Storing data in dataverse is very expensive. Especially the data that is stored in the actual database (db data). Hence, for many customer with larger datasets, typically with some B2C type of business, it is a good practice to overviewing the data you have in the system and figure out different ways of keeping it from costing too much money.
Below are 10 tips you should consider to keep the data in check.
Make a deletion list – and set up deletion jobs
Flatten verbose fields
Use virtual tables
Use datalake with analytics
Use datalake for archiving
Compress complex structures
Clean up non-production environments
Revise datamodel
Revise integrations
Set lifecycle for instances
1 – Make a deletion list and set up deletion jobs
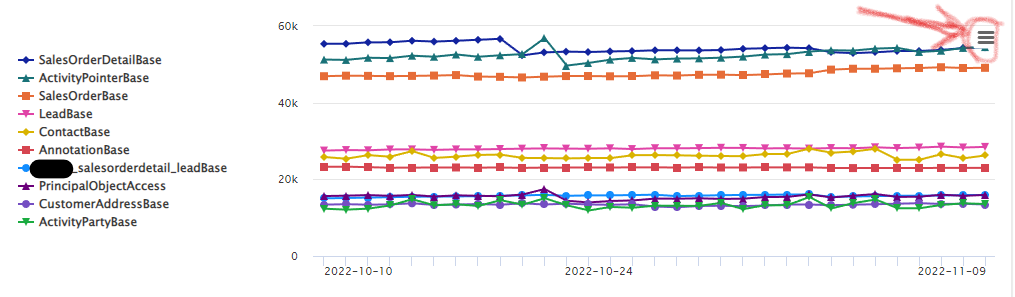
The first thing you need to start doing is to go through the biggest storage contributors. You can find which these are by looking in the Power Platform Admin Center under “Resources -> Capacity”. Open the view of each of the dataverse instances by clicking on the small chart symbol next to the instance.
You can export the full list by clicking on the hamburger symbol in the right hand corner of the graph. See picture below:
You can then start by trying to break down each table from the top. Based on the picture above, ask yourself questions like;
Do we need to store and save all orders? By removing some orders, maybe cancelled orders, we can cut down on two of the three largest tables as the order rows are removed at the same time
What activities are really causing activitypointer (the common table for all activities) to become so large? It is quite common that the email table is a culprit here, as the body of the emails, is usually a quite a few bytes and with thousands or tens of thousands of emails, they do add up. Marketing integrations can also bloat the activitiy pointer. I suggest investigating this further by exporting the data to an Azure Datalake and analyzing it with PowerBI. It is also quite common that not all emails need to be saved, for instance if you have email enabled queues like support@contoso.com it is quite common that you get some spam into this. Maybe searching for “unsubscribe” in email body to see if there might be some newsletter looking spam which enable you to remove them.
Are there any patterns of contacts and/or leads that can be removed? Working with B2C you might find that there are quite a lot of contacts and leads with incorrect data or similar. Ask yourself what value a lead with no phone number and no email has… removing contact data will also remove customeraddress as there will be at least two customer address records for each contact automatically created. The same goes for leads but in that case it is the leadaddress where extra data is being created.
The point with the list is trying to identify possible patterns of data that can be deleted. I typically have one row per rule like so:
Table
Method
Rule
Contact
Bulk Delete
status code = inactive AND modifiedon older than 6m
Email
Bulk Delete
body contains “unsubscribe” AND modifiedon older than 1m
Email
Flatten w Power Automate
Outgoing AND subject = “Covid information”
2 – Flatten verbose fields
Sometime it can be a good idea to just clean out or some “body” data. For example if you have sent emails to a lot of customers with the same Covid related information, the actual content of that email is the same for all and is known by everyone. Hence the body can be removed which can typically be done with a Power Automate Flow or SSIS/Kingswaysoft depending on the size of the data.
3 – Use virtual tables
Not all data needs to be stored in the expensive dataverse database. The recommendation from Microsoft is typically that data which you interact with should be in dataverse and the rest can be somewhere else. As it is now possible to use SQL as a source for virtual tables, as well as Cosmos DB and many other sources, moving data out of dataverse and accessing it through virtual tables can be a viable option.
Virtual tables is also something that should be considered when designing integrations. It is not always critical that all data actually reside in dataverse. Sometime just being able to access the data through dataverse is good enough. Especially if the data source is fast, it isn’t that much data, the data only needs to be accessed seldomly, It is also easier to use virtual tables if the data is read-only and used for reference.
4 – Use datalake for analytics
Dataverse isn’t really a good source for analytics. All endpoints (even the T-SQL) go through the application layer to the database. This makes large data crunching less than optimal in dataverse. This is also why Microsoft have developed methods for replicating the dataverse data to external stores. The just discontinued Data Export Service (DES) which synchronized data to an Azure SQL and the new Azure Synapse Link which synchronizes data to a datalake, are clear examples of this.
Hence, a good architecture for analytics of dataverse data is doing the analytics outside dataverse and the current best place for this is in a datalake with Azure Synapse Analytics.
