Dev environment and tried to sync a couple of million records and that just didn’t work, we got tons of errors. We upgraded the ASQL to S2 and then at least we didn’t get any errors. We are planning for P1s in UAT and production.
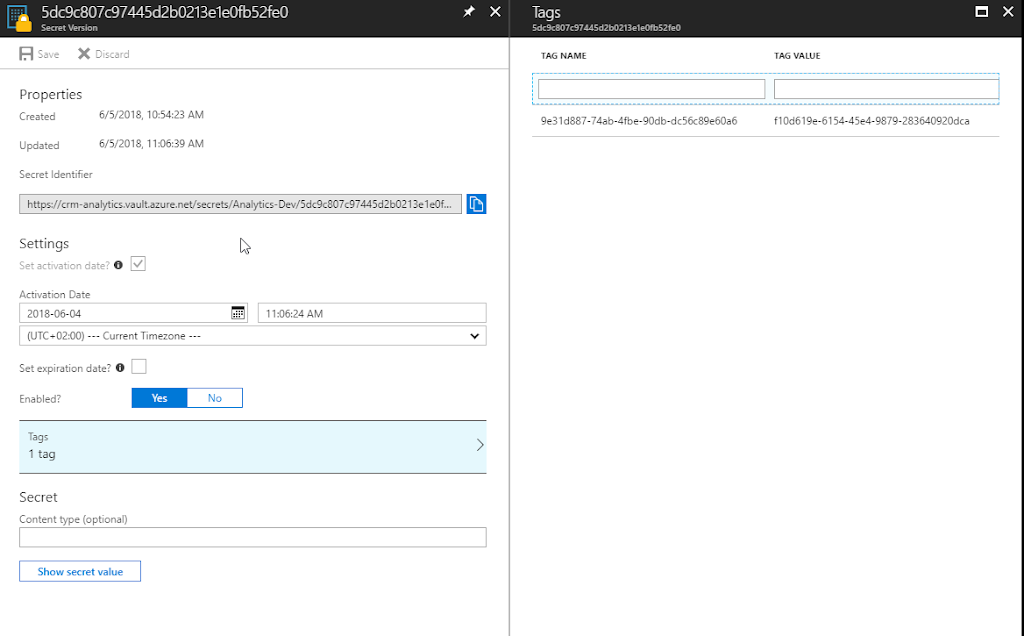
Might have to set activation date on secret
Seems that you might have to set an activation date on the secret. Not sure why this is, the PS-script doesn’t seem to do this. But not very hard.
 |
| Added activation date on the Secret from June 4.th |
Using Database schema that is not created
The default database schema is “dbo” in the Data Export Service Wizard. If you change this to something else like “crm” and you haven’t created this in the database, you will get an error. It is simple to fix, you just have to go into the database and create the schema. To create the schema “crm” open a query and run:
CREATE SCHEMA crm
For more information on how to create schemas, check this site: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-schema-transact-sql?view=sql-server-2017
Once the schema has been created, there should be no problem using it, as long as the user has permissions using it.
I hope this works for you. If you have any questions, don’t hesitate to leave a comment.
Gustaf Westerlund
MVP, Founder and Principal Consultant at CRM-konsulterna AB
www.crmkonsulterna.se
by Gustaf Westerlund | Jun 29, 2015
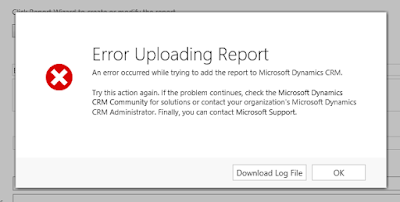
Creating reports in SSRS and uploading to CRM can be a pain sometimes. The report works just fine in SSRS (well, the CRM-Autofilters don’t of course, but still), but when trying to upload it you get this fine and informative error message:
Not very helpful, so maybe the log file is:
Unhandled Exception: System.ServiceModel.FaultException`1[[Microsoft.Xrm.Sdk.OrganizationServiceFault, Microsoft.Xrm.Sdk, Version=6.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35]]: An error occurred while trying to add the report to Microsoft Dynamics CRM. Try adding the report again. If this problem persists, contact your system administrator.Detail:
<OrganizationServiceFault xmlns:i=”http://www.w3.org/2001/XMLSchema-instance” xmlns=”http://schemas.microsoft.com/xrm/2011/Contracts”>
<ErrorCode>-2147188072</ErrorCode>
<ErrorDetails xmlns:d2p1=”http://schemas.datacontract.org/2004/07/System.Collections.Generic” />
<Message>An error occurred while trying to add the report to Microsoft Dynamics CRM. Try adding the report again. If this problem persists, contact your system administrator.</Message>
<Timestamp>2015-06-29T14:16:35.6330269Z</Timestamp>
<InnerFault i:nil=”true” />
<TraceText i:nil=”true” />
</OrganizationServiceFault>
If you are not very used to reading this, the important part is:
An error occurred while trying to add the report to Microsoft Dynamics CRM. Try adding the report again. If this problem persists, contact your system administrator.
