On the page in Microsoft docs where they discuss API Service Protections there is towards the end of the page a part which gives some recommendations. Some are great, like the recommendation to use many threads and remove the affinity cookie, however when I read it I really bounced at the recommendation that batching shouldn’t be used. That just didn’t rime with my experiences of doing heavy dataloads to dataverse. So I thought I might just test to see if it was true or not by creating a simple script in SSIS with Kingswaysoft. My results, using batching compared to not using it gives more than a 10x performance increase. Continue reading to understand more about how I tested this and some deeper analysis.
Parameters and excel
The first thing I did was to create an excel sheet for storing all the results. I really did have to think about the different parameters that could affect the result, so I chose the following columns:
Dataload – how many records. This needed to be a bit larger to make sure that the throttling time of 5 min was passed.
Operation – Different dataverse operation take different amounts of time. For instance, creates are typically rather fast, but deletes, depending on table, can be a lot slower as the platform might execute cascading deletes based on one single delete. For instance, if you remove a contact with 100 tasks connected to it with the regarding relation set to “parental” or “cascade delete” it will actually remove all the 100 tasks. If set to “remove link”, the platform has to make an update to each of the tasks, removing the link. There are also special operations like merge which are rather complex.
Table – There is a large difference between the different tables. Some of the OOB tables have a lot of built in logic and really small non-activity custom tables can be a lot quicker to create, update or delete.
Threads – How many threads were used.
Batch – The size of the batches being used.
Duration / Duration (ms) – Duration is where I input the duration as a normal time. I created a calculation to calculate the corresponding amount of milliseconds.
Time per record (ms) – This is the division of the duration in ms with the total number of records. During this first test, I always used 100 000 records as the dataload, but it could be interesting in the future to see the differences between different dataloads, with all else being the same. This is also the main output from this test.
Strategy – It is possible to have different strategies. In this first version I just ran everything at once, hence I called the strategy “All at once”. Different strategies might be “5 on, 5 off”, meaning that you design the script to run superfast for 5 minutes, the throttling limit, and then stop and do nothing for 5 minutes and then loop this. Not always possible to use that kind of strategy, but for massive deletes of for instance market list members (cannot be removed with bulk delete) that might be an option.
API – There are currently two APIs that can be used. The new WebAPI which uses JSON payloads and the older SOAP API which used XML payloads. It stands to reason that the smaller JSON payload should cause the WebAPI to be faster than the corresponding SOAP API. However SSL encryption also causes the data to be compressed, which might make these differences smaller than expected. There is also a server side aspect to this, as the APIs will run through different parts of the code on the server side which could affect the performance.
No of columns – How many columns are being sent to the API. Of course there would be a difference if you send a create message with 3 columns compared to 30. Hence this is a relevant point. It is still a bit rough, as there is a huge difference in creating a boolean record, a 2000 character nvarchar or a lookup. This could also be something that was adapted.
Existing records – How many records existed in the system prior to running this? Not sure if this makes any difference, in other words, everything else equal, would it take more time to write 100k records to a system with 0 records or one with 10M records? As I don’t know, and cannot rule it out, I added it.
Latency (ms) – Daniel Cai, Founder of Kingswaysoft, always recommend that the SSIS script with Kingswaysoft be run “as close as possible to the dataverse”. That does in other words imply that the latency to the server affect the performance. Do calculate this, I used diag.aspx from the computer running the script.
Location – Which geo is the instance located in. This is more for general information, the latency is really the important factor here. The throughput might also have some affect if you are using a really bad line to the dataverse. I was using a wired 1 GBit line. In this test, I was using an instance I got hold of as MVP, which is located in the US and my own stationary computer at home (a AMD Ryzen 9 3900X 12-Core Processor 3.79 GHz with 32 GB of memory). Hence the latency was rather high and not in line with Daniel Cai’s recommendations. It is hence also something to investigate further.
No of users – As I, and some others in the community have described, throttling is based on a per-user and per-front end server basis. Hence utilizing several service principals/application users can effectivly multiply the throughput. In this test I used just one.
Instance type – It is well known that sandbox instances do not have the same performance as a production instance. If you find Microsoft support on a happy day and you are working with a larger (no of licenses) instance, you might also get them to relax the throttles a bit, especially if you mention that you are doing a migration. As these factors strongly affect the performance of large dataloads, I did have to add this. During this test I was using a non-enhanced production instance, in other words, a production instance on which no throttles had been relaxed.
DB Version – The final parameter that I thought might affect this is the actual version of the dataverse instance. As improvements and god forbidd sub optimal “improvements”, can cause enhancements or degradations of the performance, this is necessary to document.
SSIS/Kingswaysoft setup
For setup of create tests in SSIS with the Kingswaysoft addons I used a dataspawner (productivity pack) to generate the data. I then just sent this directly to the CDS Destination.
