There are scenarios in CI-D when it is integrated with Dataverse where you may run into a bug with the platform. This is when one of the COLA (Contact, Opportunity, Lead or Account) table records has the lookup Customer Profile pointing at a customer profile that isn’t there any more. In other words an orphan link, something that typically should not exists. I will start by describing a scenario where this can occur, what problems it can cause and how to fix it, both short term by you and long term by Microsoft.
When does it occur?
This problem typically occurs if you have chosen to have more contacts in dataverse than you have in CI-D. The most common reason for this is that each 100k of unified profiles in CI-D incur an non-trivial licensing cost per month. Hence skipping the least valuable customers could be a way to reduce this cost. The problem, on a more technical note, is of course that you will have to filter the customers before they are ingested into CI-D. The new filtering functionality in CI-D that is about to be released will probably help with this.
So, let’s say for the sake of an example that we are only keeping customers in CI-D that placed an order with us during the last 24 months. This means that if you have a customer that yesterday was included, it could pass the threshold and be excluded today. Hence it was synchronized to dataverse yesterday with the rehydration functionality and the corresponding contact record was linked to the customerprofileid with the COLA Backstamping functionality. However, today, when the synchronization happened, this contact is no longer part of the unified profiles and hence is not synchronized to dataverse. However, the COLA backstamping functionality does not clean up after itself properly and hence the customerprofileid lookup on the contact record that was set yesterday, is still set BUT as there is no customer profile that corresponds to this anymore, there is an orphan link.
What problems can it cause?
Let’s say you have an integration that might not as specific in its data processing as is best, and hence it reads all fields from dataverse, changes some and then writes all fields back, instead of just the ones that were changed. If this happens to a record with an orphan lookup link then when you try to save the contact to dataverse, the platform will throw an exception saying that the customerprofileid is incorrect/not pointing at a real record.
How to fix it yourself
The easiest fix you can do is probably to write a Power Automate flow that loops through all contact records and verifies that the customerprofileid is set to something that actually exists.
Another fix is to rebuild the integration so that it only changes fields it actually has a change for. This, does require some extra coding, but that code could be rather generic so that you can use it more. This change will also make your code execute faster. It does, however, not actually fix the problem, just removes the symptom.
For field and table reference, below is a FetchXml that will return the contacts that have the lookup field set and one for all customer profiles. I have tried combining these in an outer left join to get the ones that are incorrectly linked, but there is a limitation in FetchXml that is stopping this.
My suggestions to Microsoft on how they should fix it
There are two different ways to solve this from a Microsoft side, one is on the CI-D integration side and the other on the dataverse elastic table side.
First of all, I think this is an incorrect implementation by the CI-D team. Elastic tables currently do not respect cascade rules like “remove link” and this should be a known fact. Hence they should implement a function that after the backstamping is done for all existing records, it should clean up any customerprofileid:s that do not have a corresponding record.
The second alternative solution is for the dataverse team to implement functionality to respect some of the cascade rules, in essence making sure the dataverse platform cleans up any links to records that do not exist. The positive side of this would be that this fix would help any lookup pointing to an elastic table, as this is most certainly not limited to just the CI-D integration, but the negative side is that this would affect the performance of elastic tables, especially during deletes.
When measures are created in CI-D to be used in CI-J there are dependencies created which will stop you from removing the measure. CI-D is not very helpful in telling you how to remove it. I will try to be a bit more helpful.
When trying to remove the Measure this is the error I got:
Error: Detected DataVerse dependencies in Measure: ListMemberships. Please delete these dependencies and merge again.
Request ID: 14056846-b9c1-4ec8-98c2-88778e518b88
Time: 2024-12-05, 11:12:10
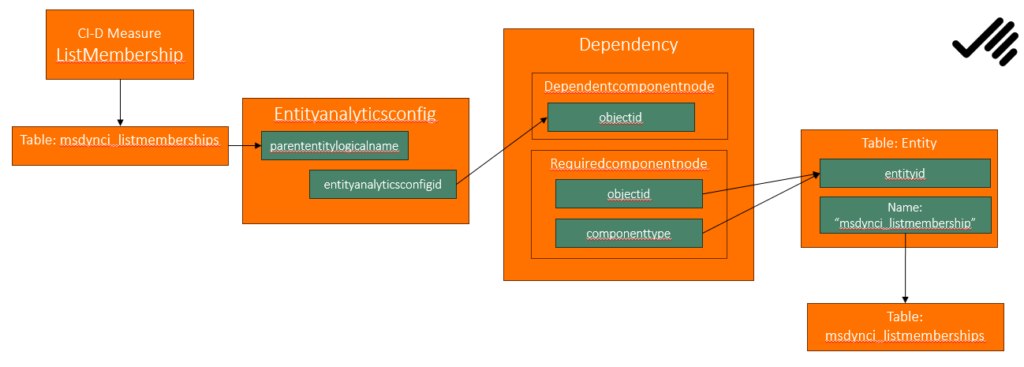
My investigation below with the help of Microsoft Support lead me to the understanding according to the image above. As you can see dependency is actually sort of circular, or at least one part of the dependency (dependent component) is at the entityanalytics on the record which points to msdynci_listmemberships, on the other hand (required component) on the table msdynci_listmemberships.
