“Do you really need to delete records like a Ferrari?” – that question was posed to me when I, a few years ago complained about the bad performance of the Bulk Deletion functionality in Power Platform (at that time Dynamics 365 Online) to a friend at Microsoft who I will not name. And my simple answer is yes, we do need to delete records like a Ferrari, for many reasons. I will discuss why in this article and I have for that reason also created an Idea on the Power Apps Community site on this subject and I hope that you agree with me and vote for it! You will find it on the link below.
So, why is a fast bulk deletion important. I would say there are several reasons and I will walk through the ones that I have thought of, if you have any other, please drop a comment.
Keep your data in check – remove unnecessary data
GDPR and other compliancy and legal issue
Power Platform growing into Citizen developer platform
Entitlements effectivly blocks using external tools
Keeping data in check
For larger organizations, especially with many integrated modules and systems, many running Flows, workflows, Customer Voice surveys etc. the system will generate a lot of data, especially if it is a B2C scenario. A few of these have built in features that automatically remove old logs etc but most don’t and we as admins and system caretakers (isn’t it a fancy title!) need to tend to this, typically by setting up jobs that clean old data. I would recommend looking at the PPAC statistics of which tables are the largest and having a practice of doing so at regular intervals and downloading it. That way you can see the trends over time. A suggestion for an addon to the CoE Starter kit would be a trend analysis of all tables with growth numbers per week for each tables with warnings for quickly growing tables and prognosis.
However, as instances start growing over 50-100 GB in size (of structured data) it soon becomes too large to handle the data with bulk deletion. Some tables might still be managable this way, but in general the performance is has is, when I have tried to measure it (albeit a few years ago) was around 1-3 records per second. A customer I have, working with B2C for whom I wanted to remove their Voice of the Customer, which had been used a lot, had over 50 Million Survey Invites. It is not possible to remove the solution without first removing the data, and if we were to use Bulk Delete and put it on crack and it got to 10 records per second, it would still take around 2 months. I now did it with SSIS/Kingswaysoft and it took a few days. If Bulk Delete could reach around 200 records/second, it would take a little less than 3 days.
I have also noted that when trying to Bulk Delete very large datasets, Bulk Delete simply fails, as I think the FetchXML query might do a SQL Timeout or something like that. Not exactly sure what happens. As it works with Kingswaysoft I don’t know what might be the difference.
GDPR and other compliancy and legal issues
As GDPR and other similar compliancy regulations have come into play in many countries around the world, it has become ever more important to stricly follow these detailed instructions. These might be simple when you look at them on a Power Point C-level perspective but when you dig down on the detailed level, where they actually need to be implemented, things seldom are as simple as in a Power Point.
Power Platform growing into Citizen developer platform
As the Power Platform grows from being just a platform on which Dynamics 365 is delivered to being a huge platform for digitalization entire organizations with almost 100% user saturation will be coming starting to use Dataverse. The amount of data being stored in dataverse will hence grow to massive amounts and hence an effective tool to manage this data is most important. It is probably even important to such a level that Bulk Delete cannot even scratch the top of the iceberg of what we need to be able to do on a data management perspective as data will be growing and expanding in heaps and bounds and admins will not only need to manage Flows and Apps but also data in size and content.
Entitlements effectivly blocks using external tools
The soon to enacted entitlements, as mentioned in my previous post, Entitlements are not throttling | Powerplatform.se, also effectivly stop the use of external tools like SSIS/Kingswaysoft for deleting unwanted data. One of the customers I am working with generate between 10-20 M API requests PER DAY, and the bulk of these are from deletion jobs or other maintainance jobs trying to keep track of the instances. With the new entitlements charge, there is no way this can be continued, but the customer is cought between a rock and a hard place as either the data grows by leaps and bounds or the API calls becomes a huge cost and there is no easy way to handle it. What advise am I to give the customer? I would think that the most reasonable thing would be if the platform made the tools available to maintain the data to avoid the costs. If this is using bulk delete or some other more elaborate feature, that is up to the product team but I do think they should hold off on activating the entitlements until there is a good alternative for managing an instance data within the platform before this (not generating API requests).
What else is missing?
Bulk deletion is not only not being performant enough, it also lacks the effective filtering logic that is required for more complex queries. For some customers a I have had to construct rather elaborate SSIS scripts which start with a complex FetchXML and the filter the data through several Cache Transforms, for instance with GDPR consents and similar to be able to get the final list. I must admit that I havn’t tried using the new T-SQL connector for this, that it could handle the full T-SQL complexity and that it is implemented in Buld Delete or Kingswaysoft as a means to make querying more powerful.
Microsoft recently (in February) published some updates to their documentation regarding Service protection API limits or as they are sometimes referred to, throttling. Some of these, like the new recommendations on how to handle batching are rather interesting and I thought I’d give my 2 cents about this. They are also eluding a bit regarding how the network infrastructure is set up for the deployment and how to optimize when handling larger workloads using the affinity cookie setting. I did find this rather interesting too.
In short, within a 5 minute sliding window, you cannot exceed the following for one specific user.
Not more than 6 000 requests.