Not really sure who that guy is. Anybody know him or her please leave a comment.
Ok. So, maybe the SSRS tracelogs have something. Let.s go to there, in my case it was in this path:
C:Program FilesMicrosoft SQL ServerMSRS11.MSSQLSERVERReporting ServicesLogFiles
Yours is probably something similar.
The last entries in the log were:
library!ReportServer_0-2!1870!06/29/2015-16:28:36:: i INFO: Call to GetItemTypeAction(/Contoso_MSCRM/CustomReports/{f27fb971-691e-e511-93fe-00155d01ac02}).
library!ReportServer_0-2!1870!06/29/2015-16:28:36:: i INFO: Call to CreateReportAction({f27fb971-691e-e511-93fe-00155d01ac02}, /Contoso_MSCRM/CustomReports, False).
processing!ReportServer_0-2!1870!06/29/2015-16:28:36:: e ERROR: Throwing Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: , Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: Exception of type ‘Microsoft.ReportingServices.ReportProcessing.ReportPublishingException’ was thrown.;
library!ReportServer_0-2!1870!06/29/2015-16:28:36:: i INFO: Call to CreateReportAction({f27fb971-691e-e511-93fe-00155d01ac02}, /Contoso_MSCRM/CustomReports, False).
processing!ReportServer_0-2!1870!06/29/2015-16:28:36:: e ERROR: Throwing Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: , Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: Exception of type ‘Microsoft.ReportingServices.ReportProcessing.ReportPublishingException’ was thrown.;
library!ReportServer_0-2!1870!06/29/2015-16:28:36:: i INFO: Call to CreateReportAction({f27fb971-691e-e511-93fe-00155d01ac02}, /Contoso_MSCRM/CustomReports, False).
processing!ReportServer_0-2!1870!06/29/2015-16:28:37:: e ERROR: Throwing Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: , Microsoft.ReportingServices.ReportProcessing.ReportPublishingException: Exception of type ‘Microsoft.ReportingServices.ReportProcessing.ReportPublishingException’ was thrown.;
Again we are all filled with joy and happiness as it is all too clear what is wrong… Well, if you can see it, please tell me, because I can’t. The logg seems to be a dead end as well.
And I am all out of logs to look for, I don’t really think the IIS-log will help.
However, all hope is not lost and we must trust the force, and the force says that the problem is probably that we have some UI component that is weird or that there is some reference that is bad. So I went back to my report, and just for the hell of it, not that I use it that much anyway, pressed the “Preview” tab, and behold, I had replaced a datasets query with a new SQL statement and missed that a tablix had a reference to a field.
So, these are some ways to troubleshoot a report. Maybe I should have done it the other way round. 🙂
Gustaf Westerlund
MVP, Founder and CTO at CRM-konsulterna AB
www.crmkonsulterna.se
by Gustaf Westerlund | Jul 3, 2014
When working with CRM systems in non-English countries you often need to take certain aspects into consideration that might have very dire consequences if set incorrectly, one of these is the database collation.