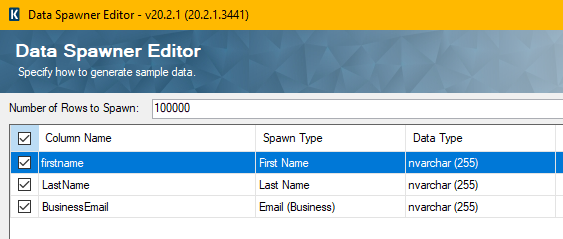
And the Data Spawner config:
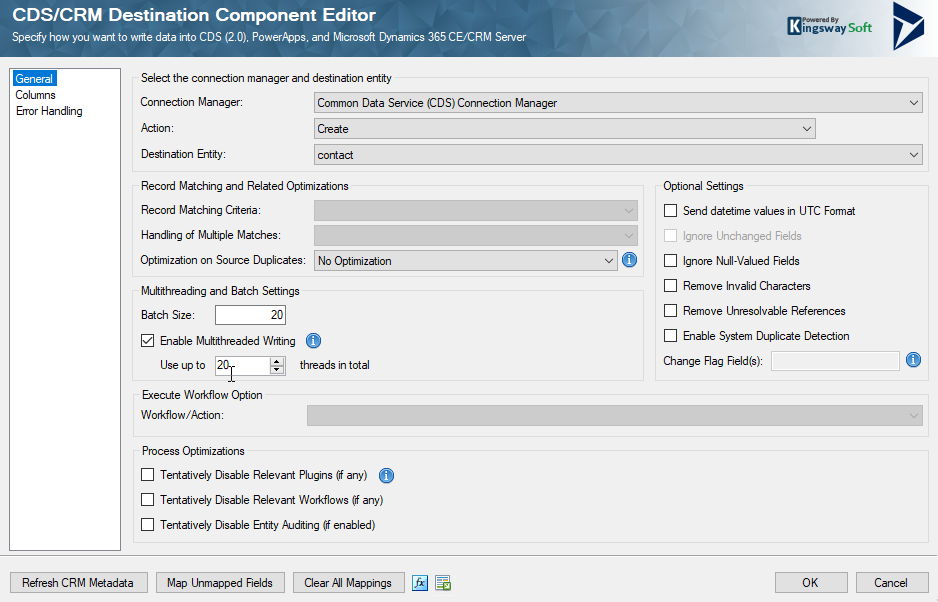
And the CDS Destination config
The main changes done in this case were to the parameters “Batch size” (set to 20 in the picture above) and how many threads to use (also set to 20 in the picture above).
After each run, I checked the log from SSIS to see how long the entire process took. Due to the fact that I have a computer with many threads and for this case, enough memory, it is my perception that most of the threads allocated were also used.
Results
What are the results? This is a picture of the excel:
As you can see I did try both Create and Delete operations, but the results are rather obvious.
20 threads/20 per batch of both create and delete, took around 45 minutes
Reducing to 16/10 made only a minor difference – 48 minutes
Microsofts recommendation of not using batching, ie 20 threads/1 batch – took over 10 h, both for delete and create.
Using only 1 thread with 1 batch was more or less the same as using 20/1
1 thread with 20 in every batch (1/20) took almost 5 h, which is around half the 1/1 or 20/1
I think the results clearly show, that Microsoft docs are currently incorrect in their recommendation to not use batching. Perhaps they will update this soon. From an entitlement perspective, one needs to understand the additional cost of the “batch unpacking” request that is made. With 20 in every batch, this is an overhead of 1/21 but if you would lower the batches to 4, it would be 1/5. Hence using as large batch as you can, without loosing performance, is generally what I would recommend.
As I have implied in this article, there are a lot of other parameters to investigate in the API. I have a hunch that a create with 10 lookups compared to 10 textfields, will also make a significant difference, but I will need to test it.
Also do consider the request timeout. When working with complex and large batches, one request may taker quite some time. You will know, however, as it will return a timeout exception if you exceed it. Note that some records in that batch may have been written anyway. Just that your client wasn’t waiting around for the answer.
I do also encourage others to try out other parameters in the API. What is really optimal from many different aspects. From a mathematical perspective this can really be seen as a multidimentional surface where we are attempting to find the highest points. I have now started this journey, and I hope it was an interesting read. Please leave a comment, if you have any experience to share or just want to comment.
Microsoft recently (in February) published some updates to their documentation regarding Service protection API limits or as they are sometimes referred to, throttling. Some of these, like the new recommendations on how to handle batching are rather interesting and I thought I’d give my 2 cents about this. They are also eluding a bit regarding how the network infrastructure is set up for the deployment and how to optimize when handling larger workloads using the affinity cookie setting. I did find this rather interesting too.
In short, within a 5 minute sliding window, you cannot exceed the following for one specific user.
Not more than 6 000 requests.
Not more than 1 200 (20 minutes) execution time – equal to 4 parallell processes if running at full capacity
Not more than 52 request at the same time (concurrently).
Generally, if you do not use batching, you would typically run into the first (1) or the third if running unlimited threading. If using a connection pooling with 52 connections, then you probably run into the 1:st, and if you use complex request that cause cascading behaviours or batching, then you typically run into the second (2). There are exceptions that match these. Do refer to the official docs above for details about that.
Now to the interesting part. There is a new section that is attempting to tells us how to maximize throughput. First of all, I think this is great. We really need this and we need Microsoft to tell us how to not only use the platform, but how to efficiently use their platform.