This also has a direct implication on the data stored in Dataverse, the data you have in dataverse that is only needed for analytics, might not actually be needed in dataverse anymore. This can be anything from old orders, and of course all old communication like emails and phone calls. Datalakes are also way more efficient for doing large scale AI/ML analytics, which many organizations are looking for.
5 – Use datalake for archiving
If you havn’t already thought about it, a datalake can hence be used as an archive for data that you might need but isn’t actually something that you will use every day. Often a lot of data is stored for compliance reasons. When setting up archiving, it is important to make sure that what ever method you use, you probably want to keep the data in the archive after it has been deleted in dataverse, hence you might need to move the data from the initial storage container to the actual archive making sure to not actually move any deletes.
Microsoft have announced that they will be putting their own hot/cold-storage solution for dataverse into public preview this spring. This sounds a lot like some archiving functionality and I am certainly looking forward to seeing what it will be, how it will work and the licensing for it.
6 – Compress complex structures
For some businesses it is often needed to have quite a complex datastructure to handle the operations of what is done. It can be complex order structures with allocations of order rows to specific users or product configurations with billing, logistics and provisioning settings. Once an order has bee fullfilled in all aspects, it might not be required to store and keep all that complexity. It might just be required to keep the order header and the most critical information about what the order rows were about. Perhaps even flattened into a JSON or text field for future reference. If it is possible to move from a order header + 10 records in related tables to just a order header with a summarized text, for thousands of orders, than can save quite a lot of space.
7 – Clean up non-production environments
Data isn’t only stored in the production instances of dataverse. Many times production instances are copied and turned into test or staging instances. Integrations may be running towards development and test instances generating substantial amounts of data. Have a look at your non-production instances and check which data you actually need in them.
8 – Revise datamodel
Sometimes datamodels can become unnecessarily complex. This is most common when someone with little experience of dataverse and model driven applications design solutions. Other typical problems I have seen are repurposing of tables like leads, accounts, sales order to other simpler purposes. The problem from a dataverse storage perspective becomes that the additional storage overhead in these cases, especially in cases with businesses that have a lot of customers, can be rather drastic. Redesigning the datamodel to be more sleek can make it both more user friendly and use less storage.
9 – Revise integrations
Integrating data to dataverse can be a large culprit for data. For instance, many marketing applications generate quite a lot of data regarding the behaviors of customers. This data can then be integrated to dataverse to be used there. As behavioural data can be very granular, to the level of “Customer x has be send email y”, “customer x has read email y”, “customer x has clicked link z in email y” this data can take up substantial amounts of storage if integrated to dataverse. What options exist for this are different for different marketing applications. For ex Adobe Marketing can shut off this integration and can instead synchronize behavioral data to an Azure datalake where it can be unified with other dataverse data.
ERP integrations are also a common area of problem. ERP systems often have a very deep granualar level of data which might not be needed in dataverse/Dynamics 365 CE. Sometime just enabling deeplinking directly to the ERP system can be a better method, combined with virtual tables. However, this is not always the case and sometimes the best solution is just synchornization of the data.
However, do recognize that there should be a reason for having the data in dataverse. It should genrally be actively used.
10 – Set lifecycle for instances
Having dataverse instances with a bit unclear usage and not knowing what they are for and if they can be removed is, of course, a source of quite a lot of data consumption. By clearly assigning owners, reasons etc for all instances it makes answering the question “Do we really need ‘Internal test applications sprint 7′” or is it just an old remnant from a two year old development. This is part of the Center of Excellence starter kit and the processes that are important to set up in relation to this.
I hope any of these 10 tips have been useful. If you think so, the best way to thank me is to tweet or share your thoughts on this in social media. Also feel free to leave a comment below.
Perhaps you have some other thing that you think should be done or that I missed something. If so, please share in the comments below.
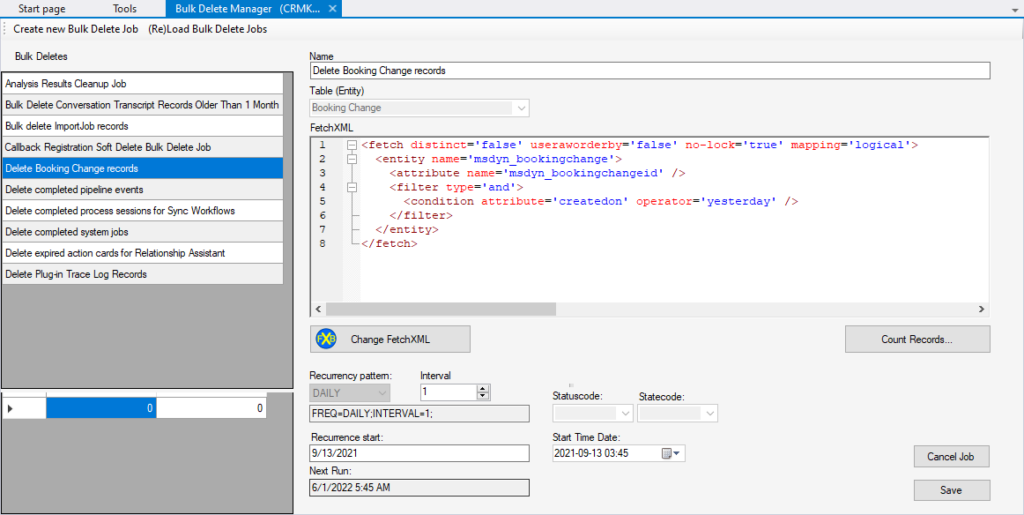
Have you ever tried creating bulk deletes in dataverse/Dynamics 365? It is still a very old interface and it is hard to control the exact definition of what is to be deleted as you cannot see the actual FetchXML that is being used. It is also hard to see existing recurring bulk delete jobs and what FetchXML they are using. Based on these facts, my colleague Ebba Linnea Nilsson and I decided to make our first plugin for XrmToolBox (XTB). We are now proud to announce that it is released and available for free (as usual in XTB). We have also identified a bug in the platform related to this, which I will describe below.