The collation of the database is simplified how it orders characters. For those of you not used to working with multi-language installation with odd characters this might not be something you have considered. As I am Swedish let me give you an example. The Swedish alphabet looks as follows:
abcdefghijklmnopqrstuvwxyzåäö
However using the collation that is default when using English as language in an on premise installation, which is “Latin1_General_CI_AI” (CI= Case Insensitive, AI = Accent Insensitive) the Swedish alphabet would be sorted as follows:
aäåbcdefghijklmnoöpqrstuvwxyz
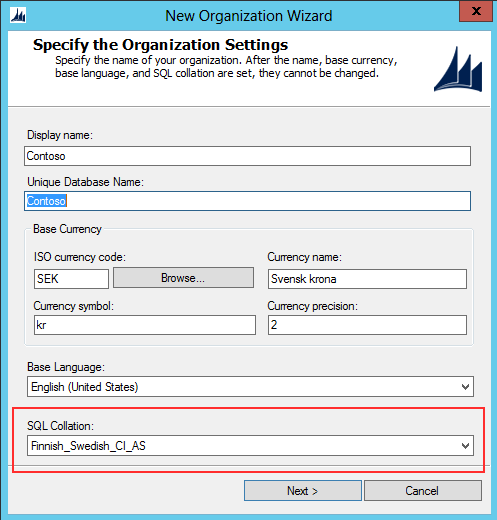
This is why when installing an organization that is to be used in Sweden, despite the fact that you might have chose to have English as base language, that you need to select the collation that sorts the Swedish characters correctly which for CRM is “Finnish_Swedish_CI_AS”.
 |
On-premise setup of CRM – ability to select Finnish_Swedish_CI_AS collation
despite using English as base language |
When setting up an organization in CRM online, you cannot chose the collation explicitly which is regrettable and I hope there will be some advanced setting in the future which will allow for this when provisioning new organizations. Check out what happened when I provisioned a new organization in English indicating that I was in Sweden.
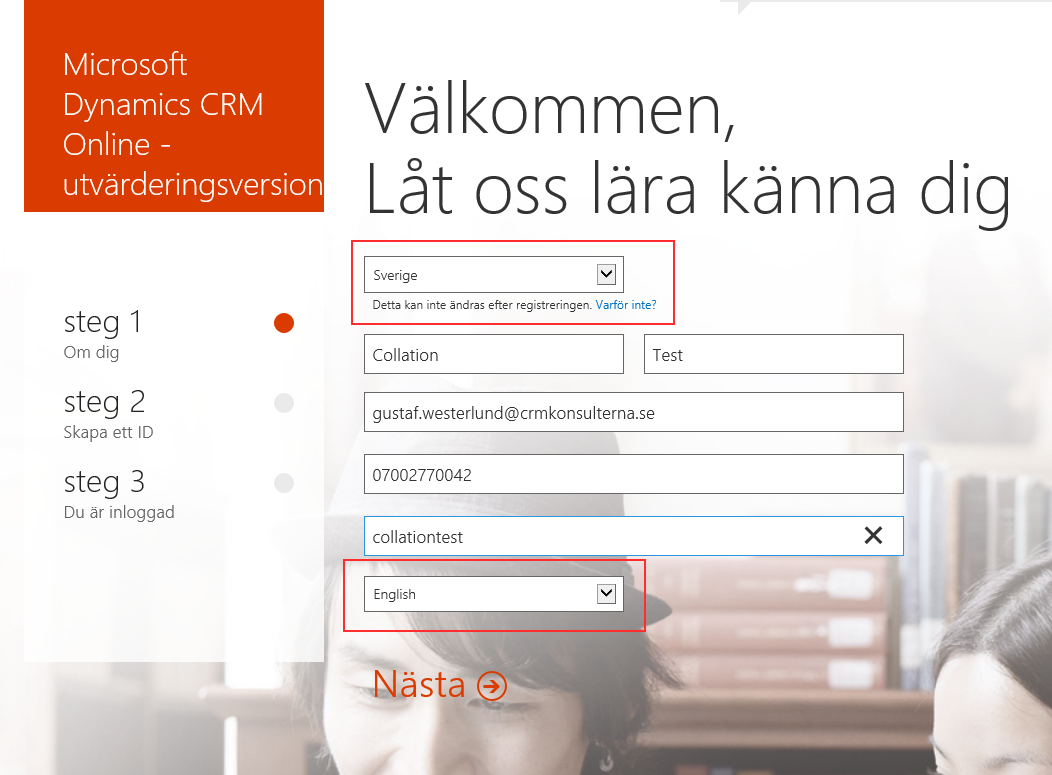 |
| The first pick list is for country – I selected “Sweden”, the last is for language and I changed from “Swedish” to “English”, which were the two only options. |
After going through all the three steps you are shown a last instance configuration step.
