
Entitlements are not throttling
Should a five user organization be entitled to the same amount of compute as a 5 000 user organization?
Entitlements are the limitations that Microsoft have set on the platform that are based on which type of license each user has. This is not the same as the API Service limits which are much more liberal. The entitlements have not yet been fully enforced as the reporting capabilities of the platform have not been rolled out fully yet. But they will. With this blog post I attempt to give my perspective on entitlements on the Power Platform and Dynamics 365 (CRM part).
My previous post was about API Service limits which are commonly referred to as the throttling limits of the platform. The entitlements limits (and here) have another part in the Microsoft docs that go into these a bit deeper. I’d first like to go into why there are two different “protections” or limitations.
The API Service limits are there to protect the platform from noisy neighbours. Some of us, that have been around since the earlier days of Dynamics 365/CRM online remember that the performance used to be rather shaky. This could often be due to the fact that some other instance on the same hardware your instance was hosted on, was being slammed with massive amounts of requests, like during a migration. To make sure that this “noisy neighbour” problem doesn’t occur, the API-limits have been put in place and since they have, things have been a lot better so they do seem to work.
The Entitlements are there for another reason. Let’s say you buy two (2) Dynamics 365 Sales users and then use integrations with a custom built front end for B2C purposes with one of those users (or an app user), and, still within the limits of the API Service limits, hammer the API:s from day to night with an amazing amount of requests. The B2C aspect would be covered from a licensing perspective in what was previously called “external connector” license and is nowdays included in the normal license. However, the amount of compute that the instance is utilizing is way above what you are paying for. This is the reason why Microsoft have created the entitlements, as far as I know anyway. And I think it only makes sense that there is some kind of reasonable proportionality to that.
To quote the Microsoft docs page: “These limits represent the number of requests users are entitled to make each day. The allocated limit depends on the type of license assigned to each user.“
What is a request?
The first question is then, what is a request? Previously we were told, that a batch request (ExecuteMultiple) was one (1) request but that has since changed and is now considered to all the subparts. I would even think that a batch request has the extra overhead of the batch itself. Hence, a batch request with 10 creates, will actually be counted as 11 requests; 1 for the batch, and 10 for the creates. The exact definitions are not disclosed but we get a rather good description from the docs with this paragraph, where I have highlighted some interesting parts:
“For Dataverse, API requests include all data operations that interact with table rows where rows are created, retrieved, updated, or deleted (CRUD). Special operations such as share and assign are included because they are considered updates. These requests can be from any client or application and using any endpoint. These include, but are not limited to, operations performed by plug-ins, async workflows, custom controls, and $batch (ExecuteMultiple) operations. There are a small set of system internal operations that are excluded, like login, sign out, and system metadata operations.”
The important takeaway here is hence that you cannot create a workaround by using a plugin and using the internal context pseudo-api to do the calls, as these are counted as well. Difference might be that they are done in the context of a specific user and that user has a rather large entitlement, which might hence “flatten the curve” so to speak. An interesting aspect, though is the exception to this rule:
“Power Platform API request allocations include use of Power Automate, AI Builder, and Connector APIs. All requests through a connector that result in a Dataverse request will represent 1 Power Platform request.”
This strongly indicates that Microsoft wants us to use the Power Platform tools and that these should not at least have additional costs. There are, however, still some inconsistencies in this area that I really hope that they fix, such as:
- Microsoft supplied integrations in ADF
- Integrations to Dynamics 365 Finance & Operations
- Dynamics 365 Business Central
- Exports to ADLS
- Data Export Service
The latter two can be really heavy on the API:s if you have an enterprise system or a B2C system. I work with a customer which currently have a database of >400 GB which uses Data Export service and the amount of notifications on the Data Export Service just for Contacts for a year often exceed the hundreds of millions.
Other areas which are not mentioned but which I think are included are addon first-party apps like Customer Insight (Sales Insights) which actually uses a ADLS in the background (not that you can actually access it). I have heard stories of support tickets where Microsoft support have blamed the API Service protection for hitting the ceiling when it was Sales Insight that caused it, which would indicate that these are actually counted. I think the intention is to include all of these so that the license for these cover the API entitlements. I just wish they would fix the gaps as customers are being affected.
Entitlement telemetry might not be the same as API Service protection telemetry
That actually brings up another interesting aspect. The measurements that are used for the API Service protections are probably NOT the same as the measurements that are used for entitlements, but this is based on my personal hunch, and not any kind of facts. Mainly based on the assumption that I think that the areas that are excluded from entitlement measures above, probably are not excluded from the API Service protection.
Another definition of request!?
On this page there is another definition of what a request is that is different from the one above. I believe this is older than the one mentioned above, as it uses the term “CDS” which has been replaced by dataverse now. I am not sure though as this page last change is dated on the second of feb 2021 while the other the 5:th of March 2020. The main difference is that this does not make the exception mentioned in the article above, hence every call through a connector, every successful or failed call in Power Automate will be counted as one request. Hopefully Microsoft will clear this up soon.
Entitlements per user
At this link you can find the specific entitlements per license. They are all measured on a 24 h period and range from 20 000 for the full enterprise versions of Dynamics 365 to Power Apps per app plan which get 1000 requests.
Entitlements for non-licensed users, which mainly will be application registrations/application users are fixed per tennant based on the highest licensed purchased on the tennant. This means the following pooled included non-licensed entitlements.