The fix, is to remove the record in entityanalytics. Easiest way in this case, is to just use a browser console where you are logged into the right Dynamics.
To remove the entityanalytics record that is blocking this:
After this I was able to remove the measure in CI-D.
Below I will detail the steps I did to understand this.
The first step is to look in the table “entityanalyticsconfig” searching for the name of the Measure. Its name is “msdynci_” + name of the measure. Check out the metadata if you are unsure.
Hence, from this I generated the image above. Since it is something of a circular reference, Microsoft Support suggested that I remove the entity analytics record with id: e46e52db-46a7-4585-8a6a-6ba888a5bd1f. However, not entirely sure what this is and hence I tried the one I had gotten in the first steps above, and that worked.
Generally I think it is a good idea to investigate what the dependencies point to, before removing something. In this case the dependency record in itself wasn’t removed, only the dependent part.
Thanks to Microsoft support for helping out with this and I hope it might shed some insights if you are having similar issues. I also think breaking down the dependency table in a tool in for instance XrmToolBox would be a great idea. I have a bit of a bad conscience for BulkDeleteManager that I own and I am not giving enough love, so feel free to build it based on this and I guess some more stuff. I will be happy to help out the the investigations if you are willing to build it.
When you create an instance in dataverse you get to choose which region it is located in. However, you do not get to choose which exact datacenter you get. How is this important? Well, if you want to mirror data using Azure Synapse Link or Microsoft Fabric, then these resources have to be in the exact same datacenter to work. If you have several instances, there is a risk that some are in one of the datacenters in the region and some in the other. For instance, in the region Europe, there are two datacenters, North Europe (Dublin) and West Europe (Amsterdam). So, it might very well be that some instances are in Dublin and some in Amsterdam.
Currently there is only one way to move an instance, and that is to create a ticket and ask Microsoft Support to do it for you. But you first need to know where it is.
The easiest way to find where you instance is located, is actually to start the wizard for synchronizing data to a datalake using Azure Synapse Link from the Maker-portal. It should look something like this:
However, if you have many instances, you might want to have a script that outputs this. Well, I did anyway, so I was looking into how to do this using Powershell.
Hence I dug into some of the PowerShell libraries for Power Platform and created this PowerShell script:
# Get all environments
$environments = Get-AdminPowerAppEnvironment
# Loop through each environment and output DisplayName and azureRegionHint to a file
$environments | ForEach-Object {
# Create a custom object with the properties you want
[PSCustomObject]@{
DisplayName = $_.DisplayName
Type = $_.EnvironmentType
azureRegionHint = $_.Internal.properties.azureRegionHint
}
} | Export-Csv -Path "C:\temp\output.csv" -NoTypeInformation
In this case the “azureRegionHint” was supposed to show the right datacenter. But that turned out to be a half-truth as many of the instances were correct but not all. I suspect it might be stored list and not the actual list, as at least one of the ones that were incorrect has been moved.
I reported this to Microsoft support, as my view is that the azureRegionHint should display the correct datacenter, and hence what I experienced is a bug. But I never got this acknowledged by support who instead recommended that I use “ping” to figure out the region;
C:\Users\GustafWesterlund>ping xxx.crm4.dynamics.com
Pinging db3--eurcrmlivesg000.crm4.dynamics.com [52.155.235.153] with 32 bytes of data:
Reply from 52.155.235.153: bytes=32 time=56ms TTL=107
Reply from 52.155.235.153: bytes=32 time=55ms TTL=107
Reply from 52.155.235.153: bytes=32 time=69ms TTL=107
Reply from 52.155.235.153: bytes=32 time=75ms TTL=107
Ping statistics for 52.155.235.153:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 55ms, Maximum = 75ms, Average = 63ms
In the response above, db is “Dublin” and my guess is that the “3” means datacenter 3 or something like that.