The bulk delete functionality in dataverse and hence in Dynamics 365 CE is an essential function for many organizations. This is especially true since GDPR was introduced and there is a strong legislative requirement to remove personal data that cannot be justified to be stored. There are also other reasons why the bulk delete functionality is more and more important and that is based on the capacity costs that can be inferred on a Power Platform tennant. Firstly just storing data, especially in the database storage in dataverse has a non trivial cost at $40/GB. There is a lot of value per GB, so it might not be justified to say that it is too expensive but removing unnecessary data is definitely something that can be worthwhile especially for larger implementations. I personally work with a customer in the travel retail industry which has millions of customers and some tables have 40M+ records. There are also a lot of integrations and automations causing a lot of data to be created. Data that at some point needs to be removed. As all data should, or there should at least be a conscious decision not to remove it and why if so. As you might be aware, if you have read my other articles in this blog, I have previously used SSIS and Kingswaysoft to remove massive amounts of data. However, now that the API Entitlements will be introduced (6 months after the report for API Entitlements is made Generally Available), we need to start to become more and more restrictive in using the APIs for massive data management, like deletes. Hence, we try to move as much as possible to the built in Bulk Delete.
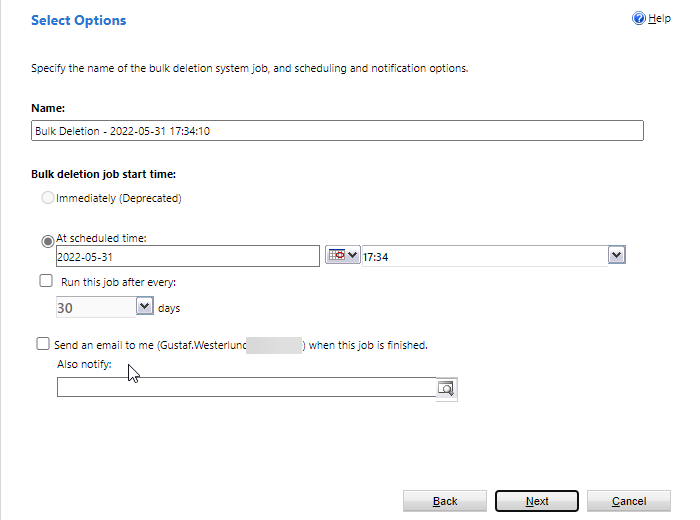
Working with the built in bulk delete functionality is a bit sad. It is very old and you have to click through a wizard kind of experience to be able to set them up. But the most limiting factor is that you cannot see the actual FetchXML of an active recurring bulk delete and you cannot input FetchXML directly into the bulk delete.
The Options page of the Bulk Delete Wizard
Having worked with this wizard you might also have noticed something a bit off. If you create a view which shows all contacts that have no activities. Then this will work when using it in the system like a view. However, if you try to use this view in a bulk delete it will “simplify” this and remove that part of the query. My thought that this was a limitation in the UI based on the fact that it is very old and hasn’t gotten any love for many years (decades). My assumption was hence that creating a bulk delete via the API would allow me to create bulk deletes that were based on FetchXMLs that you couldn’t even input from the UI. These were the reasons for us starting to create this plugin and it was so useful that I used it in debug mode for several weeks before finalizing it and publishing it.
Now we have released the first version and you can download it directly from XTB. I would like to give a huge thanks to Jonas Rapp who helped us out a lot with both connection to his tool FetchXML Builder but also the general setup of the plugins and the details of getting it approved as a Plugin for XTB.
If you have any suggestions, comments or otherwise, leave them on the GitHub repo https://github.com/crmgustaf/BulkDeleteManager or down below. We already have a bunch of stuff we want to do. Ah, yes, and the bug we found, it seems that the outer joins that was a rather recent addon to FetchXML is not supported by the actual platform. Hence the UI and the platform match in that perspective. Just to make it clear, what happens is that you input a FetchXML saying “All contacts with no activities” or something like that, which it will simplify to “All contacts” which is not really what you want.
