When working in CI-D and replacing a datasource with another, for example replacing Power Query Datasource with Delta, then finding any dependencies for this is important. This is a tip that I got from Microsoft Fast Track Architect Ashwini Puranik, so credit should go to her. You can use the API testing functionality that is part of CI-D to query the ListAllMeasuresMetadata. Keep on reading to get some more details.
As the general recommendation for CI-D is to move to Delta-based data sources from Power Query due to performance. However, doing this shift will require you to reroute all dependencies to the new table before you can remove the data source.
Below is a way to find the dependencies based on Measures and Segments defined in CI-D.
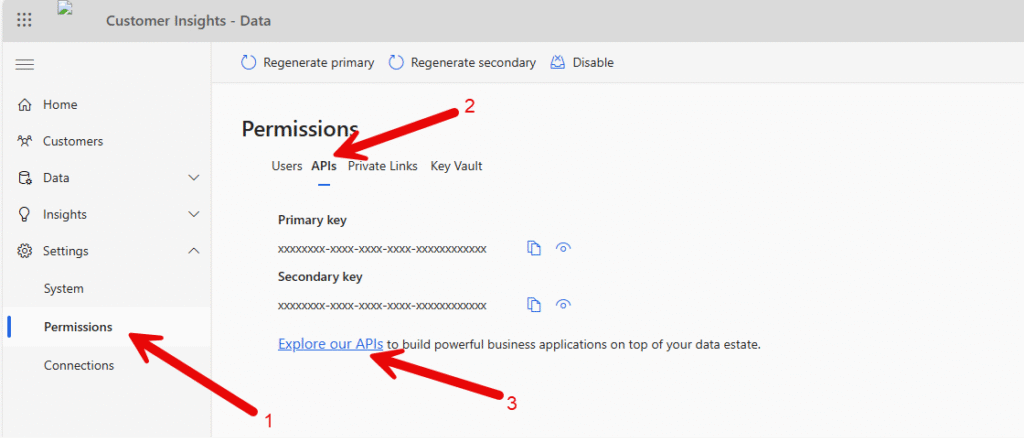
Start by going into the API testing tool that is available for CI-D using the Permissions-area and the tab “API”.
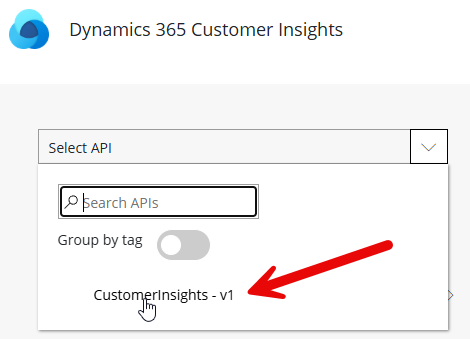
Choose the only available API, Customer insights – v1.
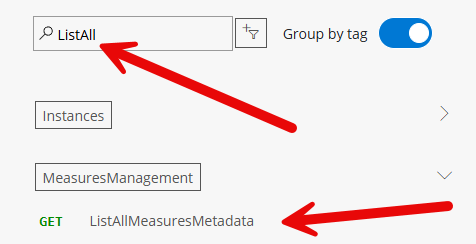
Now search for ListAll and select “ListAllMeasuresMetadata”.
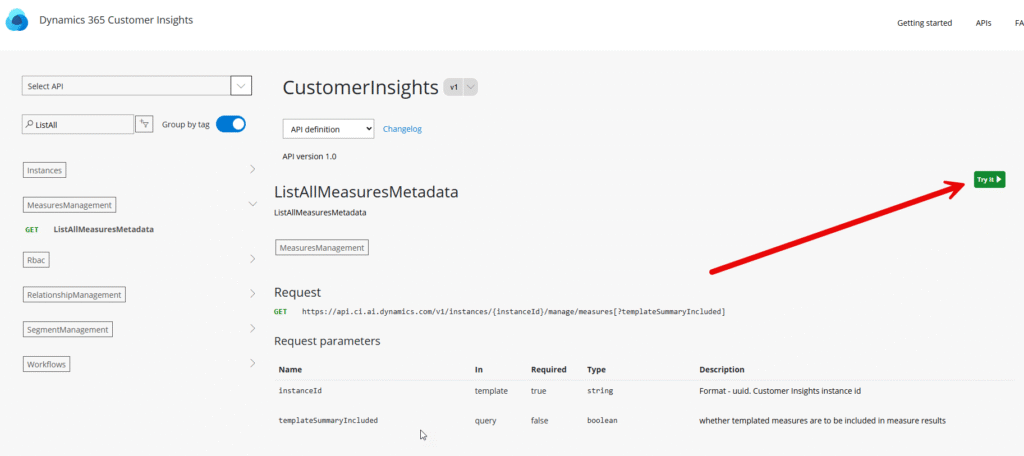
This will show a more detailed description of the endpoint. Now click “Try it!” in the green button on the right hand side.