Not more than 1 200 (20 minutes) execution time – equal to 4 parallell processes if running at full capacity
Not more than 52 request at the same time (concurrently).
Generally, if you do not use batching, you would typically run into the first (1) or the third if running unlimited threading. If using a connection pooling with 52 connections, then you probably run into the 1:st, and if you use complex request that cause cascading behaviours or batching, then you typically run into the second (2). There are exceptions that match these. Do refer to the official docs above for details about that.
Now to the interesting part. There is a new section that is attempting to tells us how to maximize throughput. First of all, I think this is great. We really need this and we need Microsoft to tell us how to not only use the platform, but how to efficiently use their platform.
“Let the server tell you how much it can handle” This section is interesting as it recommends a rather complex approach to how to work with performance. As they further down recommend using threading, they essentially recommend building logic that dynamically increases and decreases the number of threads as the platform informs you that it has capacity. This brings me back to university math, and trying to figure out the derivative of an unknown function by sampling and finding the local max. I do however, think this is a rather tall order to recommend to your average developer. But it would be a great community tool, so feel free to build it. Consider the challenge set. Best would be if Microsoft included this in the SDK of course.
“Use multiple threads“ In this part they recommend using multiple threads. This is also my experience that this is a good idea as the processing time and latency per package causes certain delay on a per-message basis. By utilizing multi-threading with multiple connections, this overhead can be reduced. As there is a limit of 52 concurrent connections, I would recommend using a maximum of that amount of connections/threads per user.
Avoid batching Now this is really interesting. The previous recommendation was to use batching to be “nicer” to the API and get increased performance. The recommendation now is the direct opposite. This is based on the fact that the overhead in a WebAPI JSON-message is significantly smaller than that in a SOAP message and that this will reduce the difference between using batching and non-batching. They do, however, recommend using smaller batch sizes still. This is also my experience when working with Kingswaysoft. I typically (it depends on the instance and which table I am using) start with 16 threads with batches of 10 or 20. This has typically given me the best performance, with performance of +300 records/s.
There is also a comment about the fact that the using batching does not bypass the entitlement limits, ie. 20 000 API calls/24 hours for an enterprise user/100 000 API calls for all non-licensed users and so on. See more on the Entitlement limits based on which license you have here. Hence this calculation is done by after exploding the batch on the servers. This is also news to me as I previously was told that batching was exactly the way to go to limit the amount of calls.
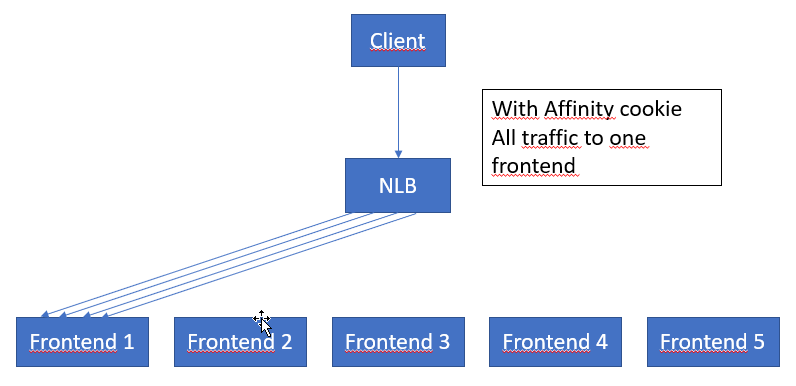
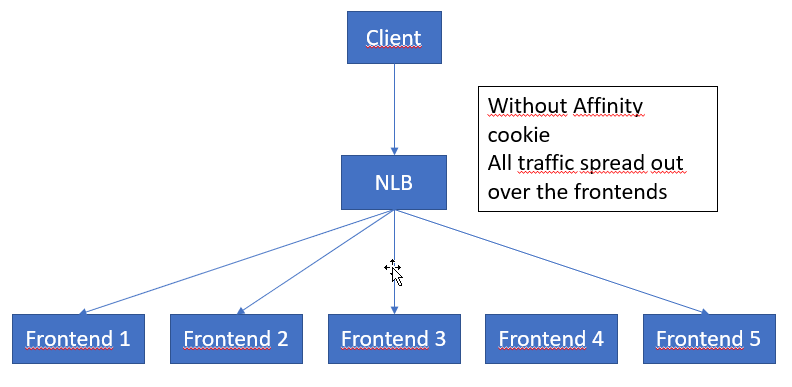
Removing the affinity cookie – server multiplexing The details being eluded to in this section are very interesting. If I understand it correctly, the logic is as follows:
The point being that, shutting off the affinity cookie int the HttpClient will allow for more wider use of all the servers in the node (the entire setup of all the Frontends, backends, NLB etc.)
What I do wonder, is if it would be possible to store the Affinity Cookie, and hence pool it on the client side. As each time you need to hit a new front end you will loose some time while it warms up your instance, and it would hence be advantageous to be able to more tightly control this. Maybe even this could be another community tool for someone interested? I also think, I havn’t tested this, that you will get better results when working with removed affinity cookie if you do use batching, at least until all the frontends have been warmed up to your instance.