As it is supported to create bulk delete jobs via the API, I do think that this still can be seen as a bug as there is no clear documentation on this or even a control when creating the bulk delete job with a FetchXML that will be incorrectly parsed. My suggestion is hence to implement the new FetchXML parser in Bulk Delete functionality, at least on the platform side. With the current setup, it is very possible that bulk deletes are created that remove a lot more than what was initially intended which can be very damaging to any organization. And from a GDPR perspective, this type of query is rather common, as it might be definied that contacts with no cases can only be stored for 2 years, but with cases for 10. To remove the ones without the cases, you would make the question “Remove all contacts with no cases with created on > 2 years”. This would then cause all contacts with created on > 2 years to be removed regardless of if it has a case or not.
To inform users of this, we have added a warning, every time a new bulk delete job is to be saved. Hopefully Microsoft will fix this soon.
On the page in Microsoft docs where they discuss API Service Protections there is towards the end of the page a part which gives some recommendations. Some are great, like the recommendation to use many threads and remove the affinity cookie, however when I read it I really bounced at the recommendation that batching shouldn’t be used. That just didn’t rime with my experiences of doing heavy dataloads to dataverse. So I thought I might just test to see if it was true or not by creating a simple script in SSIS with Kingswaysoft. My results, using batching compared to not using it gives more than a 10x performance increase. Continue reading to understand more about how I tested this and some deeper analysis.
Parameters and excel
The first thing I did was to create an excel sheet for storing all the results. I really did have to think about the different parameters that could affect the result, so I chose the following columns:
Dataload – how many records. This needed to be a bit larger to make sure that the throttling time of 5 min was passed.
Operation – Different dataverse operation take different amounts of time. For instance, creates are typically rather fast, but deletes, depending on table, can be a lot slower as the platform might execute cascading deletes based on one single delete. For instance, if you remove a contact with 100 tasks connected to it with the regarding relation set to “parental” or “cascade delete” it will actually remove all the 100 tasks. If set to “remove link”, the platform has to make an update to each of the tasks, removing the link. There are also special operations like merge which are rather complex.
Table – There is a large difference between the different tables. Some of the OOB tables have a lot of built in logic and really small non-activity custom tables can be a lot quicker to create, update or delete.
Threads – How many threads were used.
Batch – The size of the batches being used.
Duration / Duration (ms) – Duration is where I input the duration as a normal time. I created a calculation to calculate the corresponding amount of milliseconds.
Time per record (ms) – This is the division of the duration in ms with the total number of records. During this first test, I always used 100 000 records as the dataload, but it could be interesting in the future to see the differences between different dataloads, with all else being the same. This is also the main output from this test.
Strategy – It is possible to have different strategies. In this first version I just ran everything at once, hence I called the strategy “All at once”. Different strategies might be “5 on, 5 off”, meaning that you design the script to run superfast for 5 minutes, the throttling limit, and then stop and do nothing for 5 minutes and then loop this. Not always possible to use that kind of strategy, but for massive deletes of for instance market list members (cannot be removed with bulk delete) that might be an option.
API – There are currently two APIs that can be used. The new WebAPI which uses JSON payloads and the older SOAP API which used XML payloads. It stands to reason that the smaller JSON payload should cause the WebAPI to be faster than the corresponding SOAP API. However SSL encryption also causes the data to be compressed, which might make these differences smaller than expected. There is also a server side aspect to this, as the APIs will run through different parts of the code on the server side which could affect the performance.
No of columns – How many columns are being sent to the API. Of course there would be a difference if you send a create message with 3 columns compared to 30. Hence this is a relevant point. It is still a bit rough, as there is a huge difference in creating a boolean record, a 2000 character nvarchar or a lookup. This could also be something that was adapted.
Existing records – How many records existed in the system prior to running this? Not sure if this makes any difference, in other words, everything else equal, would it take more time to write 100k records to a system with 0 records or one with 10M records? As I don’t know, and cannot rule it out, I added it.
Latency (ms) – Daniel Cai, Founder of Kingswaysoft, always recommend that the SSIS script with Kingswaysoft be run “as close as possible to the dataverse”. That does in other words imply that the latency to the server affect the performance. Do calculate this, I used diag.aspx from the computer running the script.
Location – Which geo is the instance located in. This is more for general information, the latency is really the important factor here. The throughput might also have some affect if you are using a really bad line to the dataverse. I was using a wired 1 GBit line. In this test, I was using an instance I got hold of as MVP, which is located in the US and my own stationary computer at home (a AMD Ryzen 9 3900X 12-Core Processor 3.79 GHz with 32 GB of memory). Hence the latency was rather high and not in line with Daniel Cai’s recommendations. It is hence also something to investigate further.
No of users – As I, and some others in the community have described, throttling is based on a per-user and per-front end server basis. Hence utilizing several service principals/application users can effectivly multiply the throughput. In this test I used just one.
Instance type – It is well known that sandbox instances do not have the same performance as a production instance. If you find Microsoft support on a happy day and you are working with a larger (no of licenses) instance, you might also get them to relax the throttles a bit, especially if you mention that you are doing a migration. As these factors strongly affect the performance of large dataloads, I did have to add this. During this test I was using a non-enhanced production instance, in other words, a production instance on which no throttles had been relaxed.