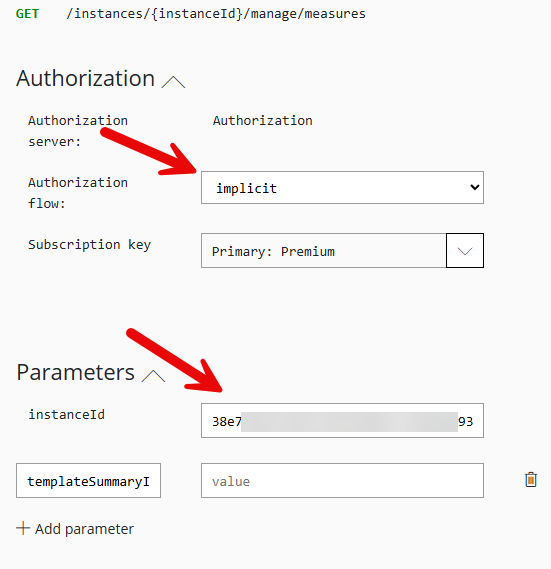
This will show a panel on the right hand side where you have to input some required data. For an easy test, just select “implicit” in the Authroization drop down and put the instanceid into the field for it. In case you don’t know where to find the instanceid, you can grab it from the URL when you are using CI-D using the normal UI as it is the only guid in the URL.
That is all that is required, so scroll down to the bottom and press “Send”
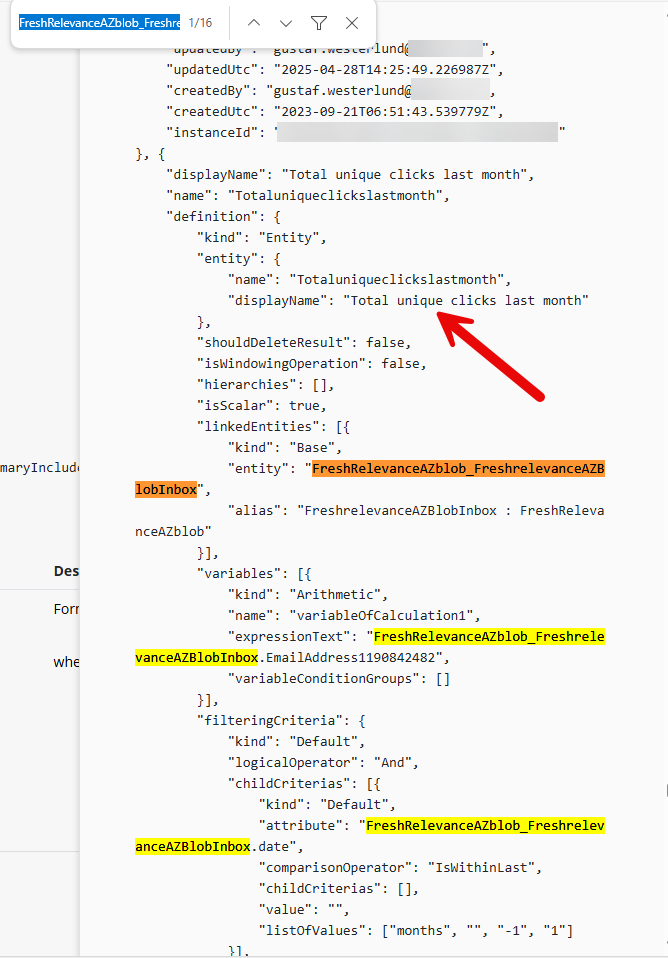
You will now see a long text (json) which is the response from the api call. You can use the built in search in the browser to find all occurances of a datasource. You can use either the Display name or the schema name as both are in the JSON. As you can see below, the Measure “Total unique clicks last month” is one of the measures that has a dependency on the Datasource named “FreshRelevanceAZblob_FreshrelevanceAZBlobInbox”.