Do also note a very important sentence; “This increases throughput because limits are applied per server“. We do not know how many servers are used in a node frontend, but probably more than 10. Removing the affinity cookie could hence increase performance by at least one order of magnitute.
User multiplexing As all API limits are calculated on a per-user basis, another way to increase performance is to use what I like to call user multiplexing. This means that operations are done using several different application users at the same time. There is of course some admin work that needs to be done to set these up, and there is no OOB way of doing this but with SSIS and Kingswaysoft it is rather straight forward; just create several connections, one per user, configure them per user and then use the “Balanced Data Distributor” which can be found in the productivity pack to spread the data to different destinations that are using the different connections.
My tips My tips for getting good performance, for large scale datasets, are hence the following based on these new facts:
Continue to use batching, but don’t use huge batches. Probably around 5-20 will be ok.
Use multithreading. I typically use around 16, but that was before I knew about the removal of the affinity cookie. Hence I would recommend 16 per server. But I cannot tell you how many servers there are.
Use the remove affinity cookie setting, and if possible, figure out some way of pooling the affinity cookies instead.
Make sure your application can handle the exceptions regarding the API-limit and have some reasonable strategy for working with them. I have found that blasting the API for 5 minutes at max speed, then backing off for 5 minutes, then going full throttle again for 5 minutes, has given me better throughput overall than “being nice” and just finding the “right” speed to use to not be throttled. Not sure this strategy will work in the long run though.
Use application user multiplexing.
Suggestions to ETL vendors and others My suggestions to ETL vendors and others who build connections to Dataverse that require high performance are:
Start by visualizing the affinity cookie setting so that it is possible to set this as wanted.
Include multithreading, batching and application user multiplexing into the standard dataverse connections.
Figure out if there are an points to pooling the affinity cookies, and if so, include this into the connection.
Make the connection auto-optimize with the data it is currently sending. Ie. how many threads, size of batches, size of affinity cookie pool and number of application users to utilize.
Have different strategies for utilizing application users instead of just spreading the data evenly, it could be that one is used until it receives an exception an then it is put on hold for 5 minutes and then another is being used. Or a combination of these two if there are five application users, 3 might be used for data transfer, and two on hold in case one gets an exception and needs to be put on hold.
I hope this has given you some insights and that my 2 cents got you this far. Feel free to leave a comment if you have an questions!
Some people might have heard about an industry best practice that you should never have custom columns (fields) on the systemuser table (entity) in dataverse. Is this true and why so? This article is based on my understanding of how the inner workings of dataverse works and hence what you need to think about when designing your application to not unintentionally create an application that destroys your environments performance. In short, be careful about adding custom columns to the systemuser and if you do, only add fields that have static data, ie data that doesn’t often change. Let me describe this in more detail.
First of all, I would like to give credit to a lot of this to my friend and former Business Application MVP Adam Vero, who described this in detail for me, I have also discussed this with other people and since had it confirmed but not actually seen it documented as such, why it might not be fully official. I do, however, not see any problems with people understanding this, rather the opposite.
Dataverse is an application platform that has security built into it as an integral part, there are security roles, system users, teams and business units that form the core pieces of the security in the system. As the system will often need to query data from these four tables, it has a built in “caching” functionality that per-environment loads these four tables and precalculates them into an in-memory table for easy and fast access. This is then then stored in-memory for as long as the data in these four tables is kept static, in other words, nothing is changed, no updates, no creates, no deletes.
What could then happen if you add a column to the systemuser table? Well, that depends. If this column is a column that you set when the user is created and then never change that, that isn’t a problem, as this wouldn’t affect the precalculated in-memory table. However, if the data of these columns are constantly being changed, like for instance, if you add a column called “activities last 24h” and then create a Flow which every time an email, appointment etc. is created it will increment this by one per day and reset it every night for every user. Then every time, this writes to any user, the precalculated in-memory table will be flushed and recalculated before it can be used again causing a severe performance hit that can be very hard to troubleshoot.
How would you create a solution for a the “activities last 24h”, as described above then? Well, I would probably create a related entity called userstatistics with a relationship to systemuser. In this case it could even be smarter to have a 1:N relationship to this other entity as you could then have many userstatistics per user and measure differences in activities day by day.
But wouldn’t the NLB:s (Network Load Balancer) make this irrelevant as each environment is hosted together with many others? Well, I cannot, due to NDA talk about the details of how the NLBs actually work for the online environements, but I can say this, no, it is still relevant. The NLB will make it so for performance reasons.
As for teams, it is only the owner teams that count in this equation, the access teams are only being used for sharing or other types of grouping and hence never part of this pre-calculation.
And the savvy person would then of course realize that the multiplied size of:
systemusers x owner teams x business units x security roles
Does make up the size of this pre calculated table and for large implemenations, this can give indications of where performance can start to make a difference as every time a user does not have organizational level privilige, the system has to go through the entire table to check what is right. And then of course the POA. But that table is story for another day and another article.
Just final word. The platform is constantly shifting and even though this was true and probably still is true, there might be changes going on or that have happened that I am unaware of, that have changed how this works. If I hear of this, I will let you know.



Recent Comments