DB Version – The final parameter that I thought might affect this is the actual version of the dataverse instance. As improvements and god forbidd sub optimal “improvements”, can cause enhancements or degradations of the performance, this is necessary to document.
SSIS/Kingswaysoft setup
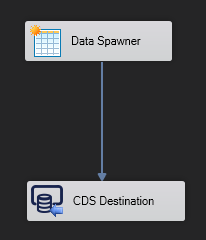
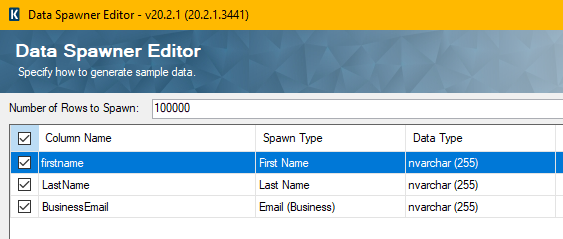
For setup of create tests in SSIS with the Kingswaysoft addons I used a dataspawner (productivity pack) to generate the data. I then just sent this directly to the CDS Destination.
And the Data Spawner config:
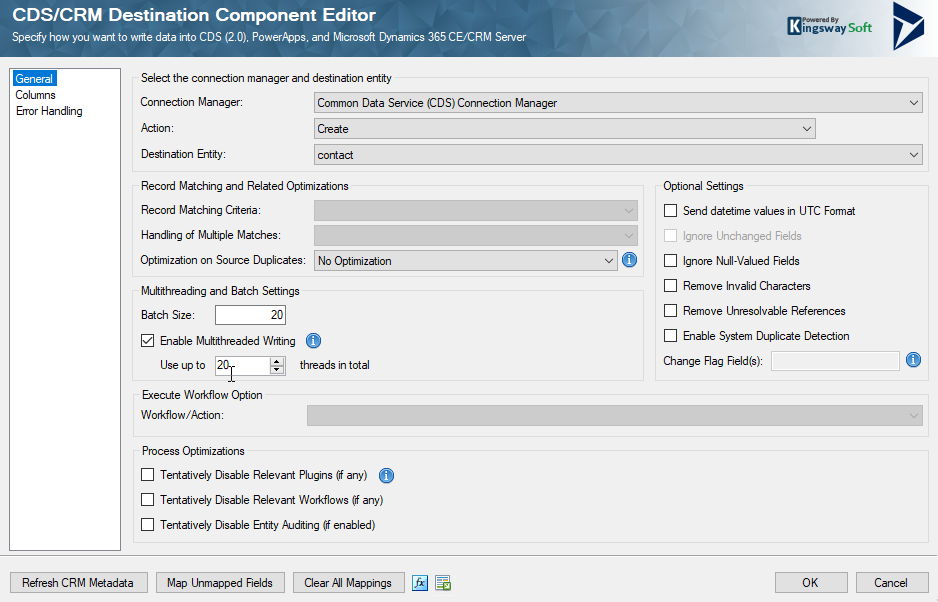
And the CDS Destination config
The main changes done in this case were to the parameters “Batch size” (set to 20 in the picture above) and how many threads to use (also set to 20 in the picture above).
After each run, I checked the log from SSIS to see how long the entire process took. Due to the fact that I have a computer with many threads and for this case, enough memory, it is my perception that most of the threads allocated were also used.
Results
What are the results? This is a picture of the excel:
As you can see I did try both Create and Delete operations, but the results are rather obvious.
20 threads/20 per batch of both create and delete, took around 45 minutes
Reducing to 16/10 made only a minor difference – 48 minutes
Microsofts recommendation of not using batching, ie 20 threads/1 batch – took over 10 h, both for delete and create.
Using only 1 thread with 1 batch was more or less the same as using 20/1
1 thread with 20 in every batch (1/20) took almost 5 h, which is around half the 1/1 or 20/1
I think the results clearly show, that Microsoft docs are currently incorrect in their recommendation to not use batching. Perhaps they will update this soon. From an entitlement perspective, one needs to understand the additional cost of the “batch unpacking” request that is made. With 20 in every batch, this is an overhead of 1/21 but if you would lower the batches to 4, it would be 1/5. Hence using as large batch as you can, without loosing performance, is generally what I would recommend.
As I have implied in this article, there are a lot of other parameters to investigate in the API. I have a hunch that a create with 10 lookups compared to 10 textfields, will also make a significant difference, but I will need to test it.
Also do consider the request timeout. When working with complex and large batches, one request may taker quite some time. You will know, however, as it will return a timeout exception if you exceed it. Note that some records in that batch may have been written anyway. Just that your client wasn’t waiting around for the answer.
I do also encourage others to try out other parameters in the API. What is really optimal from many different aspects. From a mathematical perspective this can really be seen as a multidimentional surface where we are attempting to find the highest points. I have now started this journey, and I hope it was an interesting read. Please leave a comment, if you have any experience to share or just want to comment.