Now there are a few options, either remove the measure. This is a good option if you want to fix this quickly or the measure isn’t being used, if it is used there can on the other hand be many dependencies on the measure making it a lot more complex to remove. The other option is hence to just change all dependencies in it to another (Delta) datasource. You will then have to refresh the data source to remove the dependency fully. You can rerun the query by resending it using the button at the very end.
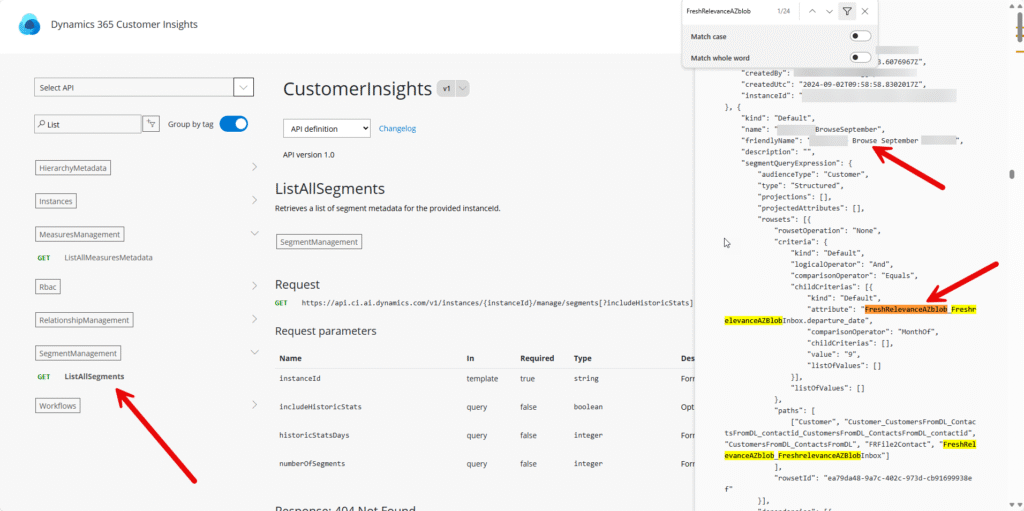
Once you have removed all dependencies on the data source from measures, there might still be dependencies from segments. You can use a similar method as above, but the endpoint you want to use in this case is “ListAllSegments”.
You can still have dependencies left on the datasource, for instance from things externally using the table from the CI-D API. This doesn’t actually block you from removing the data source but whatever you are doing externally will stop working once you have removed the data source. Naturally.
I hope this has helped and thanks a lot to Microsoft Fast Track Architect Ashwini Puranik for pointing me in this direction.
I was recently in charge of a large migration. It all went fine but not without hickups that typically are connected to moving large amounts of data to dataverse. We were using SSIS with Kingswaysoft and ended up using a local SQL database as staging database too. This article will discuss the different lessons learned and give some concrete tips when doing similar migrations.
One of my more popular articles is the article that describes how to optimize the writing of data to Dataverse/CDS. If you are working with migration of large amounts of data, as I will be describing here, I do suggest you have a look at it: https://powerplatform.se/fast-data-management-in-a-limited-cds-world/. I will not discuss those concepts in any detail here but we did use all aspects mentioned in that article.
I recently was in charge of a migration which used CSV-file exports from an old German system (with German field names!) which had many millions of records, in both large tables like “Contact” and “Sales Order”. However, the system we migrated from had a completely different data modell than the one used in Dynamics. For instance, each row describing a “Flight” had to be divided into two rows, one for the outgoing flight and one for the homecoming flight, in the order detail table. We also had to create a lot of related data which was referenced from the “Flight” table, for example location, agent and brand. In other words, there was quite a lot of heavy transformations going on and a lot of logic involved, such as change format on the old data to match the Dataverse model and apply rules to resolve old issues, such as bugs.