“Let the server tell you how much it can handle” This section is interesting as it recommends a rather complex approach to how to work with performance. As they further down recommend using threading, they essentially recommend building logic that dynamically increases and decreases the number of threads as the platform informs you that it has capacity. This brings me back to university math, and trying to figure out the derivative of an unknown function by sampling and finding the local max. I do however, think this is a rather tall order to recommend to your average developer. But it would be a great community tool, so feel free to build it. Consider the challenge set. Best would be if Microsoft included this in the SDK of course.
“Use multiple threads“ In this part they recommend using multiple threads. This is also my experience that this is a good idea as the processing time and latency per package causes certain delay on a per-message basis. By utilizing multi-threading with multiple connections, this overhead can be reduced. As there is a limit of 52 concurrent connections, I would recommend using a maximum of that amount of connections/threads per user.
Avoid batching Now this is really interesting. The previous recommendation was to use batching to be “nicer” to the API and get increased performance. The recommendation now is the direct opposite. This is based on the fact that the overhead in a WebAPI JSON-message is significantly smaller than that in a SOAP message and that this will reduce the difference between using batching and non-batching. They do, however, recommend using smaller batch sizes still. This is also my experience when working with Kingswaysoft. I typically (it depends on the instance and which table I am using) start with 16 threads with batches of 10 or 20. This has typically given me the best performance, with performance of +300 records/s.
There is also a comment about the fact that the using batching does not bypass the entitlement limits, ie. 20 000 API calls/24 hours for an enterprise user/100 000 API calls for all non-licensed users and so on. See more on the Entitlement limits based on which license you have here. Hence this calculation is done by after exploding the batch on the servers. This is also news to me as I previously was told that batching was exactly the way to go to limit the amount of calls.
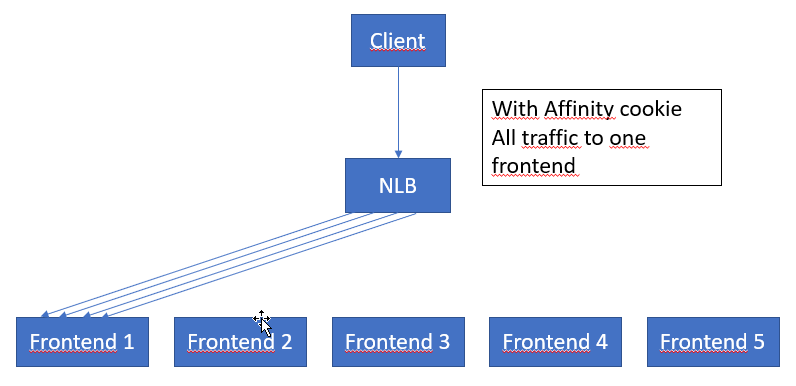
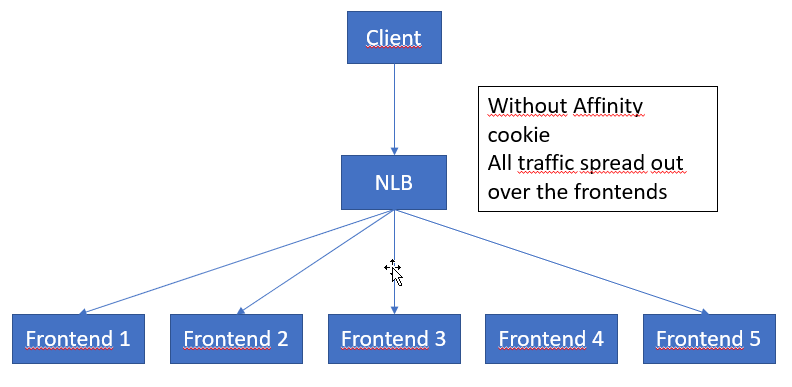
Removing the affinity cookie – server multiplexing The details being eluded to in this section are very interesting. If I understand it correctly, the logic is as follows:
The point being that, shutting off the affinity cookie int the HttpClient will allow for more wider use of all the servers in the node (the entire setup of all the Frontends, backends, NLB etc.)
What I do wonder, is if it would be possible to store the Affinity Cookie, and hence pool it on the client side. As each time you need to hit a new front end you will loose some time while it warms up your instance, and it would hence be advantageous to be able to more tightly control this. Maybe even this could be another community tool for someone interested? I also think, I havn’t tested this, that you will get better results when working with removed affinity cookie if you do use batching, at least until all the frontends have been warmed up to your instance.
Do also note a very important sentence; “This increases throughput because limits are applied per server“. We do not know how many servers are used in a node frontend, but probably more than 10. Removing the affinity cookie could hence increase performance by at least one order of magnitute.
User multiplexing As all API limits are calculated on a per-user basis, another way to increase performance is to use what I like to call user multiplexing. This means that operations are done using several different application users at the same time. There is of course some admin work that needs to be done to set these up, and there is no OOB way of doing this but with SSIS and Kingswaysoft it is rather straight forward; just create several connections, one per user, configure them per user and then use the “Balanced Data Distributor” which can be found in the productivity pack to spread the data to different destinations that are using the different connections.
My tips My tips for getting good performance, for large scale datasets, are hence the following based on these new facts:
Continue to use batching, but don’t use huge batches. Probably around 5-20 will be ok.