I was recently in charge of a large migration. It all went fine but not without hickups that typically are connected to moving large amounts of data to dataverse. We were using SSIS with Kingswaysoft and ended up using a local SQL database as staging database too. This article will discuss the different lessons learned and give some concrete tips when doing similar migrations.
One of my more popular articles is the article that describes how to optimize the writing of data to Dataverse/CDS. If you are working with migration of large amounts of data, as I will be describing here, I do suggest you have a look at it: https://powerplatform.se/fast-data-management-in-a-limited-cds-world/. I will not discuss those concepts in any detail here but we did use all aspects mentioned in that article.
I recently was in charge of a migration which used CSV-file exports from an old German system (with German field names!) which had many millions of records, in both large tables like “Contact” and “Sales Order”. However, the system we migrated from had a completely different data modell than the one used in Dynamics. For instance, each row describing a “Flight” had to be divided into two rows, one for the outgoing flight and one for the homecoming flight, in the order detail table. We also had to create a lot of related data which was referenced from the “Flight” table, for example location, agent and brand. In other words, there was quite a lot of heavy transformations going on and a lot of logic involved, such as change format on the old data to match the Dataverse model and apply rules to resolve old issues, such as bugs.
Initially we only got a quite small subset of the entire database load, and we started our migration journey by creating all the migration logic in SSIS (which facilitates the script and makes updates easy to handle). The script did include some functions that “joined” rather large tables, both from the CSV files but also related data fetched from the Dataverse based on primary and alternate keys. I was clear with the customer from the very beginning that I wanted a full export with the same amount of data that we could expect in the final migration, mainly for the opportunity to stress-test the SSIS script before the migration to the production environment took place and after a while we got the big files…
…And this was when the excrement hit the wind generator. The afore mentioned lookups just stalled forever. We noted that having a lookup (using Kingswaysoft Premium Lookup) works fine on a computer with 16 GB memory up to a few 100k of records. However, once the data starts reaching 500k and more, it just stalls forever (and don’t even get me start on the sort tools…). Not sure exactly if it would have been possible to fix this by adding more cores and memory, we didn’t try. We hence had to rewrite the script and implement a staging database instead. What we found, is that a dataflow with 1M+ records of lookups will be 100x faster if you import the data into SQL and do a join instead. Lookups still works for smaller tables and I am not against them per se, as they do make the migration simpler. Adding more tables to a migration database will increase complexity, and if you want to add a column in a table, that table do not only has to be added to one SSIS dataflow, but probably a few more. And you also must do an ALTER TABLE in SQL to add the field there too. It is therefore important to have a good mapping set before you start to create the script. And keep the complexity as simple as possible. You can also use SQL tasks in the migration script to update the tables straight after you read them to the staging database per automation, if you need to apply some kind of rules after the read to the staging database, and find it easiest with an SQL query.
The method we used for developing the migration was to first make a “skeleton” migration, based on the target data model. In other words, we started with trying to get a few of the easiest fields, not all, from all tables that was to be involved in the migration – maybe it could be called – model-first-approach, instead of starting with one table, completing this and then moving on to the next. The advantage of the model-first-approach is that you quite early can start some tests on the data, for instance setting up some quantitative test by checking in the source system for the quantities of contacts and then comparing these quantities to the target. The tests can typically be done by other people than the people building the migration scripts and hence this methods scales a lot better than table-by-table-approach. It is also possible for several devs to work in parallell with different tasks. Typically the more senior will build the skeleton and then more junior can add fields by field to each respective table. A negative aspect of this approach is that it requires a lot of re-loads (keep in mind that this was a first migration, so there are no prior data in the Dataverse that we needed to consider) and re-mapping. And it may be easier to “fall out of” the structure, if you just need “to add a little bit here and there”. It is however indeed hard to go table for table, especially with related data. If you already have a lot of live data, you should think about a way to easy identify the migrated data so you can bulk-deleted. And do not forget to engage the client early with raised questions and the mapping to make sure you have understood everything correctly and avoid unnecessary errors.
We also tried to create unique row identities that strictly was based on the source data. This is very useful as that allows for delta-migration, or to continue where we left off in case of a problem. Let’s say for instance that you want to migrate 3 million contacts. If, after 2.1 Million contacts the script breaks for some reason, it is good to be able to continue at 2.1M instead of restarting. In this case we didn’t use modifiedon-date to be able to do a full delta migration logic but it is certainly possible. For this we used the cache-transforms, easily fetch the already migrated data (if any) with the unique and sort out the already migrated data if it matched the key.
Another pattern that we used was that, after creating a specific record, like contact, we reimported the recordid (in this case contactid) together with the legacyid. This allowed us to directly join with this table when later adding tables with dependencies like lookups towards the contact table, could be joined with this mapping table so that we directly got the contactid when querying the related table.
Tips
When migrating from CSV, import them directly as source tables in the staging database. That way, in case you need to fix something, you have a good reference for quantities.
Get an example of the full data load as early as possible. A script that works for a subset might not work at all for the full dataload as was the case for us.
Automate as much as possible. Don’t use any hardcoded values that are environent specific, such as transactioncurrencyid, but rather read these to small tables or to SSIS variables. Use SQL Truncate to remove all data quickly in a table, and make this part of the SSIS script as an SQL task at the appropriate stage.