Initially we only got a quite small subset of the entire database load, and we started our migration journey by creating all the migration logic in SSIS (which facilitates the script and makes updates easy to handle). The script did include some functions that “joined” rather large tables, both from the CSV files but also related data fetched from the Dataverse based on primary and alternate keys. I was clear with the customer from the very beginning that I wanted a full export with the same amount of data that we could expect in the final migration, mainly for the opportunity to stress-test the SSIS script before the migration to the production environment took place and after a while we got the big files…
…And this was when the excrement hit the wind generator. The afore mentioned lookups just stalled forever. We noted that having a lookup (using Kingswaysoft Premium Lookup) works fine on a computer with 16 GB memory up to a few 100k of records. However, once the data starts reaching 500k and more, it just stalls forever (and don’t even get me start on the sort tools…). Not sure exactly if it would have been possible to fix this by adding more cores and memory, we didn’t try. We hence had to rewrite the script and implement a staging database instead. What we found, is that a dataflow with 1M+ records of lookups will be 100x faster if you import the data into SQL and do a join instead. Lookups still works for smaller tables and I am not against them per se, as they do make the migration simpler. Adding more tables to a migration database will increase complexity, and if you want to add a column in a table, that table do not only has to be added to one SSIS dataflow, but probably a few more. And you also must do an ALTER TABLE in SQL to add the field there too. It is therefore important to have a good mapping set before you start to create the script. And keep the complexity as simple as possible. You can also use SQL tasks in the migration script to update the tables straight after you read them to the staging database per automation, if you need to apply some kind of rules after the read to the staging database, and find it easiest with an SQL query.
The method we used for developing the migration was to first make a “skeleton” migration, based on the target data model. In other words, we started with trying to get a few of the easiest fields, not all, from all tables that was to be involved in the migration – maybe it could be called – model-first-approach, instead of starting with one table, completing this and then moving on to the next. The advantage of the model-first-approach is that you quite early can start some tests on the data, for instance setting up some quantitative test by checking in the source system for the quantities of contacts and then comparing these quantities to the target. The tests can typically be done by other people than the people building the migration scripts and hence this methods scales a lot better than table-by-table-approach. It is also possible for several devs to work in parallell with different tasks. Typically the more senior will build the skeleton and then more junior can add fields by field to each respective table. A negative aspect of this approach is that it requires a lot of re-loads (keep in mind that this was a first migration, so there are no prior data in the Dataverse that we needed to consider) and re-mapping. And it may be easier to “fall out of” the structure, if you just need “to add a little bit here and there”. It is however indeed hard to go table for table, especially with related data. If you already have a lot of live data, you should think about a way to easy identify the migrated data so you can bulk-deleted. And do not forget to engage the client early with raised questions and the mapping to make sure you have understood everything correctly and avoid unnecessary errors.
We also tried to create unique row identities that strictly was based on the source data. This is very useful as that allows for delta-migration, or to continue where we left off in case of a problem. Let’s say for instance that you want to migrate 3 million contacts. If, after 2.1 Million contacts the script breaks for some reason, it is good to be able to continue at 2.1M instead of restarting. In this case we didn’t use modifiedon-date to be able to do a full delta migration logic but it is certainly possible. For this we used the cache-transforms, easily fetch the already migrated data (if any) with the unique and sort out the already migrated data if it matched the key.
Another pattern that we used was that, after creating a specific record, like contact, we reimported the recordid (in this case contactid) together with the legacyid. This allowed us to directly join with this table when later adding tables with dependencies like lookups towards the contact table, could be joined with this mapping table so that we directly got the contactid when querying the related table.
Tips
When migrating from CSV, import them directly as source tables in the staging database. That way, in case you need to fix something, you have a good reference for quantities.
Get an example of the full data load as early as possible. A script that works for a subset might not work at all for the full dataload as was the case for us.
Automate as much as possible. Don’t use any hardcoded values that are environent specific, such as transactioncurrencyid, but rather read these to small tables or to SSIS variables. Use SQL Truncate to remove all data quickly in a table, and make this part of the SSIS script as an SQL task at the appropriate stage.