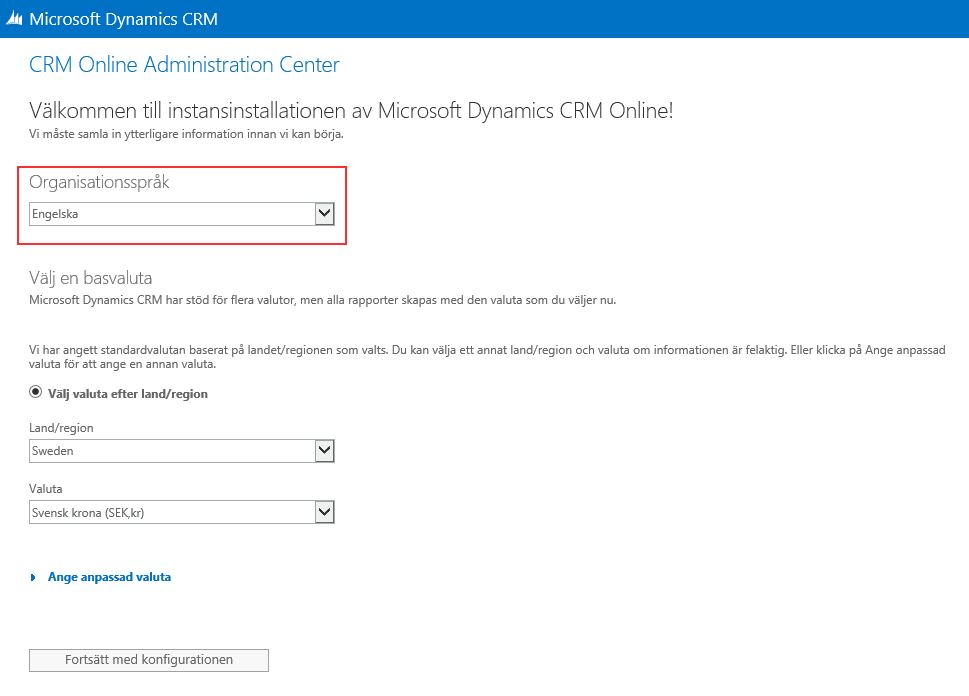 |
| In the instance configuration screen you can select the base language but there is no selector for collation. I selected “Engelska”, which if you have any imagination, means “English”. |
After, a few seconds, yes, the new installation process is great and really fast, my org is up and running and I jump in to contacts and create to contact and check out the sorting. Any bets?
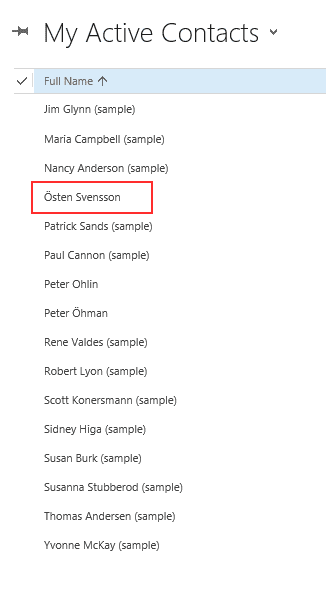 |
| As you can see selecting English language will also implicitly select Latin1_General _CI_AI as collation which is incorrect from a Swedish perspective, I would have liked to see Östen Svensson at the end of the list, not sorted as “O”. |
Collations are integral to the configuration of the SQL database and there are many features of the database like ORDER BY and indexes that depend on the collation why changing collation of a database is very very tricky. It is actually so tricky that it is not supported if you manage to do it with an on-premise, which I have heard rumours of that some people have managed to do. On an online you cannot request it. You will be recommended to migrate the data from the old org to the new.
So let’s hope Microsoft will enhance the provisioning experience for CRM Online so that it includes a selector for collation. In the meantime, if you need a special setup, like the one I tried to set up above, English with Finnish_Swedish_CI_AS collation on CRM online I would suggest contacting Microsoft Online support to get their assistance in setting up the instance correctly. Hopefully they can assist in this.
And on another note, I was awarded the MVP award for the third year! A great honour and this very article is dedicated to the very award as two of my fellow MVP:s Shan McArthur and Niel Benson provided with background information to this article. I extend to you a humble thanks!
Gustaf Westerlund
MVP, CEO and owner at CRM-konsulterna AB
www.crmkonsulterna.se





Recent Comments