When measures are created in CI-D to be used in CI-J there are dependencies created which will stop you from removing the measure. CI-D is not very helpful in telling you how to remove it. I will try to be a bit more helpful.
When trying to remove the Measure this is the error I got:
Error: Detected DataVerse dependencies in Measure: ListMemberships. Please delete these dependencies and merge again.
Request ID: 14056846-b9c1-4ec8-98c2-88778e518b88
Time: 2024-12-05, 11:12:10
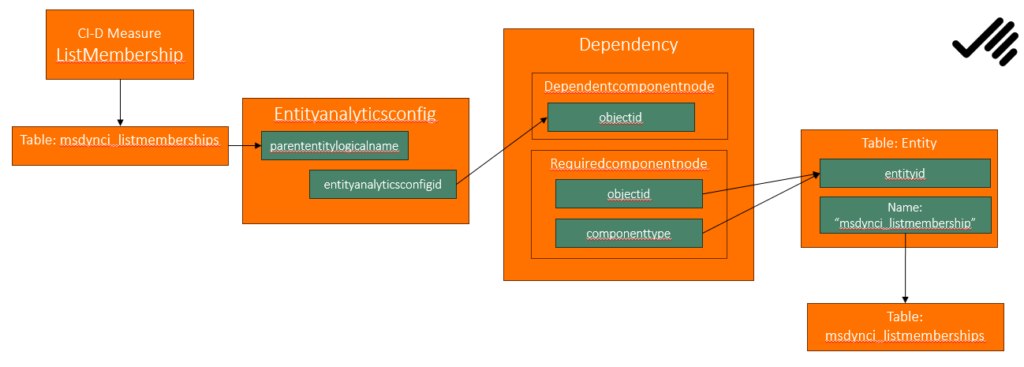
My investigation below with the help of Microsoft Support lead me to the understanding according to the image above. As you can see dependency is actually sort of circular, or at least one part of the dependency (dependent component) is at the entityanalytics on the record which points to msdynci_listmemberships, on the other hand (required component) on the table msdynci_listmemberships.
The fix, is to remove the record in entityanalytics. Easiest way in this case, is to just use a browser console where you are logged into the right Dynamics.
To remove the entityanalytics record that is blocking this:
After this I was able to remove the measure in CI-D.
Below I will detail the steps I did to understand this.
The first step is to look in the table “entityanalyticsconfig” searching for the name of the Measure. Its name is “msdynci_” + name of the measure. Check out the metadata if you are unsure.
Hence, from this I generated the image above. Since it is something of a circular reference, Microsoft Support suggested that I remove the entity analytics record with id: e46e52db-46a7-4585-8a6a-6ba888a5bd1f. However, not entirely sure what this is and hence I tried the one I had gotten in the first steps above, and that worked.
Generally I think it is a good idea to investigate what the dependencies point to, before removing something. In this case the dependency record in itself wasn’t removed, only the dependent part.
Thanks to Microsoft support for helping out with this and I hope it might shed some insights if you are having similar issues. I also think breaking down the dependency table in a tool in for instance XrmToolBox would be a great idea. I have a bit of a bad conscience for BulkDeleteManager that I own and I am not giving enough love, so feel free to build it based on this and I guess some more stuff. I will be happy to help out the the investigations if you are willing to build it.
When you create an instance in dataverse you get to choose which region it is located in. However, you do not get to choose which exact datacenter you get. How is this important? Well, if you want to mirror data using Azure Synapse Link or Microsoft Fabric, then these resources have to be in the exact same datacenter to work. If you have several instances, there is a risk that some are in one of the datacenters in the region and some in the other. For instance, in the region Europe, there are two datacenters, North Europe (Dublin) and West Europe (Amsterdam). So, it might very well be that some instances are in Dublin and some in Amsterdam.
Currently there is only one way to move an instance, and that is to create a ticket and ask Microsoft Support to do it for you. But you first need to know where it is.