Always check the quantities. How many rows in source data, how many rows after a match and check if it differs so you very early can identify bugs in your script that might be the reason for dropping rows. For example, you might use a JOIN when you should use an OUTER JOIN. Always check the total number and see if it is what you expect. Watch out for duplicates, and always check so your unique IDs (if you got some from the source data) really are unique and not NULL. Do note that if you have duplicates, that you join on, that will create multiplications. Hence it is possible, after a select-statement with joins to get more records that the initial table.
Define reasonable goals and test cases for the migration. Some examples:
99.9% of all contacts to be migrated correctly. With 1 M records, this means that anything lower than 1000 incorrect migrated contacts/missed, is defined as still ok.
Randomly pick 10-20 records on a base level, like 20 customer, and then compare these in the UAT/Test environment to the source system, as it is seen there. This needs to be done by the business people, so that they can have a say if the migrated data is fine.
Select some filters, like “all customers in Munich” and some other segmentations and compare source system to destination. If there are large amounts of errors, backtrack to the staging database to see where you did loose some records or created too many (not uncommon).
Complete entire transformation to destination tables in the staging db. Then you can move directly from there to dataverse. This is particularly important when moving large quantities of data when managing the data in SSIS can be problematic.
Make sure to have unique identifiers on all tables that preferably can be regenerated from the data. Store these in some “Legacy ID” field. This allows for delta-migration logic, ie. where part of the data is migrated and then the rest later. If you have some issues during one of the dataflows, and it stops on 3 230 234-th record of 6 M, you can continue from there and you don’t have to redo it all. If there is no decent way of getting a legacy id, you can generate classic row numbers by creating an identity column. This will make the migration utilize this, but only within that particular instance and load of the staging db. Hence you must be careful everytime you reload the database.
Utilize the backup-restore functionality of the dataverse environments. Do note that you can make manual backups just before you start migration. If you have a production environment, this will need to be converted to a sandbox environment before you can restore to it. Another option I got from a colleague was to use 3 different environments, with temporary names, and then just rename the final one when done.
Once you have transfered an entire table to the source system, it is typically very useful to have a mapping table, with just the table record id and the legacy id. So for instance, after migrating Contact, read all contacts from dataverse with the contactid and the legacy id. That way, when later migrating “salesorders”, which identify the customer by legacy id, it is easy to just join with this table to get the contactid.
Production environments are faster. Fastest is to ask Microsoft Support to relax throttles on all environments that are used during migration.
Use a VM that is located geographically (or really with low latency and high throughput) to where the environments are hosted. This is a very common recommendation by Kingswaysoft too.
The settings for number of threads and batch size needs to be set based on some factors, namely:
Production/Sandbox
Have throttles been relaxed
Size of payload (ie how many columns) – larger payload -> smaller batches.
Type of action – creates are faster than deletes. Updates are in-between.
I hope these tips can help you along. If you have any comments or you have other experiences in this subject, don’t hesitate to leave a comment.
During this migration and the writing of this article, I had excellent help from my highly intelligent colleague Ebba Linnea Nilsson and it is certainly true that two heads are better than one, and the end result is often a lot better than just the sum of two people. So for my final recommendation, make sure to have a good colleague with you to help you out, as you most probably will run into some issues and having someone to discuss with is really great!
Typically you are not allowed to remove components from the system layer in Dynamics 365/CRM
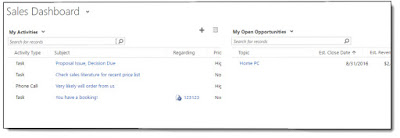
Is this dashboard more pig than horse?
but for some reason this does not apply to dashboards in some earlier versions of Dynamics CRM. It seems this bug has recently been fixed but if you have a version of CRM where this was possible or have been upgraded from this version, you might be missing it. I just tried this in the Online version 8.2.0.798 and in this version it is not possible to delete dashboards but I have managed to in earlier versions.
My friend Jerry Weinstock has blogged about this as well.