Always check the quantities. How many rows in source data, how many rows after a match and check if it differs so you very early can identify bugs in your script that might be the reason for dropping rows. For example, you might use a JOIN when you should use an OUTER JOIN. Always check the total number and see if it is what you expect. Watch out for duplicates, and always check so your unique IDs (if you got some from the source data) really are unique and not NULL. Do note that if you have duplicates, that you join on, that will create multiplications. Hence it is possible, after a select-statement with joins to get more records that the initial table.
Define reasonable goals and test cases for the migration. Some examples:
99.9% of all contacts to be migrated correctly. With 1 M records, this means that anything lower than 1000 incorrect migrated contacts/missed, is defined as still ok.
Randomly pick 10-20 records on a base level, like 20 customer, and then compare these in the UAT/Test environment to the source system, as it is seen there. This needs to be done by the business people, so that they can have a say if the migrated data is fine.
Select some filters, like “all customers in Munich” and some other segmentations and compare source system to destination. If there are large amounts of errors, backtrack to the staging database to see where you did loose some records or created too many (not uncommon).
Complete entire transformation to destination tables in the staging db. Then you can move directly from there to dataverse. This is particularly important when moving large quantities of data when managing the data in SSIS can be problematic.
Make sure to have unique identifiers on all tables that preferably can be regenerated from the data. Store these in some “Legacy ID” field. This allows for delta-migration logic, ie. where part of the data is migrated and then the rest later. If you have some issues during one of the dataflows, and it stops on 3 230 234-th record of 6 M, you can continue from there and you don’t have to redo it all. If there is no decent way of getting a legacy id, you can generate classic row numbers by creating an identity column. This will make the migration utilize this, but only within that particular instance and load of the staging db. Hence you must be careful everytime you reload the database.
Utilize the backup-restore functionality of the dataverse environments. Do note that you can make manual backups just before you start migration. If you have a production environment, this will need to be converted to a sandbox environment before you can restore to it. Another option I got from a colleague was to use 3 different environments, with temporary names, and then just rename the final one when done.
Once you have transfered an entire table to the source system, it is typically very useful to have a mapping table, with just the table record id and the legacy id. So for instance, after migrating Contact, read all contacts from dataverse with the contactid and the legacy id. That way, when later migrating “salesorders”, which identify the customer by legacy id, it is easy to just join with this table to get the contactid.
Production environments are faster. Fastest is to ask Microsoft Support to relax throttles on all environments that are used during migration.
Use a VM that is located geographically (or really with low latency and high throughput) to where the environments are hosted. This is a very common recommendation by Kingswaysoft too.
The settings for number of threads and batch size needs to be set based on some factors, namely:
Production/Sandbox
Have throttles been relaxed
Size of payload (ie how many columns) – larger payload -> smaller batches.
Type of action – creates are faster than deletes. Updates are in-between.
I hope these tips can help you along. If you have any comments or you have other experiences in this subject, don’t hesitate to leave a comment.
During this migration and the writing of this article, I had excellent help from my highly intelligent colleague Ebba Linnea Nilsson and it is certainly true that two heads are better than one, and the end result is often a lot better than just the sum of two people. So for my final recommendation, make sure to have a good colleague with you to help you out, as you most probably will run into some issues and having someone to discuss with is really great!
As I mentioned in my previous articles, I am trying to investigate the details of how the entitlements and API Service Protections are working and are planning to be rolled out (in the case of entitlements). I had a very interesting call with some of the nice people in the product team last which shed some more light on the entitlement issue and the best practice of how they suggest the API is to be used. The suggested method is that the API request load be spread out over the different users in the instance/tenant using impersonation. I will walk through what this means and what I think about this in the article below.
First, if you have not read my previous post on entitlement, I do suggest you do this first. It describes what entitlements are compared to the API Service Protection. I still see a lot of people mixing these up and that is not strange, but they are two different aspects of this, and we need to keep track of what we are talking about.
As mentioned in that article, the point of the enacting the Entitlements, when that is coming, which still is a bit unclear, is so that the compute consumed by a small organization is proportionate compared to a large organization. So, let us go back to the actual per-user licenses and have a look at an example.
Let us say we have a 5 000 Sales Enterprise org, that means that we get:
5 000 users who each have 20 000 API request entitlements.
100 000 API Requests for non-licensed users.
Compare this to a 10 Sales Enterprise org which will have.
5 users who each have 20 000 API request entitlements.
100 000 API Requests for non-licensed users
Both these are totally independent of how many instances the first or the second org has.
The first observation is of course that the 100k API Request for non-licensed users do not scale at all with the size of the organization or the number of users. How does this then go in-line with the goal that a large org should have more compute than a small? The second observation is that 20 000 API requests, which actual also the normal UI will be using, is very large. You would have to be one busy salesperson to be able to generate 20 000 API requests manually in 24 hours, so busy I am tempted to say it is virtually impossible to break unless you have very heavy automations running under your account. This was also what the Microsoft rep I talked to mentioned, that this large number is to be used on a per user basis. Hence the natural question was, if we use impersonation in the API, will the Entitlements honor that? The answer was unequivocally: yes.