- 1 Sales Enterprise -> 100 000
- 1 Sales Professional -> 50 000
- 1 Power Apps license -> 25 000
- 1 Sales Enterprise, 1000 Power Apps -> 100 000
- 10 000 Sales Enterprise, 10 000 Power Apps -> 100 000
The important note here is that this does not scale at all, but is fixed. And if you plan to do some integrations with a Power Apps only tennant, you’d be wise to buy at least one Dynamics 365 Enterprise, just to get the non-licensed user entitlements, as the Sales Enterprise is around $95 and each additional 10 000 is $50, which means that the saving to get to a 100 000 calls / 24h is:
50*(100 000 – 20 000)/10 000-95= 400 – 95 = $305/month
Buying extra capacity
It is also possible to buy extra API capacity. You can read more about this in the Licensing Guide for the Power Platform. I am not able to find a current price for this at this time, but the list price was previously set at $50 (per 10 000 for 24h). These are then to be allocated to the users as you wish.
Overshooting
“Users will not be blocked from using apps for occasional and reasonable overages at this point of time.“
What will happen when or if you overshoot? A very important question. Most organizations will at some time do this, most probably during migration of data from the old systems. The statement from Microsoft above, especially the highlighted “at this point of time.” is rather omnious. It does indicate that at some time the hammer will come down. But at this time it won’t, admins will be harassed with emails about overshooting and just as with overshooting data capacity, they might start with blocking some features when you are overshooting. It is mentioned in one of the articles in the FAQ that after the transition period they will start blocking. So that will be a real fact unless they change their mind on that.
My very strong advice, is hence that all organizations that are not compliant need to start looking at this as soon as possible. I have some tips on what you can do further down in this article. Please refer to these and feel free to leave a comment if you have questions on the subject not answered here.
ISV Bundling
There are many ISV:s which export rather large amounts of data. The first ones that come to mind are the Marketing Automation products like Adobe Marketing, Click Dimensions, Dot Digital and more. These all synchronize contacts, marketinglists and marketinglistmembers, at least, which for larger installations can be quite large datasets. I do think it would be advantageous if these ISV:s could include the API Entitlements that are required, or if they are billed by Microsoft to the ISV which in turn bills the customer with a surcharge. At the very least Microsoft have to take ISV:s into the equation here as they are an essential part of the ecosystem, especially from the customer perspective.
Tips on how to handle future entitlement enforcement
- Start by using the PPAC to get an overview of how your situation looks even though you might not get an exact picture.
- Consider the overhead of batching. There can be performance advantages to batching as mentioned in my previous article. But there needs to be
- Consider “outsourcing large datasets” to ADLS – although the ADLS export also uses API-calls.
- Maybe not a problem if short term – for now
- Consider using official connectors or Power Automate instead (although that might cause costs in itself)
- If building Power App licens based solutions and you have heavy integrations, buy one Dynamics 365 Enterprise license.
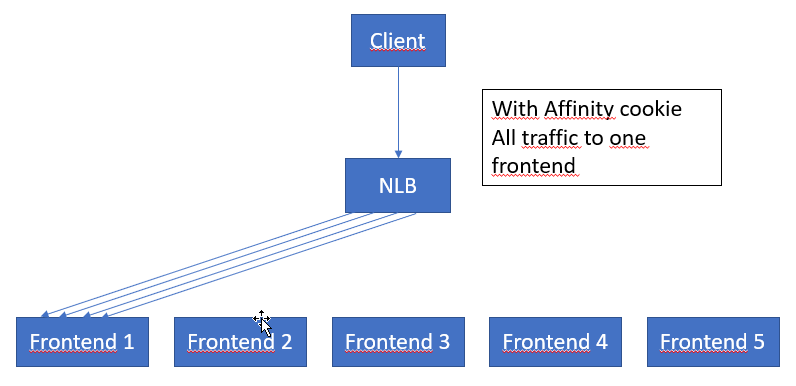
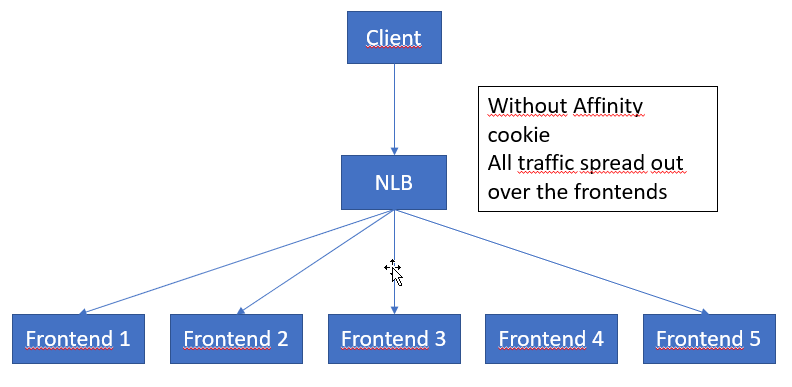
- If possible impersonate the data load over all the users. This can be done with plugins and synchronous workflows for instance. Patterns that can be used in this case can be staging tables in dataverse where the owner is set and then a plugin is triggered that slices the row into many pieces as the owner of the import record. I am not sure if impersonation using the API will have any effect on this. That needs to be investigated. If it can be used to spread the load, that would be a good pattern to use.
- Refactor inefficient code. Depending on implementation maybe increase use of caching or other techniques to reduce the amount of requests. Make sure you have skilled Power Platform/Dynamics 365 developers working with development as knowing how to do this very particular to this platform.
Microsoft representatives, locally in Sweden anyway, are saying to our customers and potential customers that they need not worry about this. I find that message a bit mixed with what I read here. On the other hand I think this will be a very rough change for many organizations. If your organization will be very negativly affected by this and you feel that you are still paying “fairly” for your part, then I suggest you contact Microsoft and describe your business scenario in detail. If you need help with who to contact you can always start with the people who have written the articles who you can ask to forward the articles to the right people, use your local user group or ask some local MVP for help as they often have contacts directly with the product group (and many other experts do too).
Good luck and do leave a comment or share this if you like it!


Recent Comments