Use multithreading. I typically use around 16, but that was before I knew about the removal of the affinity cookie. Hence I would recommend 16 per server. But I cannot tell you how many servers there are.
Use the remove affinity cookie setting, and if possible, figure out some way of pooling the affinity cookies instead.
Make sure your application can handle the exceptions regarding the API-limit and have some reasonable strategy for working with them. I have found that blasting the API for 5 minutes at max speed, then backing off for 5 minutes, then going full throttle again for 5 minutes, has given me better throughput overall than “being nice” and just finding the “right” speed to use to not be throttled. Not sure this strategy will work in the long run though.
Use application user multiplexing.
Suggestions to ETL vendors and others My suggestions to ETL vendors and others who build connections to Dataverse that require high performance are:
Start by visualizing the affinity cookie setting so that it is possible to set this as wanted.
Include multithreading, batching and application user multiplexing into the standard dataverse connections.
Figure out if there are an points to pooling the affinity cookies, and if so, include this into the connection.
Make the connection auto-optimize with the data it is currently sending. Ie. how many threads, size of batches, size of affinity cookie pool and number of application users to utilize.
Have different strategies for utilizing application users instead of just spreading the data evenly, it could be that one is used until it receives an exception an then it is put on hold for 5 minutes and then another is being used. Or a combination of these two if there are five application users, 3 might be used for data transfer, and two on hold in case one gets an exception and needs to be put on hold.
I hope this has given you some insights and that my 2 cents got you this far. Feel free to leave a comment if you have an questions!
(Updated) Microsoft recently released some throttling that have been causing some stir in the community, especially since the latest throttle, the concurrency throttling, was not very openly announced, some partners and customers were hit rather hard by it as it affected their abilities to manage large dataloads in the system.
Now Microsoft have announce another API based limitation which is based on the users and the type of licenses the have. You can read some about it here if you like. This article will discuss what this means and my personal view of the good, the bad and the ugly of it.
First of all we need to understand what it is. It is a API limit that will be set per user and based on the type of license that the user is allocated. The highest is if you have a Dynamics 365 App user license, like Sales, Customer Service or similar, which will give you 20 000 requests per 24 hours. The lowest is a Power App – Per App license which will give you 1 000 requests per 24 hours. Note that these are connected to the user and not summed/aggregated to the instance level (allthough I would think that would be a good idea). Well, really, the lowest of them all are Application, Non-interactive or admin-users that don’t use a license as these will be allocated 0.
I have not seen any UI for this yet, so I don’t know how this will look, but what the page is saying is that API-calls can be reallocated from normal users to application users/non-interactive users. (UPDATE – See update at the bottom regarding this, thank you observant readers!) Not sure if it will also be possible to reallocate API-calls between normal user and another normal user.
There will also be an additional SKU for buying 10 000 additional API calls per day that can be allocated to a user.
The Good
What is good about this then you might ask? Well, I think it is fair. Large customers pay a lot of money for their instances and usually use it a lot with a lot of integrations. It is only fair that they are allowed to use the API:s more than a small customer who has created some super duper application that blasts Dynamics with massive amounts of calls. The small customer can still do this, but they just have to pay a bit extra for those API-calls if they arn’t covering that with their users. I also hope that this might enable Microsoft to relax the currently rather tight throttling on the API:s a bit.
According the the licensing documentation in general, existing customers will not be hit by this until October 2020, in other words, more than a year from now. This will hence probably only now affect new customers.
The bad
This implementation certainly has some bad parts. The most obvious is the too stringent connection to users which makes it weird. I don’t know how this will be managed in the UI but let’s say we have an instance with 500 users mixed Sales Enterprise, Customer Service Professional and Team Member. We also have 10 application users that are used for Portals, Forms Pro and custom integrations to many other systems. Each integration using a separate integration user to reduce the attack area in the unlikely event of a hacker attack. So what we will need to do is to first figure out how much API-usage we are using for all the normal users (for instance via PCF:s, Flows, Plugins, Workflows etc) and all the integration application users. Currently the https://admin.powerplatform.microsoft.com does not give us this granularity. There are indications but in this case one would need deep granualar data, preferably with trend analysis.
Another part of this that could be done better is the “buying addional API-calls”. Why not just adapt the method used in Azure? In other words, you pay as you go. With this current method, you have to know beforehand how much a particular user will use and if you overshoot the user will be shut down causing unnecessary support costs for customers, partners and Microsoft.
I also wonder how this practically is going to be handled? Are admins going to go into each of the 500 user records, reduce the API-calls allocated and move to Application users? If the admin moves all calls, which effectivly will stop plugins, workflows, javascripts with server calls etc how will the error handling of that look?
The Ugly
What is really the difference between something bad and something ugly? I would say that something bad is a design decision that we might dislike or might be disadvantage to the customers, it requires some sort of conscious perspective. Ugly on the other hand is the parts where where, in this case, Microsoft just have forgotten to think about something or neglected perspectives which causes issues for partners or customers. Based on this, I would say that the following are the bad aspects of this;
Timing
Again Microsoft are rolling out a change with a rather short timeframe. They probably feel that a month or two of notice by publishing the article above is notice enough, but they have to realize that many customers cannot act that fast. If you are a small customer with extensive use of Dynamics, for instance if you are using Dynamics 365 in a B2C aspect with a Marketing Automation integration and you are targeting millions of customers with sendouts and hits on your webpage being mirrored to your Dynamics all the time, this will cause some hefty API traffic. And your org might not be very big if you are totally e-commerce oriented.