One particular dashboard that the system is in dire need of for its mobile features is the “Sales Dashboard” as this is the default dashboard for the mobile and tablet clients. This cannot be changed although the default dashboard can be changed within the mobile client by the user after it has been started. See MSDN for more info in this.
In case you do manage to delete it or it has been deleted, Power Objects blog have described how to restore dashboards from instance with this dashboard in it. In short, create an unmanaged solution in that other instance containing the “Sales Dashboard” and then export and import the solution into the instance missing it.
Before closing the window showing the results, open the log of the import and get the guid of the dashboard and then use the url of another dashboard to insert the GUID into the url to get to the “Sales Dashboard” and change it’s name and/or the label of the the tab to what it typically is in case it doesn’t show up directly.
In case you do not have one, here is a link to an unmanaged solution file (version 8.0) containing just the sales dashboard. SalesDashboard_1_0_0_0_target_CRM_8.0.zip
Seems like that Dynamics 365/CRM doesn’t catch all dependencies for managed solutions. This is how you can find and remove one of the tricky ones I got when uninstalling a managed solution which was:
Unhandled Exception: System.ServiceModel.FaultException`1[[Microsoft.Xrm.Sdk.OrganizationServiceFault, Microsoft.Xrm.Sdk, Version=8.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35]]: During Solution Uninstall of Solution Id [solution-guid], cannot find any instances of the component with Component Id c97cd9d7-a0fa-4ed5-b360-3c2ad998a620 and Component Type 2.Detail: <OrganizationServiceFault xmlns:i=”http://www.w3.org/2001/XMLSchema-instance” xmlns=”http://schemas.microsoft.com/xrm/2011/Contracts”> <ErrorCode>-2147220970</ErrorCode> <ErrorDetails xmlns:d2p1=”http://schemas.datacontract.org/2004/07/System.Collections.Generic” /> <Message>During Solution Uninstall of Solution Id [solution-guid], cannot find any instances of the component with Component Id c97cd9d7-a0fa-4ed5-b360-3c2ad998a620 and Component Type 2.</Message> <Timestamp>2017-03-06T13:06:54.6280227Z</Timestamp> <ExceptionSource i:nil=”true” /> <InnerFault i:nil=”true” /> <OriginalException i:nil=”true” /> <TraceText i:nil=”true” /> </OrganizationServiceFault>
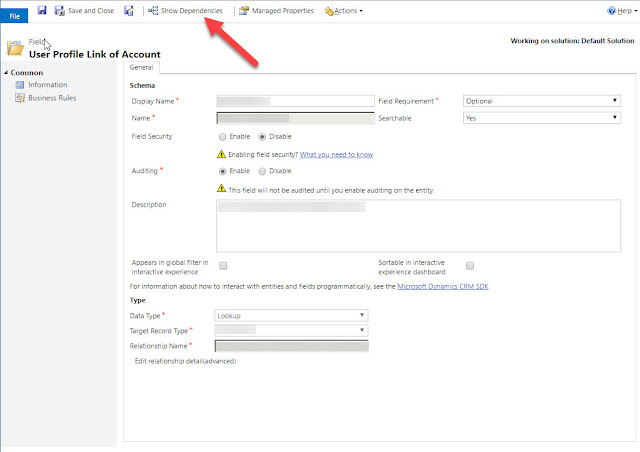
After some thinking I figured that this was probably a reference to an attribute (Component type = 2) with the Guid = c97cd9d7-a0fa-4ed5-b360-3c2ad998a620 so I opened another attribute and then cut-n-pasted the url. And it seemed that you didn’t have to worry about the entity guid:
Change <onlineorgname> to your org, and <globalcrmcenter> to the crm-subdomain you are using, which for EMEA is crm4.
You will then see the field editor, and can then show the dependencies of the field and remove all of them manually to make sure they are not bothering the Solution uninstall. After that “publish all” and retry removing the solution.
So, time to try something new. I recorded a small screencast with SnagIt to show how easy it is to enable the awsome new feature Editable grids in Dynamics 365. So, please have a look and let me know what you think!
And yes, I know I keep saying CRM, and Dynamics CRM. I have been working with this product for more than 11 years now. It’s going to take some time for this old dog to sit.




Recent Comments