The easiest way to find where you instance is located, is actually to start the wizard for synchronizing data to a datalake using Azure Synapse Link from the Maker-portal. It should look something like this:
However, if you have many instances, you might want to have a script that outputs this. Well, I did anyway, so I was looking into how to do this using Powershell.
Hence I dug into some of the PowerShell libraries for Power Platform and created this PowerShell script:
# Get all environments
$environments = Get-AdminPowerAppEnvironment
# Loop through each environment and output DisplayName and azureRegionHint to a file
$environments | ForEach-Object {
# Create a custom object with the properties you want
[PSCustomObject]@{
DisplayName = $_.DisplayName
Type = $_.EnvironmentType
azureRegionHint = $_.Internal.properties.azureRegionHint
}
} | Export-Csv -Path "C:\temp\output.csv" -NoTypeInformation
In this case the “azureRegionHint” was supposed to show the right datacenter. But that turned out to be a half-truth as many of the instances were correct but not all. I suspect it might be stored list and not the actual list, as at least one of the ones that were incorrect has been moved.
I reported this to Microsoft support, as my view is that the azureRegionHint should display the correct datacenter, and hence what I experienced is a bug. But I never got this acknowledged by support who instead recommended that I use “ping” to figure out the region;
C:\Users\GustafWesterlund>ping xxx.crm4.dynamics.com
Pinging db3--eurcrmlivesg000.crm4.dynamics.com [52.155.235.153] with 32 bytes of data:
Reply from 52.155.235.153: bytes=32 time=56ms TTL=107
Reply from 52.155.235.153: bytes=32 time=55ms TTL=107
Reply from 52.155.235.153: bytes=32 time=69ms TTL=107
Reply from 52.155.235.153: bytes=32 time=75ms TTL=107
Ping statistics for 52.155.235.153:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 55ms, Maximum = 75ms, Average = 63ms
In the response above, db is “Dublin” and my guess is that the “3” means datacenter 3 or something like that.
However, using ping to do what in essence is a nslookup didn’t seem very useful and I also wanted to be able to use PowerShell, so I looked up the command:
Resolve-DnsName -Name $url
This is in essence nslookup, which, if you are not very versed in this, will give you the IP address and official name of a specific alias (cname). As the following example shows:
PS C:\WINDOWS\system32> Resolve-DnsName -Name xxx.crm4.dynamics.com
Name Type TTL Section NameHost
---- ---- --- ------- --------
xxx.crm4.dynamics.com CNAME 300 Answer db3--eurcrmlivesg000.crm4.dynamics.com
Name : db3--eurcrmlivesg000.crm4.dynamics.com
QueryType : AAAA
TTL : 300
Section : Answer
IP6Address : 2603:1061:2002:968::36
Name : db3--eurcrmlivesg000.crm4.dynamics.com
QueryType : A
TTL : 300
Section : Answer
IP4Address : 52.155.235.153
The first part is the information that the DNS entry is a cname/alias to the aname which starts with db3. The following two blocks are the IPs in IP v6 and IP v4 of this name. Using this I adapted my script and added a manual switch which shows the datacenter which starts with “ams” as West Europe and “db3” as North Europe. Don’t know if this information is available anywhere so that I can look it up instead as that would be a lot more dynamic. But at least I can loop through all instances and get the azure datacenter for each of the instances. Here is the script:
I hope and guess there are easier ways to solve this. If you have any ideas, please let me know in the comments or if you have any other method to solve this for a lot of instances where using the UI would be a bit too much of a hassle.