Maybe only new customers, for now
Lastly I really hope that it is true that the API limitation will not affect current customers, it is not very clear and hence we are left in the dark again. If there is a problem with application users etc not being able to log in, I hope Microsoft support will be ready for the storm that will hit them.
On the other hand, new customers might have tested the system, evaluated the costs and are now faced with this. Not sure that will be optimal either, there is risk of loosing a customer or two there.
Communication
As this is a rather drastic change and may be viewed as a “breaking change” if not the one year grace period mentioned in the licensing in general applies to this. No matter, this should have been communicated very clearly months ahead to remove any kind of doubt from partners and customers. Both via blogs, emails to admins of organizations using Application users/non-interactive users as this should be easy to figure out via telemetry. Currently no one knows exactly when this will hit them/their customers or how they are to manage it.
This is generally very unclear. I shouldn’t have to write an article like this, speculating about what is or isn’t going to happen. If I have problems figuring this out, being an MVP, customers are probably very much in the dark, both existing and new.
Conclusion
In conclusion I think this is a good idea that got rushed. It should have been passed through a couple of more hoops before being launched to get the right feedback. The main things that I think Microsoft should change before rolling this out that, from my perspective, still give the same effect, are:
Aggregate all API-Calls that are counted to a per instance level. It will make it easier to manage, stop the breaking change and make it easier to understand.
Enable admins to add a per-use, after the fact, payment option, (like Azure) for any additional API-calls.
If this is going to be useful or not also is very dependent on the fact that we can reallocate a lot of the API-calls from users to the integration users. For instance, I have a B2C customer with 1M+ API calls per 24/h and if it will not be possible to take the sum of hundreds of users and allocate those to the application users we are using, then this will be a very hurtful change.
In the meantime, I do recommend that you keep a close eye to what is going on within this area as it will most likely affect you if you are running any application accounts, which you probably are, like Dynamics Portal, Forms Pro, Voice of the Customer and many more. If you go into the list of users and change view to “Application users” (or whatever it might be called in your language) you will see the list. I think Micrsoft will make some changes, or some announcements to this before October 1. Let’s see what.
Update 2019-09-04
There has been some chatter going around regarding this and do note the comments below which include interesting links and good thoughts. There are some additional points that need to be pointed out. Instead of changing the original article I will continue to add updates like these.
Normal UI usage will count
Initially I did not think that normal UI usage would count towards the API request calls. With “normal” in this case, as an old Dynamics 365/CRM geek, I of course mean a model driven App, but the same also goes for canvas Apps or actually any use of the CDS, what so ever. What this will mean when a user runs out of API requests, will be interesting to see. How many requests are used when the application is used, of course depends a lot on what you do. If you switch on F12 in Chrome you can check the network traffic and see for yourself.
Batching will be your friend
Using batching will from now on not only be a general best practice but also make you save money. If you use tools like Kingswaysoft this is easy to configure, to make sure that you have large batches when for instance doing CUD calls. When writing code directly, you will need to understand how to do this directly. Note that sometimes this will require entire rewrites of the code. I have seen programs off the shore of Orion that you wouldn’t believe with tons of single queries instead of one single call. Most often written by devs who have no or very little experience of writing code towards Dynamics 365/CDS.
Unclear if possible to move API-calls
As several people here and on Twitter have commented, it is probably incorrect to interpret that API:s can be moved from normal users to application users and non-interactive users. This will cause major headaches for some customers which will be struck with lots of additonal costs. Costs that are not very welcome as the per GB cost recently increased 800% hurting especially the larger customers with massive integrations and extensive use of the system. I do, for instance, have a customer that exceeds 1M requests per day 365 days a year. This would require them to buy over 100 addon 10k API requests SKU:s, despite the fact that their 500 users gives them a total of over 5M requests per day, something they will not be using through the UI unless someone is drinking very large amounts of coffee. – NEW Update: This was an incorrect interpretation. You cannot reallocate API calls from normal users.
The price is here
The price for the 10k/24h SKU will be $50/month. This means that for a customer like mine having major integrations causing around 1M API-calls per day, this would cost an additional per month $5 000 or yearly $60 000. I sincerely hope they will relax the throttling to make it worth it. If/when they do, I will read my Macciavelli again.
Update 2019-09-05
First of all I will write a new blog article on this, when the dust settles and we know what is going on. Currently there are quite a lot of unknowns and I wouldn’t be surprised if Microsoft announced a thing or two soon. I have been told that the FAQ will be updated in a couple of days.
Batching – again
There were some discussions on if batching actually were going to be useful in this case or not. I have now gotten confirmed that a batched request will be considered as one (1) call. This is both for batched Creates/Updates/Deletes and Queries of multiple records (that would be very strange if it wasn’t one record, but I had to ask).
Data Export Service etc.
Data Export Service and other services that run under the system account will not count towards the API request. This is good news as this opens up for many users to be able to use this method to offload the API:s for reads.