Hence, this is the clear answer on how we need to create future integrations. We need to spread the load using impersonation over many of the users in the system.
If we do this the right way, it would probably be possible for most organizations to, over time be able to build a fix for this.
However, it will not be easy as we need to have a tight control of the privileges of all the users. Let me give you an example from a customer I work with:
They are an online travel agency and have people working at the destinations with very restricted privileges. A lot of bookings (orders) are integrated from the booking systems, these should hence be spread out over many users instead of the single application user being used today. There is not natural user to direct the bookings to, as it is a B2C business, and no person at the travel agency “owns” these customers per se, so the load needs to be distributed in a more randomized fashion. So, let us say we have these users:
John Smith – System Admin (Full access)
John Doe – Power User (can create orders but not refunds)
John Surf Dude – Destination Specialist (can view but not create orders, cannot even read refunds)
When rebuilding the integration, we can use user John Smith and John Doe but not John Surf Dude and the only way of generically knowing this is checking what we want to do and comparing this to the privileges of each user to get a shortlist of users that can be used for integration.
However, we do not want to use a user that is close to 20k API requests for that day, so we might need to query the current API Request entitlement usage per user, so that we can filter the current shortlist to an even shorter list before knowing which users to use for impersonation.
Analysis
A way forward. I think this can be used, although there are some tricks to it. For my customer we might be able to cut a significant amount of API calls this way which will make a huge difference when we compared to not using this technique.
Impersonation not always viable – as in the example above, when there is not obvious owner to link to, we need to figure some other logic out of how to spread the API entitlement load. And things start to become tricky.
Impersonation is complex.
Impersonation requires more complex code. For several reasons. And the risks for errors are a lot larger as changing users is tricky. It is not strange that Microsoft still have not implemented the feature idea to be able to do user impersonation in the Power Platform UI just shows that this is less than trivial (https://powerusers.microsoft.com/t5/Power-Apps-Ideas/Allow-Admins-to-login-as-Users/idi-p/215779)
More complex dependencies on security model As mentioned above, trying to execute an action as a user that does not have the correct privileges won’t work, so we need to know that first. And setting everyone as System Administrator just will not work.
Logical user or just random users – trying to map the users to some logical connection from the other system or just randomizing the load. Logical user is probably preferrable but probably will not be a very common pattern.
Integration often system-to-system not user-to-user
Integrations are more often done on a system-to-system basis, not user-to-user basis. When looking at CRM-ERP integrations for instance, the user base of these two systems seldom overlaps except for a few users.
Takes time to refactor code to handle impersonation – There are many organizations out there with numerous complex integrations. And changing integrations on this level will require significant work to be done and the question will be if there is time to complete this work before the entitlement feature goes to GA?
Strange audit trail – if we use randomized users to update or create data in dataverse that will undoubtedly create very strange audit trails, created by and modified by fields. These are some facts that need to be taken into consideration.
Power App – per App users have very few requests – Not all licenses have 20k API requests per 24h. The Power App per App has only 1000 API Request entitlement per 24h, these can run out just by a using the system heavily. So do consider the API Entitlements when looking at the licenses.
Still not GA – Entitlements have still not gone GA. Hence the best time to let Microsoft know what you think is good or bad about this is now. But do be civil, there will be some feature like this, that will handle fairness management of compute consumption. Contact Microsoft through your local User Group, your local MVP or via the comment below or send me a message on LinkedIn and I will put you in contact with the right people. You can also submit an idea to the idea portal.
There might be a point to binding all entitlements to users, in the case that if, in the future, any overshooting would not only result in angry emails, but service degradation or shut-off for that user. Imagine having creative citizen devs creating some infinitive looping Flow or massively recursive logic unknowingly which causes a lot of requests. This approach would then just cause a block for that user, not the entire tenant. Significantly reducing the severity of the problem.
Suggestions
Personally, I think this method is just way to complex. I think just having a simple pooling on the tenant level of all the API entitlements would be fair and then deducing all usage from this. I think that Microsoft could skip the 100 000 for the non-licensed user, for simplicity. Based on the examples above, that would make:
5000 Sales Enterprise
5 000 users who each have 20 000 API request entitlements.
Total API Entitlement for the Tennant: 100 M / 24 h
5 Sales Enterprise users
5 users who each have 20 000 API request entitlements.
Total API Entitlement for the Tennant: 100 K / 24 h
And all users, and all non-licensed users use from the same pool.
As for the potential problem of creative users potentially blocking the entire tenant, I would suggest adding a “per user” API request limit, which can be changed by the admins, but by default is set at exactly the same as the entitlements. That would allow admins to reduce the limit to 10k for enterprise users, to ensure the server-to-server integrations were still enabled in a proper and entitled way.
I think this would align with Microsoft’s goals and make it easy to understand for customers and we do not have to rewrite tons of code and make strange workarounds. But maybe there is something I am missing. If so, and you see it, please leave a comment!





Recent Comments