In a previous post I blogged about how to break down the Form script that was exported from CI-J (Real Time). As some customers asked me about making this into a script that was the same and was dynamic based on query string parameters (parameters in the URL), I worked a bit on that and thought I’d share it here;
A few things that can be mentioned. This script expects that there will be two query string parameters: id – the id of the form. Click on the form and copy it from the URL after the “id=” orgid = the orgid which you can find in the PPAC or in the export of the script as I described in the previous article. If it is placed on the url: https://contoso.com/form.html then an example of the url would be:
Finally some organizations also have problems with loading a script from external sources. I will look at that too. Mainly there are two option. Copy-paste the entire script inline into this script or copy the script file to an “internal” or recognized store with a public URL and change the src-attribute. If you move this away from referencing Microsoft, I would recommend checking their website on a regular basis to make sure it hasn’t changed.
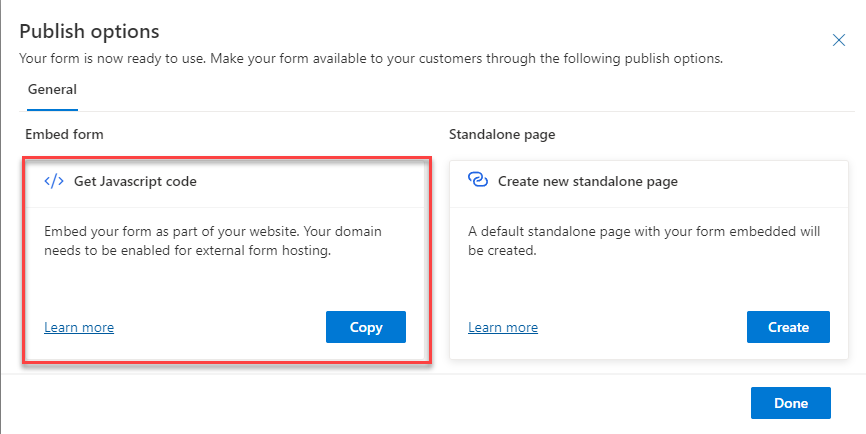
When creating a form in Customer Insight Journeys (real time) one option is to embedd it in an existing page. A customer asked me if it was possible to get this script from the API some how. Turns out that you don’t have to. It has a logical build-up and you can generate it yourself with a script.
First of all, let’s have a look at the generated script;
I have highlighted two different guids (I have changed them so they are not the actual guids).
The first one; 2e2b50a9-0000-0000-9079-0022489ca998 this is the Form id. It is the exact Id of the form that you have created. Easy to confirm by checking the id-parameter in the querystring for the form. This can easily be queried from the WebAPI from the table msdynmkt_marketingform.
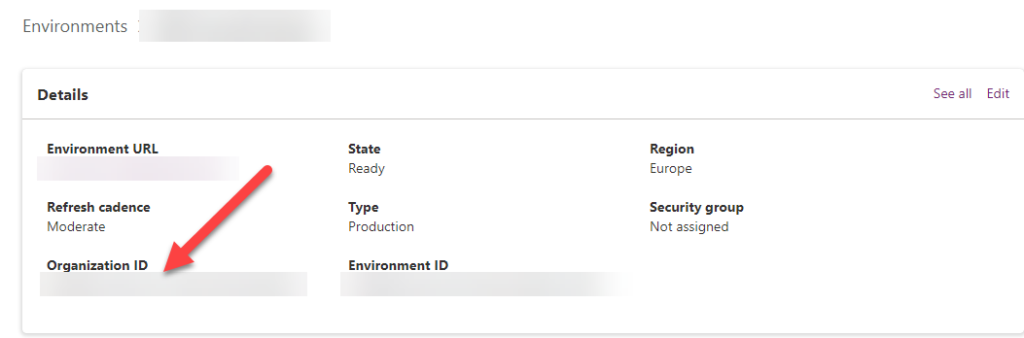
Second guid; 4e5c8ea2-0000-0000-ac66-a30471bdf4fa is the instance id of the dataverse instance. This can be found in the Power Platform Admin Center under “Organization Id”. This is hence the same for all forms that are from the same instance.
The rest of the script is the same. Hence you can generate this quite simply with a script if you have these two values. I don’t know if the library referenced might risk being changed during updates or similar. Hence I would recommend using it with the same reference as seen above, but it might also be possible to download it and host it yourself. This is not something I have tried.