What is the competition up to
I checked to see how SFDC are handling this and as far as I can see they have a similar setup as can be read here:
I am no expert on their licensing model, but I think it is good to know that this isn’t just a PowerPlatform thing. However, there are some distinct differences:
The API calls are not counted for normal browser/client usage. Only “real” API calls.
They have real enforcement blocking an entire instance/org if they overshoot
All API:s per user license are summed up to the org level
Microsoft Addon apps will include request
If you buy Dynamics Portals, this will include some additional licenses. The same goes for Forms Pro. Hence there should be some default API request assignment to those application users that are installed. I do wonder if it would be financially beneficial to piggyback on those application users? There is also no current method for ISV:s to bundle API-requests into their product if they install an application user upon installation.
CSP / Distributor silence
We have still heard nothing of the 10k addon SKU from any distrubutor, EA or CSP. It will be interesting to see if it will reach the entire distribution chain by October 1 when customers will start being notified that they are in violation (new customers).
In May 2019 Dynamics 365 CE/CDS enacted some new throttling mechanisms that have caused some headaches for anyone wanting to manage a lot of data in CDS (I will refer to Dynamics 365/CDS as just CDS below). There are several different throttles but the one that has cause me most trouble is the concurrency throttle. Kingswaysoft will release support for handling this in the next release and you can also request a special version from them if you ask nicely. In the meanwhile this post can give you some help on how to work as fast as possible using application user mulitplexing and a loop with a 5 min wait to make sure that the throttles are reset.
The new throttling on the main CDS API, as described here: https://docs.microsoft.com/en-us/dynamics365/customer-engagement/developer/api-limits needs to be carefully considered when doing heavy data manipulations in the CDS. One of my customers has a large system with numerous integrations of which the most data heavy are the Marketing Automation systems and the booking systems. And yes, this is Business to consumer.
With the new per GB pricing, keeping the database as small as possible has become an essential task and using the bulk delete just doesn’t work for large data loads, at the time of writing this article. I do hope that Microsoft increase the speed of it so that it does become more useful but currently its speed is somewhere around 1-2 records per second.
The bulk delete also has limitations on that it can only base it selections on a query, i.e. a FetchXML. Often this is not enough, for instance when you want to remove “All emails except those that have any connection to either a case or a contact which has a case”.
For these reasons I almost always opt for using SSIS with Kingswaysoft connectors to CDS when working with complex data management. This article will be on how to get some performance now that there is tougher throttling to take into consideration.
User multiplexing
As the throttling is measured on a “per user”, one trick is of course to use multiple users and spread the load over all these users. You can, of course use normal users, but that will cost you licenses so the smart person will of course use application users instead. If you don’t know how to create application users in Dynamics 365, check it out here: https://docs.microsoft.com/en-us/dynamics365/customer-engagement/admin/create-users-assign-online-security-roles#create-an-application-user . In the example below, I will be using four different application users, one as the source account and three as destinations. The reason for this is that it is typically easier to read several thousand rows per request, but seldom efficient to do batch creates/writes/deletes of more than 10-20.
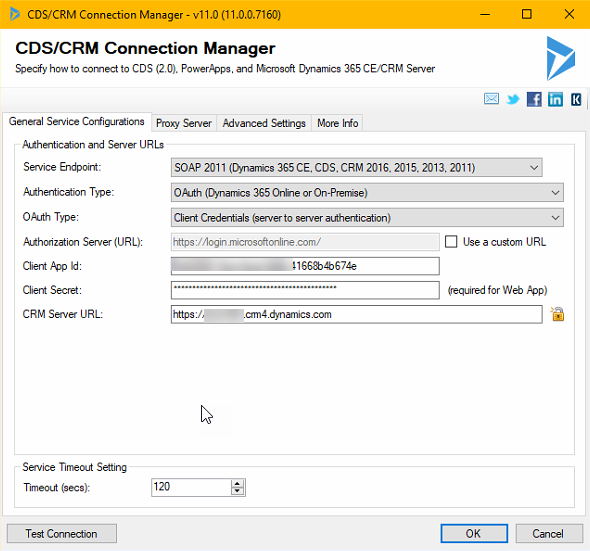
To do this with SSIS/Kingswaysoft you should start by setting up the connections. In this case, the four CDS/CRM connections and use the OAuth auth-type like below.
As you might want to have several packages in the same project and have them share the connections, it may be a good idea to use project connections. I also use an Azure SQL db for logging any errors. Previously I used to use CDS but now with the throttling, that is not such a good idea as the error itself might be throttling and hence the error can cause an error. Writing to some target that you know will not fail is hence a good idea for logging errors. When you are done with the connections, it should look something like this:
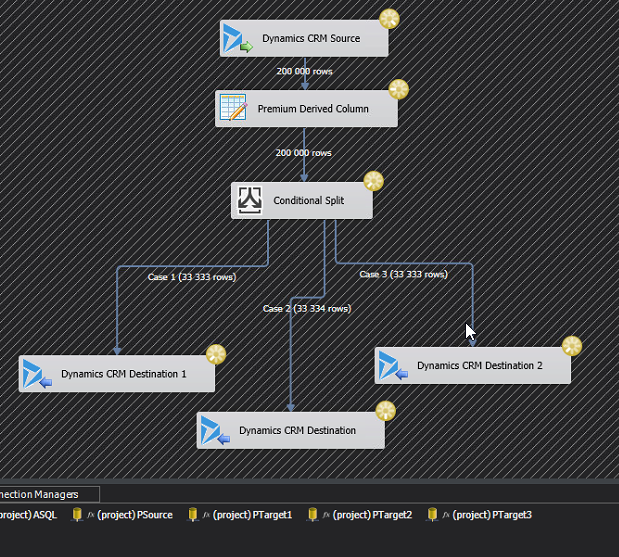
Now it is time to build the actual flow. If you’d normally have a Source and a Target, it will now look something like the image below, which I will explain.