However, using ping to do what in essence is a nslookup didn’t seem very useful and I also wanted to be able to use PowerShell, so I looked up the command:
Resolve-DnsName -Name $url
This is in essence nslookup, which, if you are not very versed in this, will give you the IP address and official name of a specific alias (cname). As the following example shows:
PS C:\WINDOWS\system32> Resolve-DnsName -Name xxx.crm4.dynamics.com
Name Type TTL Section NameHost
---- ---- --- ------- --------
xxx.crm4.dynamics.com CNAME 300 Answer db3--eurcrmlivesg000.crm4.dynamics.com
Name : db3--eurcrmlivesg000.crm4.dynamics.com
QueryType : AAAA
TTL : 300
Section : Answer
IP6Address : 2603:1061:2002:968::36
Name : db3--eurcrmlivesg000.crm4.dynamics.com
QueryType : A
TTL : 300
Section : Answer
IP4Address : 52.155.235.153
The first part is the information that the DNS entry is a cname/alias to the aname which starts with db3. The following two blocks are the IPs in IP v6 and IP v4 of this name. Using this I adapted my script and added a manual switch which shows the datacenter which starts with “ams” as West Europe and “db3” as North Europe. Don’t know if this information is available anywhere so that I can look it up instead as that would be a lot more dynamic. But at least I can loop through all instances and get the azure datacenter for each of the instances. Here is the script:
I hope and guess there are easier ways to solve this. If you have any ideas, please let me know in the comments or if you have any other method to solve this for a lot of instances where using the UI would be a bit too much of a hassle.
I was recently helping my colleague Ebba Linnea Nilsson with a support ticket with data not being propagated correctly from dataverse to a datalake via Azure Synapse Link. It turned out that this was all by design. A design that might not be what normal users would expect.
Calculated columns and now recently the formula columns are both very useful way of being able to calculate data in a field that is based on other fields. Common scenarios are calculations like “Weighted revenue” which is the probability multiplied by the estimated revenue for an opportunity. However, there are scenarios where you need to be aware of how these fields actually work or you might get an unwanted or unexpected behaviour.
The first thing that needs to be understood is that these column types are calculated “on-the-fly” everytime dataverse attemts to access these columns. It might seem like the data is “in the columns” but it really isn’t, it is calculated. This is a big difference from for instance rollup-columns is that those columns are calculated on a regular interval by the system, and the result is stored in the record.
What does this mean for Azure Synapse Link? Well, let’s say we have a simple calculation, that sets the value “A” into all records for this calculated column. We then enable the Azure Synapse Link which will make an initial sync and set the column in the datalake to “A”. Now we change the calculation of the rule to output “B” instead. As no records are actually changed, this will not cause any records in the datalake to be updated, hence they will all still have the value “A”. From a user perspective comparing Dynamics 365 to the datalake without any underlying understanding of how this functions, it will look like an error. Same column has different values comparing what is in dataverse with what is in the datalake.
As soon as a record is actually changed, all columns for that record will then be sent to the datalake, and hence the calculated column will be set to “B” at that time. It is hence possible, to manually or semimanually force a resync, but it would require some bulk like for instance SSIS with Kingswaysoft especially for implementations with large amounts of records.
An important question to ask, is why would you want to calculate the data in dataverse and then use it in in the datalake. If you have a propper datalake architecture it should be easier to make calculated columns/fields in the datalake/datalakehouse. If the data is calculated only for use in the datalake, I would suggest moving the calculation to the datalake.
There are, of course, scenarios when it is preferrable to have calculations in one place and reuse the output in many places. However, this understanding of what can reasonably be expected is then essential.
As for product improvements, I have added an idea on the subject, if you agree with me, please vote! Microsoft Idea (dynamics.com)
A final note is that this type of unexpected behaviour is not limited to just Azure Synapse Link but really to any integrations based on either “modified on” or change tracking without doing periodic synchronizations. Hence I would also like to give a general warning about this.
The long awaited Long term retention feature for dataverse is now in public preview. You can read more about it on Microsoft Docs.
This is really a good functionality that many of us working with larger customers that have a lot of data, and hence paying a lot for it, have been waiting for.
It is a bit hard to test, and as it is preview, it is not recommended to be used in production. The reason is that for larger organizations, the cost of having a lot of data in non-production is usually too high to justify it. Due to this reason, I have a ask, that if you think this is an interesting functionality, please try it out and send any feedback to Microsoft on the idea-site. I have sent quite a few, and please vote for any ideas you think are good.
The key question, is of course, what the cost for storing data in the long term storage will be. As the data is stored in an internal datalake (from what I understad), I would presume it to be closer to file-storage costs than the db-storage costs. But i guess we’ll all see soon.






Recent Comments