A colleague of mine, Thomas Passad, also mentioned that some CMS:s, like Optimizly, cannot handle the script being reference directly and that it had to be placed in some general footer or similar.
With this knowledge I think it is possible for you to handle this script in a more dynamic fashion but make sure to check that it hasn’t changed every month or so, as it might cause issues if there is a change and you havn’t taken that into consideration.
Working on a new environment recently I had to remove a few tables. However, after removing all normal dependencies, it complained finally about a dependency to the table: entityanalyticsconfig. Never heard about it. After some googling on Microsoft Learn I found that it is about the sync to datalake, which was funny as we hadn’t set up any sync. I think it might be the new Microsoft Fabric sync from Dataverse that might be causing this. It might be switched on by default in the case that you have change tracking switched on.
Also I couldn’t find it in advanced find (the old or new one) but with https://fetchxmlbuilder.com/ in XrmToolBox I was able to find it and also the rows that were associated with it. So, I created FetchXml for these specific rows, used the tool Bulk Delete Tool (no not Bulk Delete Manager, which I made) by Andy Popkin and simply ran the delete for these specific rows. This allowed me to remove the dependency and then remove the tables.
I have recently been working with a customer with a large (500+ GB dataverse db) production instance and we are attempting to cut this down quite a lot. The natural way of doing this is bulk delete but it seems that if the underlying SQL isn’t up to speed, your jobs might end without actually being done.
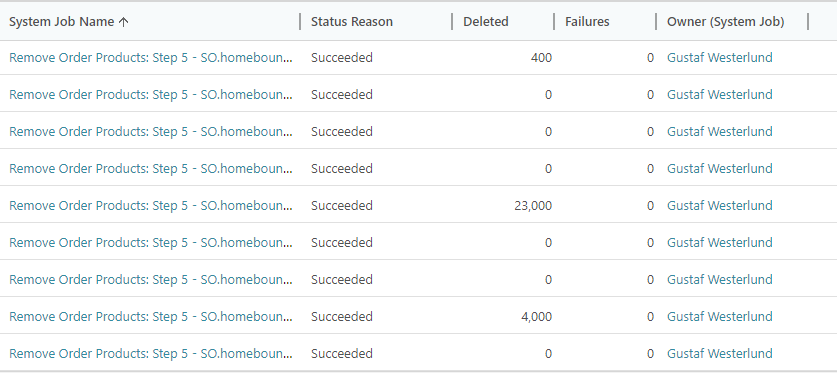
My customer has a production instance of over 500GB which is costing them some substantial money and hence we started looking at removing some of the less necessary data. In this case it was the order products (salesorderdetail) which we have perceived that we do not need more than one year after delivery. Hence we set up an advanced find, agreed on the exact filters, saved the view and then tried to remove the records (well over 5M) using bulk delete. I restarted it several times. You can see the chronological results in the screenshot below:
As you can see, sometimes it actually deleted a few records, but most times, it didn’t. My professional analysis of this (=guess) is that this is caused by bulk delete not handling exceptions like SQL Timeout properly or that it has a limit on the number of times it will retry.
I also, in parallell tried to remove the same records with the same FetchXML using SSIS/Kingswaysoft and here I have several times gotten this error. I have had to turn down the knobs to a very low setting to get it to work, but the error message I did get was:
(Status Reason: ServiceUnavailable): The remote server returned an error: (503) Server Unavailable.”.
As you can see, there is a lot of noise but it clearly, in the highlighted part, say that there is a SQL Timeout.
Hence my takeaway from this is that you need to be a bit wary of bulk delete in large instances or in general as it might indicate that it has completed successfully but in fact it stopped due to SQL Timeout (or some other platform related issue).
On a personal note, I really hope the bulk delete functionality gets a modernized revamp soon. It is really old and is becoming more and more relevant.






Recent Comments