First of all, the Premium Derived Column creates a new column which simply contains the row number. It will look something like this:
I like to use the components that are available in the Productivity pack from Kingswaysoft, and this Premium Derived Column is one of these. In this case I think it is actually equal if you use IncrementalValue() or RowIndex(). I think you can create this logic with a normal Derived Column too, it just has less features.
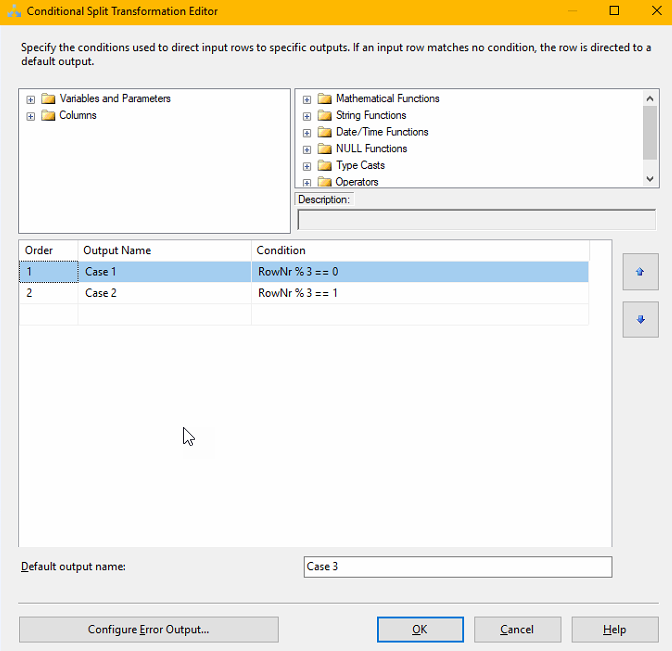
Next we need to create a Conditional split that divides the rows evenly between the three destination components. This is done using the mathematical operator modulus which is written using the “%”-sign. For those that didn’t study this in school, it simple means “the rest” in a division. For instance 5%3=2, if you divide 5 by 3 you will get 1 and a rest of 2. What we will do, is assign RowNr%3 == 0 to Case 1, RowNr%3 == 1 to Case 2 and the rest to Case 3. That should divide them evenly. It looks like this:
You then create the three destination components. I typically create one first, copy it and change it, as that is faster. Make sure that you set the Connection Manager to the three different Target Connections.
I also recommend that you fiddle a bit with the batch size and the number of threads and test out which gives the best results for you and the entity and action you are working on. There is no one answer here. I would typically start at Batch 10, Threads 16.
Tuning DataFlow property settings
If you back out to the Control Flow view and right click on the Data Flow you have created, there are some other interesting setting you can twirk.
DefaultBufferMaxRows – 10 000
DefaultBufferSize – 10 485 760 (10MB)
EngineThreads – 10
These can also be tuned to allow for the Data Flow to handle more rows, more memory and use more parallell threads which of course will make it faster (if that is the bottle neck, typically not when working with Dynamics)
What I have found is changing the maxrows to 100k, the buffer size to 100 MB and engine threads to 32 will not hurt but you can find several other blog articles specializing in SSIS that discuss this.
Crude throttle handler
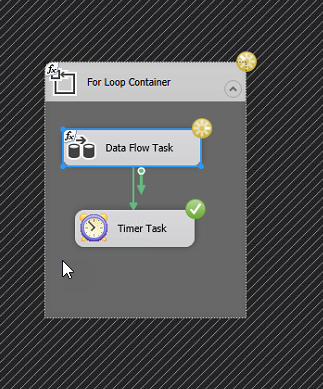
What I have noticed is that many of my Dataflows simple seem to grind to a halt after 400-600k rows read from Dynamics. Not sure if it the read or write part that is causing this but what I figured is that probably the most pragmatic way of solving this would be to create a loop that runs a data flow that is limited in the number of records, typically 400k, wait 5 minutes then iterate. Smartest version is of course to have a control variable which checks to see when when there are no more rows and then breaks the loop, simpler version is to just loop n number of times to cover the amount of data you are trying to move, ie. number of rows per iteration x number of iterations. It would look something like the picture to the left.
If you would like to refine the loop a bit to make it more automatic, create a variable of type Int, for instance RowCount, set the initial value to be 10 or something different from 0. Then set the EvalExpression to “@RowCount > 0”. After this add a RowCounter control to the Data Flow and connect this to the variable RowCount. When the Data Flow runs and returns 0 rows, it will run to the end, the EvalExpression will evaluate to “False” which will cause it to break.
Using this technique, I am able to remove several million records in just a few hours. With one of these jobs I managed to remove 20 GB of structured data in less than two days (no attachments or similar, just records). By adding more application accounts and of course both to the source and particulary to the destination side, you can increase the speeds you are getting.
I do also advise you to be on the lookout for Kingswaysofts new version which I think will come soon, and do as I, make sure to always download both the Dynamics and Productivity Pack. I have read that there are great things coming to the productivity pack!
Related to my last post, on working with the API quickly, Microsoft have now released official documentation that they will, effectivly March the 19:th start limiting the number of API-calls per instance that is allowed to stop what is called “noisy neighbour” problems.
Let’s break this down a bit, 60 000 calls per 5 minutes, translates to about 200 calls per second. If you break this, you will start getting exceptions, until the 5 minute period has ended. You are expected to back off, and essentialy handle this. That is the short version. Read the full article for more details.
Update: George Doubinski, a friend of mine and one of the brains of CRM Tip of the Day made me aware of the fact that the limit is per user. I will update the article below on what this means.
What does this mean? Is this a problem?
For most organizations, no, at least that I work with, I not even close to breaking this. If they are using some integration tools like Kingswaysoft or other tools which enable multithreaded integrations, but generally do not need that kind of data throughput then you might temporarily be shut down, but it should self heal after some time, as after each 5 minute time span, you will get another 60 000 requests. That could probably quite easily be fixed by checking the settings of the integration tool. Update: Also, if you integrate each system using a separate accont, you do not risk one system temporarily blocking many other systems from integrating to Dynamics 365. If you are using normal users, this will of course entail a certain license cost, why I generally recommend using app users for integrations, if possible. And after this, you should have one app user for each integrating system.
However, there are some organizations where I forsee issues, and these are organizations which have combinations of any of the following criteria:
Third party products which, like Marketing Automation, (ClickDimensions, FreshRelevance, SalesForce Marketing Cloud) which have not had time, or got this in their scope yet, and have large amounts of data that they integrate into Dynamics 365. Update: Especially if the user they are using to integrate, the service user, is a normal user, either used by a normal user, or shared with integrations with other systems.
Legacy Code that has been upgrade to new SDK but uses inefficient architecture – can for example have issues with using ExecuteMultiple which in the article above is described as the recommended best practice. Typically for the reason that the architecure of the code, would require major rewriting to allow for ExecuteMultiple. Update: In this case I strongly recommend looking at using a dedicated user for this specific integration, to isolate any limiations set on that user.
Organizations with multiple heavy integrations to Dynamics 365. Will be hard to control that the sum total does not exceed 60k per second, and handle back-off in a controlled way. The only reasonable way would probably be to rewrite the integrations to use a proxy or queue instead like Azure Service Bus Queues to integrate and have a single integration interface. Probably a lot easier to write in a blog article than to do in real life. Update: This was an incorrection deduction from my part, as it is not based on the sum total, but on the sum per user, this is not a risk unless many integrations use the same user for integration which I do not recommend.
Organizations with complex heavy integrations with thousands of lines of integration code that need to be redesigned, rewritten, tested and deployed before March 19:th. And there is no way to test it as there is no TAP/Beta program for this “Feature”. Update: This is still very relevant. Even such a small change as changing the integrating user for an external system should be thoroughly tested and for larger implementations that can be hard to do before March 19.
Example
I see is a typical B2C organization running Dynamics 365 with a marketing automation addon with email tracking and webtracking. They also have a very time critical integration of orders to be able to handle any incidents. Even if the order integration in itself does not reach the limits, it is not unforseeable that a mailblast, especially a good mail blast, to which many customers read the emails click the links, go their site, check their offers and start ordering, would cause a surge of traffic on the Marketing Automation integration – Dynamics 365 API. This of course depends on the settings of this, but perhaps it is critical that all events be tracked to Dynamics. With a mailblast to let’s say 1 Million recipients, quickly hitting the 60 k/5 min limit would happen. When this happens, this would also block all orders from going to Dynamics, causing an effective stop for working with any new incidents in the system. Update: This is, of course, only relevant if both systems are integrating using the same user. Don’t. However, the marketing automation system above, would hit the limit fast anyway and if the supplier of this system didn’t have time to update their product/service then it would handle this incorrectly. I recommend checking integrating systems and try to turn down the verbosity of what they are writing to Dynamics 365. Then after March 18 when we see how this falls out in detail, you can test a more verbose setting in a test environment, and then see how that falls out.
Summary
For small and medium companies with low complexity working mainly with B2B. I don’t see that much of a problem. Larger companies with complex integrations, large databases, integrations to webtracking, email tracking which often will be B2C companies which have higher levels of automation and larger databases of customers, will probably have larger problems with this and need to start think about this right now.
We need to come back to this subject post March 19, to see how this will really work. But I think the real problem will be for the larger orgs with many and heavy integrations.
I would be really glad to hear your views on this like I got Georges’.
Gustaf Westerlund MVP, Founder and Principal Consultant at CRM-konsulterna AB www.crmkonsulterna.se











Recent Comments